

recommenderlab 包实现电影评分预测
source link: https://cosx.org/2014/02/recommenderlab-packages/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
recommenderlab 是 R 语言非常强大的包,能帮助使用者针对评分数据或者 0-1(不喜欢 / 喜欢) 二分数据开发和测试推荐算法,本文就是利用该包对于 movielens 的电影评分数据进行预测和推荐,会对比基于用户的协同过滤和基于项的协同过滤在推荐效果上的差别。
1 获取电影数据
电影数据来源于 http://grouplens.org/datasets/movielens/ 网站,本文分析的数据是 MovieLens 100k,总共有 100,000 个评分,来自 1000 位用户对 1700 部电影的评价。
2 数据准备和清理
设置好工程路径后,可用读入数据,注意数据的格式,第一列是 user id,第二列是 item id,第三列是 rating,第四列是时间戳,时间戳这里用不到,可去掉。
ml100k <- read.table("u.data", header = F, stringsAsFactors = T)
head(ml100k)
V1 V2 V3 V4
1 196 242 3 881250949
2 186 302 3 891717742
3 22 377 1 878887116
ml100k <- ml100k[, -4]
可以简单看下 rating 的分布情况
prop.table(table(ml100k[, 3]))
1 2 3 4 5
0.06106870 0.12977099 0.41984733 0.32061069 0.06870229
summary(ml100k[, 3])
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.000 3.000 3.000 3.206 4.000 5.000 812
可以看出,3 星和 4 星的数量最多,接近总数的 75%,1 星和 5 星的数量最少,和预期的一致。数据格式和我们想要的行为用户,列为项目的 ratingMatrix 还有很大的差距,对此可以使用 reshape 包的 cast() 进行转换,注意转换后的缺失值默认为 NA。
library(reshape)
ml100k <- cast(ml100k, V1 ~ V2, value = "V3")
ml.useritem[1:3, 1:6]
1 2 3 4 5 6
1 5 3 4 3 3 5
2 4 NA NA NA NA NA
3 NA NA NA NA NA NA
到此,把数据整理成 ratingMatrix,接下来利用 recommenderlab 处理数据。
3 recommenderlab 处理数据
在用 recommenderlab 处理数据之前,需将数据转换为 realRatingMatrix 类型,这是 recommenderlab 包中专门针对 1-5 star 的一个新类,需要从 matrix 转换得到。上文获得的 ml.useritem 有两个类属性,其中 cast_df 是不能直接转换为 matrix 的,因此需要去掉这个类属性,只保留 data.frame
class(ml.useritem)
[1] "cast_df" "data.frame"
class(ml.useritem) <- "data.frame" ##只保留data.frame的类属性
ml.useritem <- as.matrix(ml.useritem)
ml.ratingMatrix <- as(ml.useritem, "realRatingMatrix") ##转换为realRatingMatrix
ml.ratingMatrix
943 x 1682 rating matrix of class ‘realRatingMatrix’ with 100000 ratings.
ml.ratingMatrix 是可以用 recommenderlab 进行处理的 realRatingMatrix,943 是 user 数,1682 指的是 item 数, realRatingMatrix 可以很方便地转换为 matrix 和 list
as(ml.ratingMatrix , "matrix")[1:3, 1:10]
1 2 3 4 5 6 7 8 9 10
1 5 3 4 3 3 5 4 1 5 3
2 4 NA NA NA NA NA NA NA NA 2
3 NA NA NA NA NA NA NA NA NA NA
as(ml.ratingMatrix , "list")[[1]][1:10]
1 2 3 4 5 6 7 8 9 10
5 3 4 3 3 5 4 1 5 3
另外,recommenderlab 包中有提供用于归一化的函数 normalize(),默认是均值归一化 x – mean;建立推荐模型的函数,里面有归一化处理的,在此不必单独进行归一化。
4 recommender 简单介绍
在建模之前可以先看下针对 realRatingMatrix,recommederlab 提供了哪些推荐技术——一共有 6 种,我们会用到其中的三种:random(随机推荐),ubcf(基于用户协同过滤),ibcf(基于项目协同过滤)
recommenderRegistry$get_entries(dataType = "realRatingMatrix")
$IBCF_realRatingMatrix
Recommender method: IBCF ##基于项目协同过滤
Description: Recommender based on item-based collaborative filtering (real data).
Parameters:
k method normalize normalize_sim_matrix alpha na_as_zero minRating
1 30 Cosine center FALSE 0.5 FALSE NA
$PCA_realRatingMatrix ##主成份分析
Recommender method: PCA
Description: Recommender based on PCA approximation (real data).
Parameters:
categories method normalize normalize_sim_matrix alpha na_as_zero minRating
1 20 Cosine center FALSE 0.5 FALSE NA
$POPULAR_realRatingMatrix ##基于流行度推荐
Recommender method: POPULAR
Description: Recommender based on item popularity (real data).
Parameters: None
$RANDOM_realRatingMatrix ##随机推荐
Recommender method: RANDOM
Description: Produce random recommendations (real ratings).
Parameters: None
$SVD_realRatingMatrix ##奇异值分解
Recommender method: SVD
Description: Recommender based on SVD approximation (real data).
Parameters:
categories method normalize normalize_sim_matrix alpha treat_na minRating
1 50 Cosine center FALSE 0.5 median NA
$UBCF_realRatingMatrix ##基于用户协同过滤
Recommender method: UBCF
Description: Recommender based on user-based collaborative filtering (real data).
Parameters:
method nn sample normalize minRating
1 cosine 25 FALSE center NA
以 IBCF 为例简单介绍参数的含义
K:取多少个最相似的 item,默认为 30
method:相似度算法,默认采用余弦相似算法 cosine
Normalize:采用何种归一化算法,默认均值归一化 x – mean
normalizesimmatrix:是否对相似矩阵归一化,默认为否
alpha:alpha 参数值,默认为 0.5
naaszero:是否将 NA 作为 0,默认为否
minRating:最小评分,默认不设置
这些参数均可在建立模型时设置,本文全部采用默认参数。
5 建立推荐模型
recommender() 是 recommenderlab 包中用于建立模型的函数,用法也相当简单,注意在调用 recommender() 之前需给矩阵的所有列按照 itemlabels 进行列命名。
colnames(ml.ratingMatrix) <- paste("M", 1:1682, sep = "")
as(ml.ratingMatrix[1,1:10], "list")
$`1`
M1 M2 M3 M4 M5 M6 M7 M8 M9 M10
5 3 4 3 3 5 4 1 5 3
##【警告】在建立推荐模型之前一定要给item按照itemLabels进行命名,否则会有如下错误
##Error in validObject(.Object) :
## invalid class “topNList” object: invalid object for slot "itemLabels" in class "topNList": got class "NULL", should be or extend class "character"
ml.recommModel <- Recommender(ml.ratingMatrix[1:800], method = "IBCF")
ml.recommModel
Recommender of type ‘POPULAR’ for ‘realRatingMatrix’
learned using 800 users.
模型建立以后,就可以用来进行预测和推荐了。与其他很多模型类似,我们将使用 predict() 函数,这里分别给 801-803 三个用户进行推荐。predict() 函数有一个 type 参数,可用来设置是 Top-N 推荐还是评分预测,默认是 Top-N 推荐。
##TopN推荐,n = 5 表示Top5推荐
ml.predict1 <- predict(ml.recommModel, ml.ratingMatrix[801:803], n = 5)
ml.predict1
Recommendations as ‘topNList’ with n = 5 for 3 users.
as( ml.predict1, "list") ##显示三个用户的Top3推荐列表
[[1]]
[1] "M50" "M100" "M127" "M98" "M174"
[[2]]
[1] "M50" "M100" "M127" "M174" "M313"
[[3]]
[1] "M50" "M100" "M127" "M98" "M174"
##用户对item的评分预测
ml.predict2 <- predict(ml.recommModel, ml.ratingMatrix[801:803], type = "ratings")
ml.predict2
## 查看三个用于对M1-6的预测评分
## 注意:实际的预测评分还要在此基础上加上用户的平均评分
as(ml.predict2, "matrix")[1:3, 1:6]
M1 M2 M3 M4 M5 M6
801 0.2909692 -0.2749699 -0.350463 -0.02231146 -0.2300878 0.2049403
802 0.2909692 -0.2749699 -0.350463 -0.02231146 -0.2300878 0.2049403
803 0.2909692 -0.2749699 -0.350463 -0.02231146 -0.2300878 0.2049403
6 模型的评估
本文只考虑评分预测模型的评估,对于 Top-N 推荐模型请查看后面的参考资料,对于评分预测模型的评估,最经典的参数是 RMSE(均平方根误差)
rmse <- function(actuals, predicts) {
sqrt(mean((actuals - predicts)^2, na.rm = T))
}
幸运的是,recommenderlab 包提供了专门的评估方案,对应的函数是 evaluationScheme(),能够设置采用 n 折交叉验证还是简单的训练集 / 测试集分开验证。本文采用后一种方法,即将数据集简单分为训练集和测试集,在训练集训练模型,然后在测试集上评估。
model.eval <- evaluationScheme(ml.ratingMatrix[1:943], method = "split", train = 0.9, given = 15, goodRating = 5)
model.eval
Evaluation scheme with 15 items given
Method: ‘split’ with 1 run(s).
Training set proportion: 0.900
Good ratings: >=5.000000
Data set: 943 x 1682 rating matrix of class ‘realRatingMatrix’ with 100000 ratings.
##分别用RANDOM、UBCF、IBCF建立预测模型
model.random <- Recommender(getData(model.eval, "train"), method = "RANDOM")
model.ubcf <- Recommender(getData(model.eval, "train"), method = "UBCF")
model.ibcf <- Recommender(getData(model.eval, "train"), method = "IBCF")
##分别根据每个模型预测评分
predict.random <- predict(model.random, getData(model.eval, "known"), type = "ratings")
predict.ubcf <- predict(model.ubcf, getData(model.eval, "known"), type = "ratings")
predict.ibcf <- predict(model.ibcf, getData(model.eval, "known"), type = "ratings")
这里简单介绍,数据集是如何划分的。其实很简单,对于用户没有评分过的项目,是没法进行模型评估的,因为预测值没有参照对象。getData 的参数 given 便是来设置用于预测的项目数量。
 接下来计算 RMSE,对比三个模型的评估参数,
接下来计算 RMSE,对比三个模型的评估参数,calcPredictionError() 函数可以计算出 MAE(绝对值均方误差)、MSE 和 RMSE。
error <- rbind(
calcPredictionError(predict.random, getData(model.eval, "unknown")),
calcPredictionError(predict.ubcf, getData(model.eval, "unknown")),
calcPredictionError(predict.ibcf, getData(model.eval, "unknown")))
rownames(error) <- c("RANDOM", "UBCF", "IBCF")
error
MAE MSE RMSE
RANDOM 1.7267304 4.486820 2.118211
UBCF 0.8254453 1.062409 1.030732
IBCF 0.8444152 1.333968 1.154976
为了更好地说明 RMSE 与训练 / 测试比、given 等参数的关系,我们可以进行多组的比较。
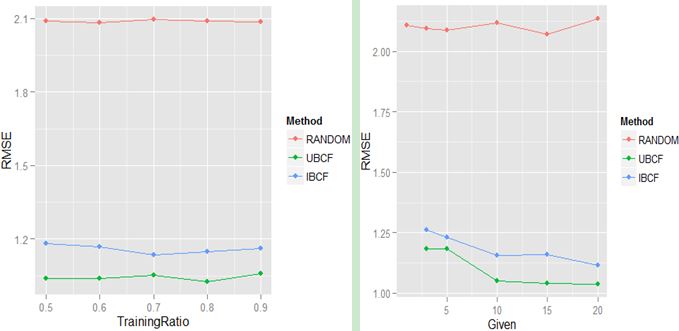 从上面的两张图可以得出如下结论:
从上面的两张图可以得出如下结论:
- 训练 / 测试比对 RMSE 没什么影响,并不是训练集比重越大 RMSE 越小,因此在实际过程中可适当降低训练集的比例,减少建立模型所需时间;
given值对协同过滤的推荐系统影响很大,given越大(用于预测项目数量)RMSE 越小,当然这里最大的given值为 20,在 [1, 20] 范围内,显然given = 20是最优的;- 基于用户的协同过滤表现好,随机推荐最差,另外,项目的数量超过 2 倍的用户数,因此无论从降低 RMSE 还是提高模型性能来说,UBCF 都是最好的选择。有兴趣的童鞋还可以尝试分析近邻数 K、相似度算法和 RMSE 的关系。
在《Recommender system handbook》的 4.2.5 节,很详细对比了 IBCF 和 UBCF,再结合以上的数据,可以很好地理解为什么在这个案例中 UBCF 要明显优于 IBCF。
7 参考资料
[1] Recommender system handbook
[2] Item-Based Collaborative Filtering Recommendation Algorithms
[3] recommenderlab: A Framework for Developing and Testing Recommendation Algorithms
[4] http://cran.r-project.org/package=recommenderlab
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:[email protected]),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK