

DuckDB: Row-Group Based Storage
source link: https://zhuanlan.zhihu.com/p/382131436
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

DuckDB: Row-Group Based Storage
SingleFile
DuckDB 支持内存型和持久化型两种工作模式。
其中,内存型不持久化数据,采用 InMemoryBlockManager 来管理数据,后面不讨论内存型的数据存储。
DuckDB 采用 SingleFileBlockManager 来管理外存上的数据。看这个名字就可以猜到,DuckDB 把所有数据都保存在了一个文件中。
下面,我们称这个文件为 SingleFile。
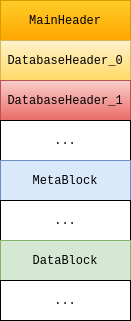
SingleFile 的基本结构
DuckDB 把 SingleFile 的数据划分成定长块,包括两大类:header 和 block。
Header
- Header 目前有 3 个,包括 1 个 MainHeader 和 2 个 DatabaseHeader,每个固定大小为 4KB(FILE_HEADER_SIZE)。
MainHeader保存了magic_bytes、version_number和flag 列表,主要用来做一些版本校验,对总体逻辑没什么影响,暂且可以忽略。DatabaseHeader的核心是保存了meta_block的 id,后续会从这个meta_block开始读取整个实例的元数据(表结构等)。
Block
- Block 固定长度为 256KB(BLOCK_ALLOC_SIZE),其中前 8 个字节(BLOCK_HEADER_SIZE)是 checksums。
- Block 大体上可以分成两种,这里简单称之为 MetaBlock 和 DataBlock。
MetaBlock
- MetaBlock 除去 checksums 部分的前 8 个字节是
next_block_id—— 相关的 MetaBlock 通过这个字段串连在一起——比如,表结构的信息很多,超过 256KB,一个 block 存不下,需要两个以上的 block,此时就用这个 next_block_id 将这些 block 串连成一个链表。 - MetaBlock 是通过 MetaBlockReader/MetaBlockWriter 进行读写的,
next_block_id的细节也被封装在这里面。
MetaBlock 组成的链表
- MetaBlock 可以分成两种,这里也简单称之为 Schema MetaBlock 和 TableData MetaBlock。
- Schema MetaBlock 保存了表结构等信息。
- TableData MetaBlock 保存了对应表的数据的所有 block_id。
DatabaseHeader中的meta_block_id就是 Schema MetaBlock 的第一个 block_id。DuckDB 元数据的加载就是从这个 block 开始的,代码在 CheckPointManager::LoadFromStorage。
Schema MetaBlock
Schema MetaBlock 的逻辑结构
- 最前面是 schema count,类型为 uint32,占用 4 字节。
- 后面跟一个 schema 列表。DuckDB 中的一个 schema 其实就是 MySQL 中的一个 database。具体可以参考 DuckDB 的官方文档:Create Schema。
CheckpointManager::ReadSchema 函数展示了如何读取、解析一个 schema。一个 schema 的逻辑结构如下:
- Sequence 是 DuckDB 提供的一个创建 sequence number 生成器的功能,具体可以参考Create Sequence。
- Table 就是数据库常说的表,具体可以参考 Create Table。
- View 就是数据库中常说的视图。DuckDB 的视图是逻辑视图,具体可以参考 Create View。
- Macro 是用户自定义的(类似)存储过程的东西,具体可以参考 Create Macro。
Sequence、View 和 Macro 都只有元数据,其读取相对简单,感兴趣的话,可以参考下面的代码:
重点看看 ReadTable。除了表结构本身的元数据,还会涉及加载指向实际数据的”指针“,相对复杂一些。
一个 table 的元数据如下:
- ColumnDefinition 是表结构的列定义,主要有列名 name、列索引 oid、列类型 type 和默认值 defaule_value。
- Constraint 列表是 table 定义的一些限制。DuckDB 目前支持 NOT NULL、CHECK、UNIQUE、FOREIGN KEY 四种 constraints。
- block_id 指向了这个 table 的第一个 TableData MetaBlock。
- offset 是指在这个 TableData MetaBlock 上的偏移。
TableData MetaBlock
TableDataReader::ReadTableData 函数负责读取、解析 TableData MetaBlock 。
TableData MetaBlock 的逻辑结构
- 通过 BaseStatistics::Deserialize 反序列化整个表的每一列的统计信息,不同数据类型的统计信息可能不太一样,具体可以看这个函数。
- 通过 RowGroup::Deserialize 反序列化每一个 RowGroup 的信息。
DuckDB 将一个表的数据按行划分成一个个 group,称之为 RowGroup。RowGroup 内部的数据按列进行存储。目前 DuckDB 将 122880 行数据划分为一个 RowGroup。
RowGroup 的逻辑结构
- row_start 是这个 RowGroup 第一行数据的 ID。
- tuple_count 是这个 RowGroup 的行数。
- 接下来是这个 RowGroup 中每一列的统计信息,一般都有保存最大、最小值,可以在查询的时候起到比较粗粒度的过滤作用。
- 一个 BlockPointer 指向这个 RowGroup 中一列数据的第一个 block。
- VersionNode 保存了这个 RowGroup 中的数据的 delete 信息。
小结
本文介绍了 DuckDB 底层存储的数据基本格式 —— Row-Group Based Storage。这个存储格式其实是 DuckDB 在几天前(2020 年 6 月 14 日)发布的 0.2.7 版本时才引入的,之前的存储格式是存列存的,具体可以看这个 DuckDB 的 PR/1808: Row-Group Based Storage。
DuckDB 这种将数据划分成一块一块的方式,再通过 block_id 串连起来的方式,感觉如果同一个表的数据分得比较散,可能会造成大量扫描数据的时候局部性不佳?
不过,这种分块方式,感觉天然很适合接入 S3 这类对象存储。
关于 DuckDB 的存储的问题还有很多,比如,索引的实现、Update/Delete 的实现等,本文也还没触及到。
Recommend
-
66
DuckDB:开篇FOCUS做数据库的。公众号:coredump
-
14
Get an id row with MAX and MIN in days from a GROUP BY advertisements I don't have any idea how i can get this information. This is my...
-
4
2021-06-25Hannes Mühleisen and Mark Raasveldt Querying Parquet with Precision using DuckDB TLDR: DuckDB, a free and open source analytical data management system, can run SQL queries directly on Parquet f...
-
14
用 Python 的 DuckDB 下 SQL 指令翻 Parquet 的資料 在「Querying Parquet using DuckDB」這邊看到 DuckDB 這個東西,...
-
13
2021-08-27Laurens Kuiper Fastest table sort in the West - Redesigning DuckDB's sort TLDR: DuckDB, a free and Open-Source analytical data management system, has a new highly efficient parallel sorting impl...
-
9
Comparing SQLite, DuckDB and Arrow with UN Trade Data Fri, Aug 27, 2021 Context This is not a competition, is just to show how to use the hardware with relative efficiency, being the idea is to show someth...
-
13
2021-10-29André Kohn and Dominik Moritz DuckDB-Wasm: Efficient Analytical SQL in the Browser TLDR: DuckDB-Wasm is an in-process analytical SQL database for the browser. It is powered by WebAssembly, spea...
-
12
DuckDB-Wasm:浏览器中的高效分析 SQLDuckDB-Wasm 是一个用于浏览器的进程内分析 SQL 数据库。它由 WebAssembly 提供支持,可以流利地使用 Arrow 语言,读取由文件系统 API 或 HTTP 请求支持的 Parquet、CSV 和 JSON 文件,并且已经过 Chrome、Firefox、Safari...
-
6
2022-05-04Alex Monahan Friendlier SQL with DuckDB An elega...
-
5
Notes on the SQLite DuckDB paper SQLite: Past, Present, and Future is a newly published paper authored by Kevin P. Gaff...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK