

再要你命3000手机刷单词的修正
source link: https://iphyer.github.io/blog/2014/10/21/3k-word/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

再要你命3000手机刷单词的修正
前段时间备考GRE的时候,陈琦老师的再要你命3000非常好,我也不断在刷单词,最后发现几个比较好的方法,一个是Excel版本背单词,这个就是专注于每个单词的记忆效率,看到一个单词就回想自己是不是记得。另外一个就是听着录音不断刷遍数,这个要求是快速大量,最后我找到的音频文件可以实现3.5小时过一遍3k的程度。基本上非常好。
这篇文章具体介绍一下。
Excel方法
具体的方法是:
使用时,左手放在键盘上的“1”上,将光标放在最左边“A”列上,右手放在键盘上的方向键上,按“下”键,屏幕中出现一个单词,如果知道意思,继续按“下”键,看下一个词,如果不会,左手按“1”,进行标注,并且右手按向“右”键2次,察看中文解释。8、过完一遍后,将“A”列选中,然后选择“数据”里面的“筛选”,按照标注“1”进行筛选,然后把“1”的拷贝到本excel文件的”Sheet2”,再一次背诵。刚开始,“1”可能很多,不要紧,一定要快,迅速找出自己不熟的,集中记忆。信心倍增!第二遍的时候,可以对“1”进行背诵,把不会的标记为“2”,如此类推。
可以在这里下载到:再要你命三千excel背诵法.xlsx
这个版本的好处就是已经设置好了单元格的格式,可以非常方便的实现每次只过一个单词,而且中文英文分开的目的。适合每天固定个时间复习回忆。
音频手机快速刷单词
这个最后我找到的是这个帖子刷词神器《要你命3000手机刷词版》下载的PDF版本文本文件和这个帖子自制“再要你命3000”音频,只有英文和中文的音频文件。
刷词神器《要你命3000手机刷词版》下载的PDF做的非常大和精致,适合手机阅读。
但是有几个缺点,第一是P410有笔误,nicety写成了nibble,这样nibble写了两遍。同时最后的List28到List31是乱序版本,这与我找到的音频文件不匹配。前面以我自己的观察大致还是符合的。
自制“再要你命3000”音频,只有英文和中文的音频文件制作得非常清楚,同时比琦叔找以前学生和新东方老师录的音频来说更加纯正和快速。当然因为是机器合成所以中文有点古怪。
为什么要听录音,GRE又不考听力。
事实上,作为一个语音驱动的语言,英语单词非常适合发音。基本上只要你能把这个单词正确地读出来,你就不太容易记忆错误。大家可以试试,如果一个单词你看到的时候立刻反映出或者给出读音,是不是马上这个单词的词根词缀就浮现了?正确的拆分词根词缀也出现了?
而且词根词缀在变化的时候,消去或者添加一些字母都是以更加方便的读出来为标准的,这就是经常可以看到的在词根和词缀之间会多出一些成分(比如字母i,o)的单词,i,o往往就是连接词根词缀,方便读出的。具体的更加深入的内容,大家可以听一听刘一男老师的讲座,非常好,虽然他的GRE录屏只是针对红宝书的前一部分。我在GRE单词背诵推荐分享了下自己的感受。
为了克服原来刷单词的PDF的缺点,我从音频配套的Excel中提取了List28-31的内容再用LaTeX生成需要的PDF,最后把这两个部分拼接在一起。
大家可以在这里下载
Github:再要你命3000手机刷词版-revised-20141205.pdf
技术实现细节
不感兴趣可以不看,需要的文件和说明都在上面.
主要是从Excel导出数据生成TeX文件,然后用LaTeX生成文件,再用Linux下编辑PDF的神器PdfShuffler合成最终文件。
Excel生成TeX文件
既然是在Github上写文章就把代码放出来吧,主要用Python的xlrd模块实现。
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 21 23:07:19 2014
@author: famer
"""
# this is the script to create a pdf file that can be read on smartphone
# original date is is in an excel called 3k.xls
# to create the pdf we use Latex
import xlrd
data = xlrd.open_workbook('3k.xls')
def createtex(i):
table = data.sheet_by_index(i)
texname=str(table.cell(0,0)).lstrip("text:u'").rstrip("'")
file= open (texname+".tex","wr")
file.write("%!TEX program=xelatex \n")
file.write("%!TEX root=3k.tex \n")
file.write("\chapter{ %s} \n" %texname )
file.write("\\begin{enumerate} \n")
nrows = table.nrows
for i in range(1,nrows):
word_eng=str(table.cell(i,0)).lstrip("text:u'").rstrip("'")
file.write("\item %s \\\\ \n" % word_eng)
word_chn=str(table.cell(i,1)).decode("unicode_escape").encode("utf8").lstrip("text:u'").rstrip("'")
file.write("%s \n" % word_chn)
file.write("\end{enumerate} \n")
file.close()
if __name__=="__main__":
for i in range(29,33):
createtex(i)
print "Done"
#### LaTeX文件生成
主要配置部分使用了LaTeX工作室的这个帖子LaTeX技巧681:一个适合 Kindle 阅读的简略模板–林莲枝
不过我把Geometry参数从适合Kindle的6寸改成了适合手机的3*6 inch。恕不赘述。
今天再次查看才发现,对于e开头的字母都会出现错误。原来我使用的输出代码是
word_eng=str(table.cell(i,0)).lstrip("text:u'").rstrip("'")
word_chn=str(table.cell(i,1)).decode("unicode_escape").encode("utf8").lstrip("text:u'").rstrip("'")
仔细看看,问题应该是出现在去掉左半不需要的字符串的时候,所以使用了新的输出代码,新的代码如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 21 23:07:19 2014
@author: famer
"""
# this is the script to create a pdf file that can be read on smartphoe
# original date is is in an excel called 3k.xls
# to create the pdf we use Latex
import xlrd
data = xlrd.open_workbook('3k.xls')
def createtex(i):
table = data.sheet_by_index(i)
texname=str(table.cell(0,0)).lstrip("text:u'").rstrip("'")
file= open (texname+".tex","wr")
file.write("%!TEX program=xelatex \n")
file.write("%!TEX root=3k.tex \n")
file.write("\chapter{ %s} \n" %texname )
file.write("\\begin{enumerate} \n")
nrows = table.nrows
for i in range(1,nrows):
word_eng=table.cell_value(i,0)
file.write("\item %s \\\\ \n" % word_eng)
word_chn=table.cell_value(i,1)
file.write("%s \n" % word_chn)
file.write("\end{enumerate} \n")
file.close()
if __name__=="__main__":
for i in range(29,33):
createtex(i)
print "Done"
核心要点就是直接使用,xlrd模块内置的提取内容代码cell_value而不是自己生硬的编码。
word_eng=table.cell_value(i,0)
word_chn=table.cell_value(i,1)
Python不愧是自带电池的语言,使用内置方法而不是自己生搬硬套一个。
不过现在我还是不明白原来方法哪里出问题了,同时为什么其他单词不出问题,e开头的单词都出问题。直接cell输出确实是text:u’ruthless’啊,这样的情况下把左右相同的内容去掉不就行了么?e到底有什么特殊?
还是’e有什么特殊含义?Google也没啥提示。
问题总结下就是
text:u’ethos’
这样的字符串为什么.lstrip(“text:u’”).rstrip(“’“)会去掉e这个字母?但是同样的方法其他单词却可以成功?
如图所示:
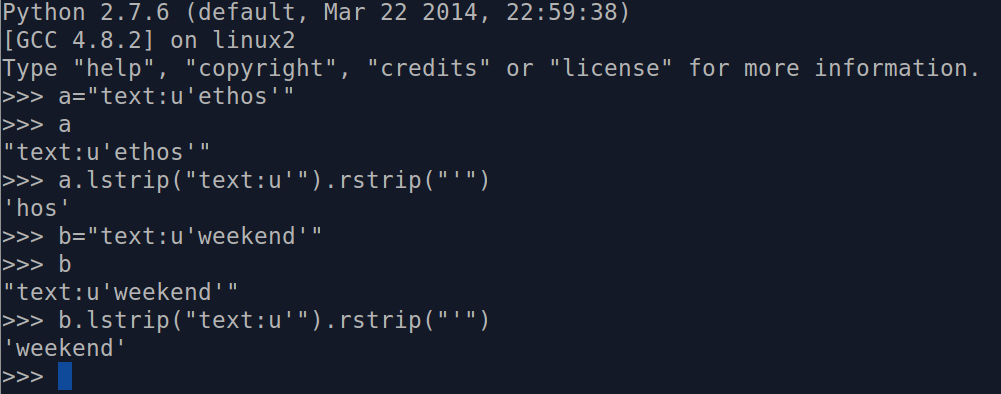
Python 2.7.6 (default, Mar 22 2014, 22:59:38)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> a="text:u'ethos'"
>>> a
"text:u'ethos'"
>>> a.lstrip("text:u'").rstrip("'")
'hos'
>>> b="text:u'weekend'"
>>> b
"text:u'weekend'"
>>> b.lstrip("text:u'").rstrip("'")
'weekend'
终于明白为什么了,通俗的说,lstrip()方法是基于字母的,比如
>>> ' spacious '.lstrip()
'spacious '
>>> 'www.example.com'.lstrip('cmowz.')
'example.com'
注意lstrip(‘cmowz.’)最大匹配里面的每一个字母,直到遇到不同字母!!!参见str.lstrip的文档
细节是魔鬼!
其实也有讨巧的方法,比如我在这里的开头是一个固定的字符串,所以
"text:u'weekend'"[7:-1]
利用字符串数组的索引也可以达到得到需要部分的目的。
Stackoverflow有现成的解答比如,Why does str.lstrip strips an extra character?,比如Why str.lstrip will truncate letter e for words beginning with e but not for other letters?
其实比较更好的方法除了数组索引还包括自己写一个正则表达式来解决!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK