

OLAP引擎Clickhouse在abtest场景下的优化
source link: https://my.oschina.net/u/4471526/blog/5119234
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
OLAP引擎Clickhouse在abtest场景下的优化 - 好未来技术的个人空间 - OSCHINA - 中文开源技术交流社区
A/B测定义
A/B 测试以数据驱动为导向,可以实现灵活的流量切分,使得同一产品的不同版本能同时在线,通过记录和分析用户对不同版本产生的行为数据,得到效果对比,最大程度地保证结果的科学性和准确性,从而帮助人们进行科学的产品决策。
基于用户行为数据计算不同版本的指标数据,是评估实验结果的唯一依据。
指标产品设计
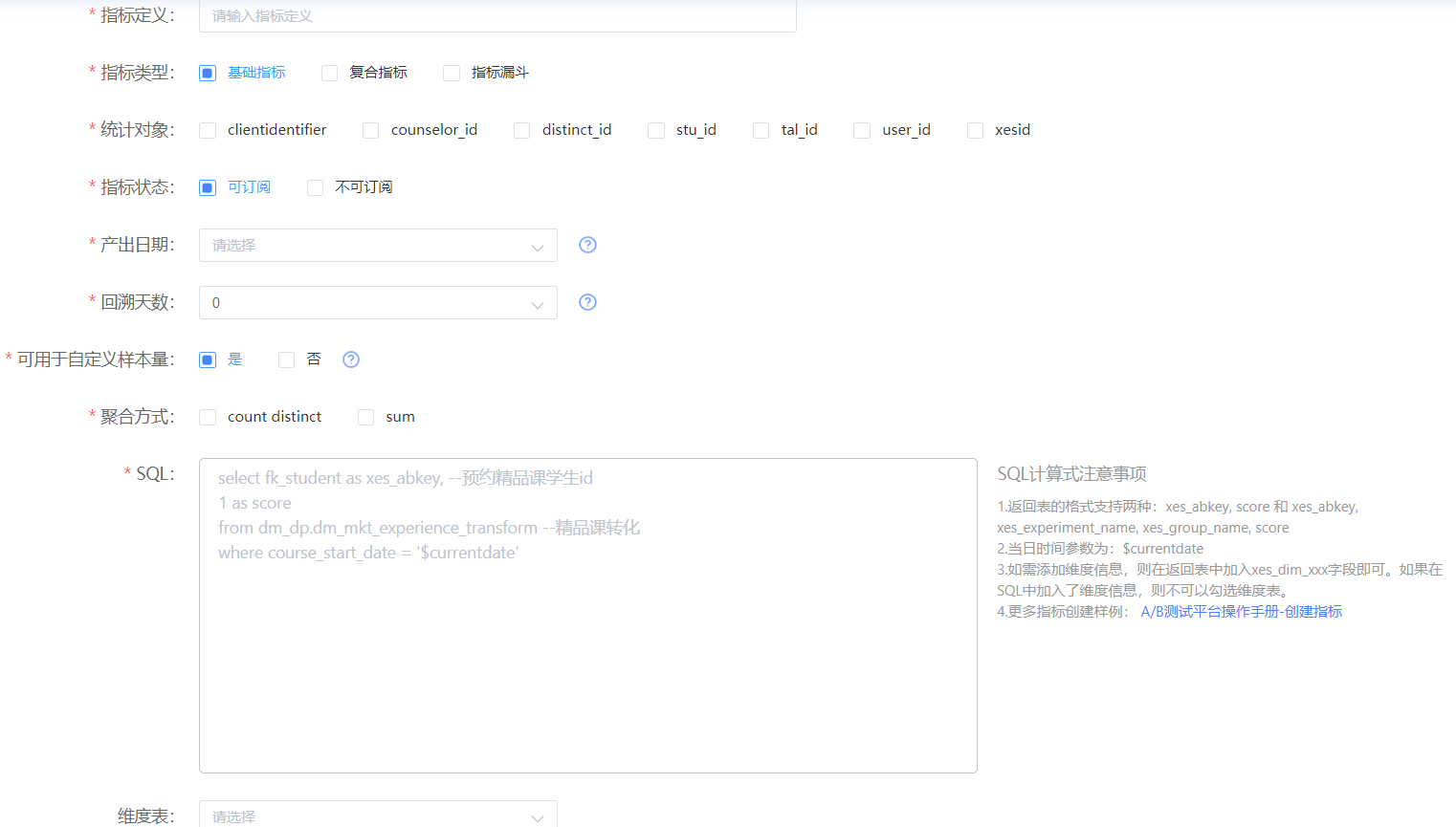
图1. 新增指标
指标系统产品设计上采用了指标注册的方式,用户可以在自己的业务域和业务线下进行指标注册,注册需要指定指标计算公式(SQL),指标SQL必须遵守SQL模板,并支持自定义维度(自动注册维度/关联维表)。分析层面上,用户可以查看固定与预计算好的指标,也可以进行指标的多维分析。
产品需求上,需要计算当日以及累计(实验开始时间~前一天)的样本、指标。
指标技术架构
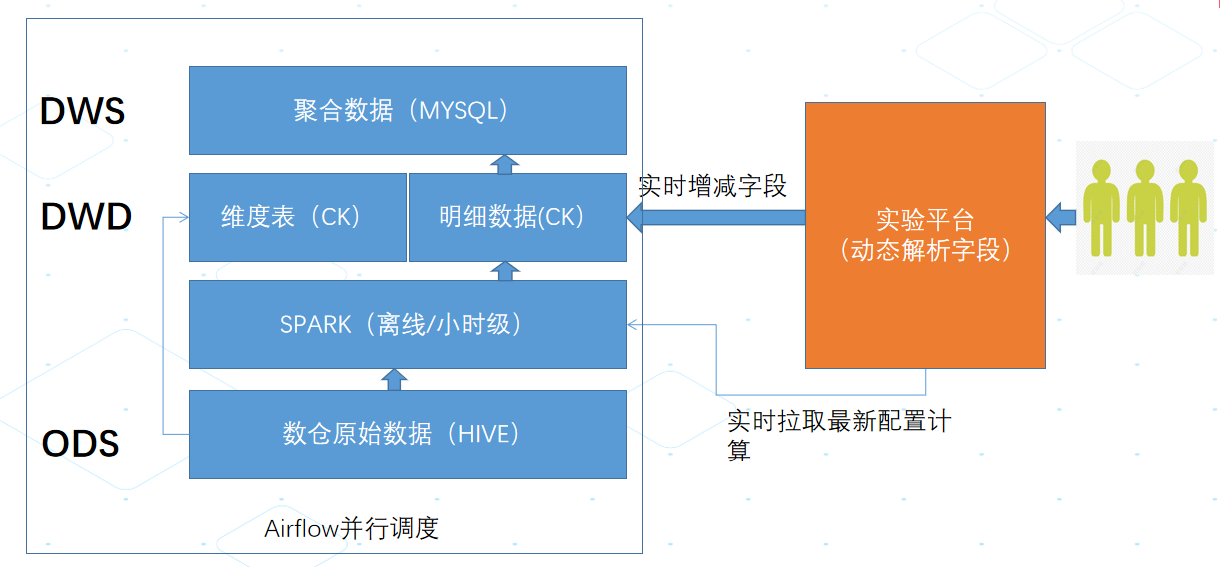
图2. 指标设计架构图
多个实验采取并行计算,单个实验多个指标采取串行计算。
单个实验需要计算的数据如下:
图3. 实验计算数据
指标计算的特点在于:对于每一个实验,需要先计算样本,指标是架设在样本之上的指标,基础指标P值的计算需要依赖样本和指标,复合指标P值的计算需要基于分母重建样本。对于每个实验来讲,样本可能是变化的,用户可以自定义样本,也可以选择分流服务日志作为默认兜底样本。
指标计算优化
阶段一:引擎和架构优化
计算引擎Spark:基于性能和成熟度的考量,选择Spark作为核心计算引擎,它相对Hive的优势就不赘述了。
OLAP引擎Clickhouse:指标分析需要基于明细数据进行多维复杂分析,目前的成熟引擎都可以满足,选择CK的重要原因是:1> CK的性能和成熟度已经得到验证 2> 内部有CK集群,方便我们直接使用。
计算方式:多个实验并行计算,单个实验内部的多指标串行计算。实验之间关联性较小,并行计算时合适的。单个实验内部,多个指标关联性较强,如复合指标,需要先计算基础指标,才可以复合计算,串行计算是合理的。在实现上的话,是通过调度shell脚本动态循环实验完成的。
实现方式:单个实验的计算是通过一个通用的Spark程序来完成的,离线调度任务起来的时候,读取实验指标的配置,先算明细,再算指标值。
AB平台上线初期,实验和指标数量较少(10+实验,50+指标),基本可以满足需求,整体计算时间大约是2~3个小时。
平台在运行半年之后,随着实验数量的增多,整个时间延长到了5~6个小时,并行度已经增加到10,单个任务的资源增加到100core, 800G内存,怎么优化?
阶段二:计算模型优化
我们抓取一个典型的广告实验,打印每个指标各个阶段的消耗时长,经过对计算的每个过程执行时间分析,发现花在样本和指标累计值计算上的时间特别长。AB指标的累计值计算规则是从>=实验开始运行日期<=计算日期,指标定义sql会要求必须输入时间字段,程序会自动进行判断和日期的处理,如果一个实验运行了3个月,那需要扫描3个月的数据进行计算,数据量较大会造成计算效率差、计算时间很长。
我们统计了3个月内已关闭实验的运行时长: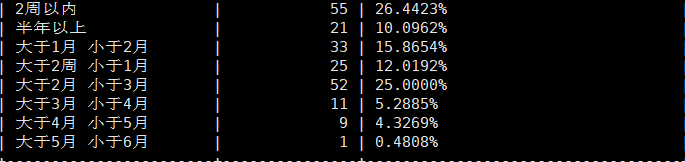
图4. 实验运行时长统计
从上图看到,大于1个月的实验占总实验数接近60%,比例是比较高的。
如何优化累计计算呢?
之前的计算模型: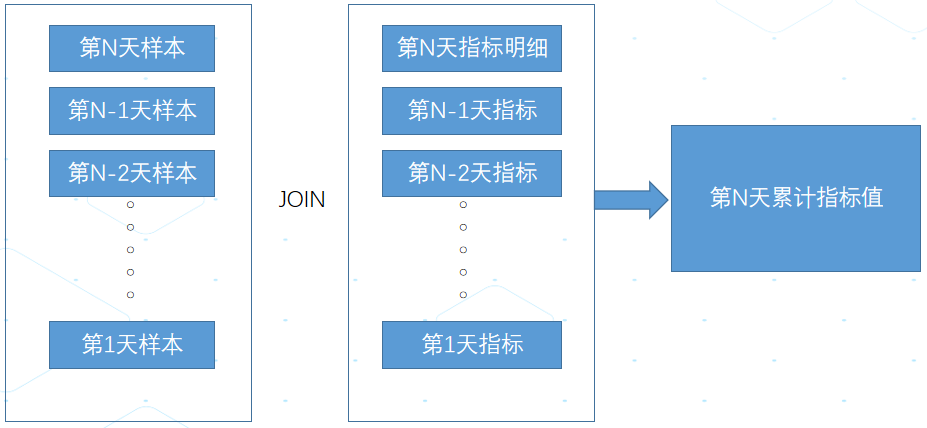
图5. 原计算模型
这个计算模型的优点是相对独立,可随意计算任意一个日期的累计值;缺点是1>需要扫描的数据量比较大2>计算不够准确:将样本发生时间在指标时间之后的数据也计算进去了,结果会出现轻微误差,举例来讲:5月1号用户发生了转化,但是5月2号用户才参加实验,此算法会把这样的数据算做实验带来的转化。
优化后的模型: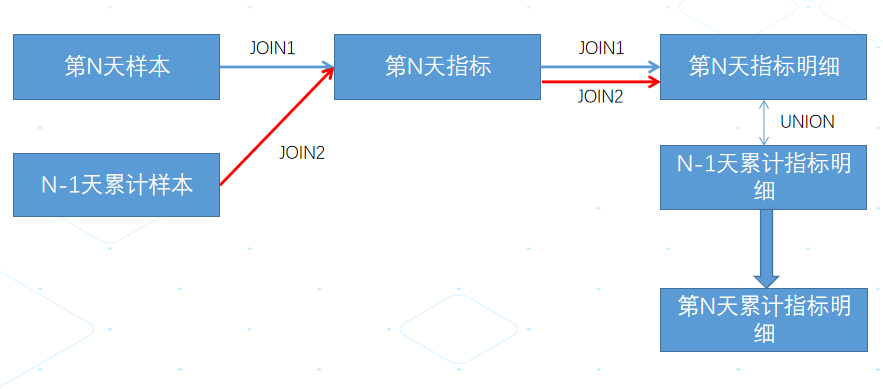
图6. 新计算模型
此计算模型的优点:1>累计计算的性能有了大幅度的提升,不再随着时间的增长,数据计算越来越慢的情况出现;2>计算结果更加准确。缺点是:第N天的累计计算依赖于第N-1天的累计明细,复杂程度提升了。
经过此优化之后,每个指标的计算时间相对可控,不再出现时间特别长的实验指标了。整体的计算时长保持在3个小时左右。
阶段三:率指标批量优化
经过阶段二的优化之后,整体满足50+实验,200+指标的计算,单个实验(5个指标)的整体计算时长可稳定在40分钟左右。
好景不长,指标计算又面临新挑战:年初网校资源管控平台整体对接AB之后,实验数直线上升,实验数达到每天150+,指标数600+,整体的计算时间长达10个小时,如何优化?
通过对实验和指标数据进行分析,发现通过从资源管控平台过来的实验,默认都勾选了固定的几个指标,相当于同一个指标在N个实验里出现,那是否可以对单个指标批量计算实验数据呢?
AB指标计算在设计时之所以会设计成单个实验串行,多个实验并行的方式,原因是每个实验允许用户自定义样本,未自定义才会使用平台分流日志兜底。AB平台适配了多种类型的指标,批量计算适合的指标是:指定定义SQL中本身包含了实验名和组名,并且属于基础率指标,即无需和样本进行关联。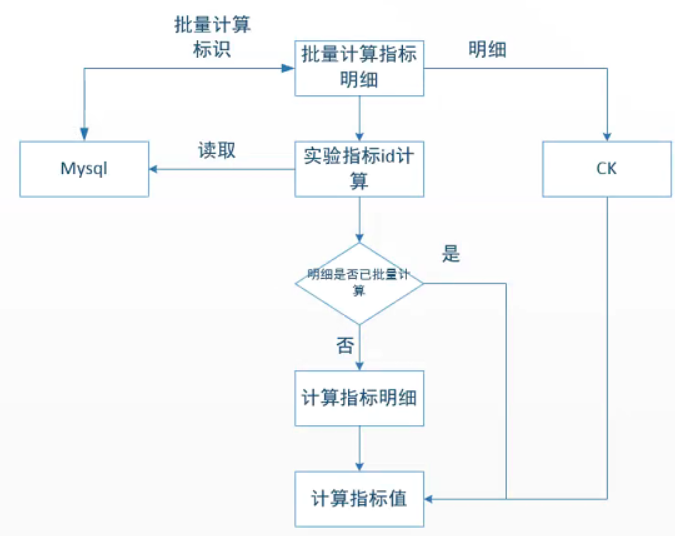
图7. 率指标优化方案
此方案上线之后,平台大部分的实验都可以基于此方案进行批量计算,加快执行效率。整体指标计算的时间缩短到5个小时,提升了一倍的性能。
阶段四:均值指标批量优化
阶段三是针对率指标的批量优化,但是系统中存在不少的均值指标,被多个实验勾选,部分指标计算比较复杂,即使计算单天的数据,计算时间也需要半个小时,如:
图8. 指标SQL
这个是指标SQL,实际计算当中还需要再关联样本,计算基于样本的均值明细和均值,整个计算会变得比较复杂,单次计算时间大约在半个小时。还能怎么优化呢?
我们采用spark的checkpoint机制,将首次计算的明细数据通过checkpoint缓存起来,这样计算均值、p值、置信区间就可以直接用缓存的明细数据进行计算。
实施之后,发现整体的计算时长有降低,但是由于checkpoint会涉及到把数据写入hdfs,无形中将spark退回到了Hive的方式,整体有提升,但是不是很明显。
能否像阶段三那边,批量计算缓存到CK呢? 是可以的,模型会复杂一些。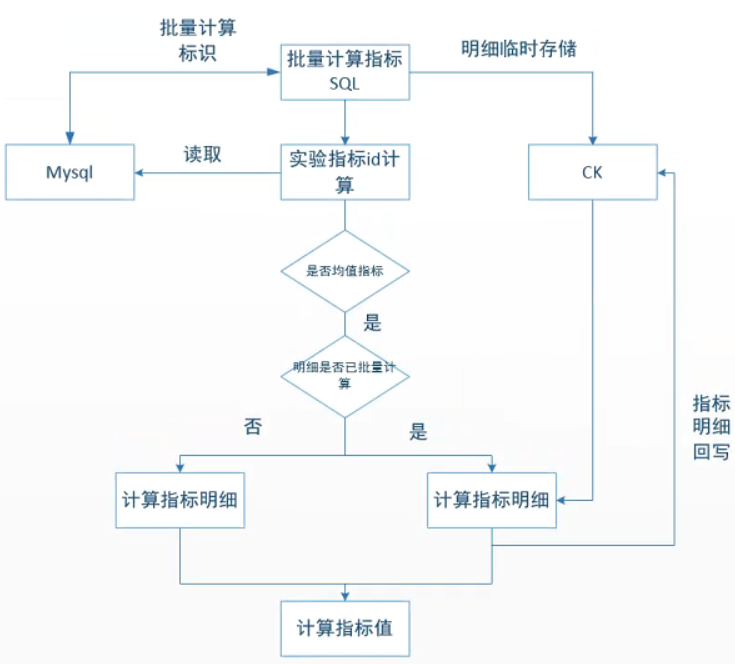
图9. 均值指标优化方案
此方案的核心在于:指标sql会先计算得到临时明细数据,在计算指标明细时,直接从CK中获取,依赖于Spark的RDD跨数据源的能力,实现计算时的动态选取,最终明细数据再回写CK。
AB测指标计算优化之后,150+实验、600+指标,整体的计算时长保持在2~3个小时,最重要的是随着实验和指标的增加,整体的计算时长增加是可控的,不会几何级数的增长,达到了我们优化的效果。
想要了解更多关于教育行业的技术干货可扫码下方二维码加入好未来官方交流群

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK