

(Wide&Deep) Wide & Deep Learning for Recommender Systems
source link: https://xiang578.com/post/wide-and-deep.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
(Wide&Deep) Wide & Deep Learning for Recommender Systems
这是一篇推荐系统相关的论文,场景是谷歌 Play Store 的 App 推荐。文章开头,作者点明推荐系统需要解决的两个能力: memorization 和 generalization。
memorization 指的是学习数据中出现过的组合特征能力。最常使用的算法是 Logistic Regression,简单、粗暴、可解释性强,而且会人工对特征进行交叉,从而提升效果。但是,对于在训练数据中没有出现过的特征就无能为力。
generalization 指的是通过泛化出现过特征从解释新出现特征的能力。常用的是将高维稀疏的特征转换为低维稠密 embedding 向量,然后使用 fm 或 dnn 等算法。与 LR 相比,减少特征工程的投入,而且对没有出现过的组合有较强的解释能力。但是当遇到的用户有非常小众独特的爱好时(对应输入的数据非常稀疏和高秩),模型会过度推荐。
综合前文 ,作者提出一种新的模型 Wide & Deep。
从文章题目中顾名思义,Wide & Deep 是融合 Wide Models 和 Deep Models 得到,下图形象地展示出来。
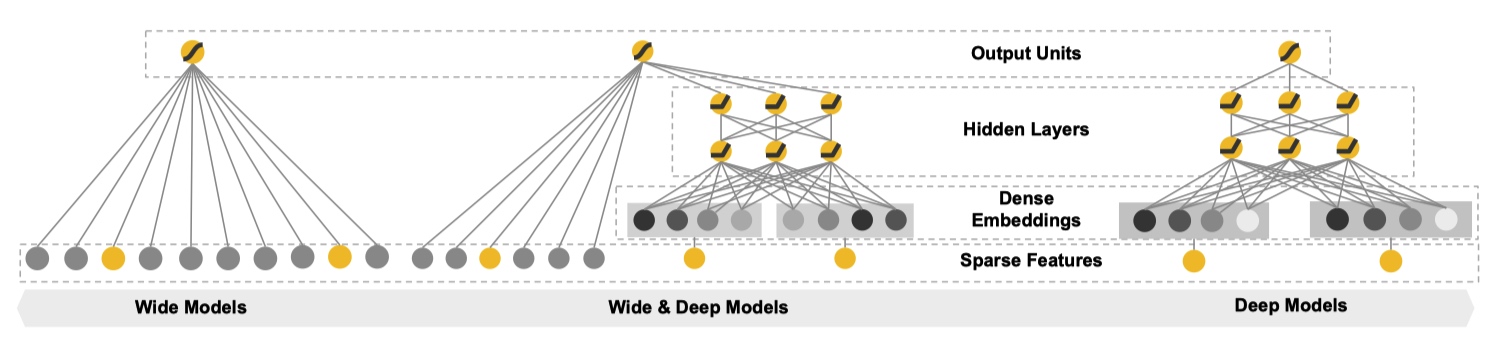 Wide & Deep Models
Wide & Deep ModelsWide Component 是由一个常见的广义线性模型:y=wTx+by=wTx+b。其中输入的特征向量 xx 包括两种类型:原始输入特征(raw input features)和组合特征(transformed features)。
常用的组合特征公式如下:
AND(gender=female, language=en) 当且仅当 x 满足(“gender=female” and “language=en”)时,ϕk(x)=1ϕk(x)=1。
Deep Component 是一个标准的前馈神经网络,每一个层的形式诸如:a(l+1)=f(W(l)a(l)+b(l))a(l+1)=f(W(l)a(l)+b(l))。对于输入中的 categorical feature 需要先转化成低维稠密的 embedding 向量,再和其他特征一起喂到神经网络中。
对于这种由基础模型组合得到的新模型,常用的训练形式有两种:joint training 和 ensemble。ensemble 指的是,不同的模型单独训练,且不共享信息(比如梯度)。只有在预测时根据不同模型的结果,得到最终的结果。相反,joint training 将不同的模型结果放在同一个损失函数中进行优化。因此,ensmble 要且模型独立预测时就有有些的表现,一般而言模型会比较大。由于 joint training 训练方式的限制,每个模型需要由不同的侧重。对于 Wide&Deep 模型来说,wide 部分只需要处理 Deep 在低阶组合特征学习的不足,所以可以使用简单的结果,最终完美使用 joint traing。
预测时,会将 Wide 和 Deep 的输出加权得到结果。在训练时,使用 logistic loss function 做为损失函数。模型优化时,利用 mini-batch stochastic optimization 将梯度信息传到 Wide 和 Deep 部分。然后,Wide 部分通过 FTRL + L1 优化,Deep 部分通过 AdaGrad 优化。
本篇论文选择的实验场景是谷歌 app 商店的应用推荐,根据用户相关的历史信息,推荐最有可能会下载的 App。
使用的模型如下: 
一些细节: - 对于出现超过一定次数的 categorical feature,ID 化后放入到模型中。 - Continuous real-valued features 通过 cumulative distribution function 归一化到 [0, 1] 区间。 - categorical feature 由 32 维 embedding 向量组成,最终的输入到 Deep 部分的向量大概在 1200 维。 - 每天在前一天 embedding 和模型的基础上进行增量更新。
实验结果:
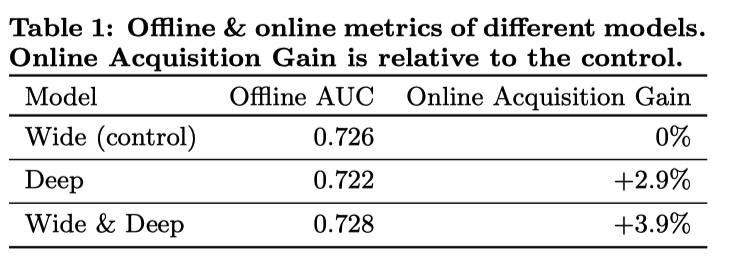 实验结果
实验结果Wide & Deep 模型相对于其他两个模型毫无疑问有提升。但结果中也一个反常的现象:单独使用 Deep 模型离线 AUC 指标比单独使用 Wide 模型差,但是线上对比实验时却有较大的提升。论文中作者用了一句:线下实验中的特征是固定的,线上实验会遇到很多没有出现过的特征组合,Deep 相对于 Wide 有更好的模型泛化能力,所以会有反常现象。由于笔者工作中不关注 AUC,也没有办法继续分析。
作者从推荐系统的的 memorization 和 generalization 入手,设计出新的算法框架。通过线上和线下实验实验,证明 Deep 和 Wide 联合是必须的且有效的。最终也在自己的业务场景带来提升。
Reference
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK