

Do You Want to Know a Secret?
source link: https://rjlipton.wpcomstaging.com/2018/08/25/do-you-want-to-know-a-secret/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Do You Want to Know a Secret?
A riff on writing style and rating systems
Mark Glickman is a statistician at Harvard University. With Jason Brown of Dalhousie University and Ryan Song also of Harvard—we’ll call them GBS—he has used musical stylometry to resolve questions about which Beatle wrote which parts of which songs. He is also a nonpareil designer of rating systems for chess and other games and sports.
Today we discuss wider issues and challenges arising from this kind of work.
In fact, we’ll pose a challenge right away. Let’s call it The GLL Challenge. Many posts on this blog have both our names. In most of them the writing is split quite evenly. Others like this are by just one of us. Can you find regularities in the style of the single-author ones and match them up to parts of the joint ones?
Most Beatles songs have single authors, but some were joint. Almost all the joint ones were between John Lennon and Paul McCartney, and in a number of those there are different accounts of who wrote what and how much. Here are examples of how GBS weighed in:
- Although the 1962 song, “Do You Want to Know a Secret?” was credited as “Lennon/McCartney” and even as “McCartney/Lennon” by a band who covered it in 1963, it has long been agreed as mostly by Lennon, as labeled on this authorship list. GBS confirm this.
- The two composers differed, however, in their accounts of “In My Life” and it has taken GBS to credit it all to Lennon with over 98% confidence.
- The song “And I Love Her” is mainly by McCartney, but GBS support Lennon’s claim to have written the 16-syllable bridge verse.
- Lennon said “The Word” was mainly his, but GBS found McCartney’s tracks all over it.
Tell Me Why Baby It’s You
To convey how it works, let’s go back to the GLL Challenge. I tend to use longer words and sentences, often chaining further thoughts within a sentence when I could have stopped it at the comma. The simplest approach is just to treat my sole posts as “bags of words” and average their length. Do the same for Dick’s, and then compare blocks of the joint posts. The wider the gap you find in our sole writings, the more confidently you can ascribe blocks of our joint posts that approach one of our word-length means or the other.
For greater sophistication, you might count cases of two consecutive multisyllabic words, especially when a simple word like “long” could have replaced the second one. Then you are bagging the pairs of words while discarding information about sentence structure and sequencing. An opposite approach would be to model the probability of a word of length 


GBS counted pairs—that is, transitions from one note or chord to another—but did not analyze whole musical phrases. The foremost factor, highlighted in lots of popular coverage this past month, is that McCartney’s transitions jump around whereas Lennon’s stay closer to medieval chant. Although GBS covered songs from 1962–1966 only, the contrast survives in post-1970 songs such as Lennon’s “Imagine” and “Woman” versus McCartney’s “Live and Let Die” and the refrain of “Band on the Run.”
To my ears, the verses of the last creep like Lennon, whereas Lennon’s “Watching the Wheels” has swoops like McCartney. Back when they collaborated they may have taken leaves from each other, as I sometimes channel Dick. The NPR segment ended with a query by Scott Simon about collaborative imitation to Keith Devlin, who replied:
For sure. And that’s why it’s hard for the human ear to tell the thing apart. It’s also hard for them to realize who did it and this is why actually the only reliable answer is the mathematics because no matter how much people collaborate, they’re still the same people, and they have their preferences without realizing it. [Lennon’s and McCartney’s] things come together—that works—but they were still separate little bits. The mathematics isolates those little bits that are unique to the two people.
GBS isolated 149 bits that built a confident distinguisher of Lennon versus McCartney. This raises the specter of AI revealing more about us than we ourselves can plumb, let alone already know. It leads to the wider matter of models for personnel evaluation—rating the quality of performance—and keeping them explainable.
A Paradox of Projections
Glickman created the rating system Glicko and partnered in the design of URS, the Universal Rating System. Rather than present them in detail we will talk about the problems they intend to solve.
The purpose is to predict the how a player 

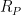


Here 


The last says that the marginal value of extra skill tails off the more one is already superior to one’s opponent. Together these say
To use the calculator, pop in the difference as 

Unless the players are equally rated, the projection is certainly wrong. It overestimates the chances of the stronger player. Moreover, every projection system that obeys the above axioms has the same defect.
Here’s why: We do not know each rating exactly. Hence their difference 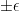




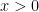
We might think we can evade this issue by using the curves

This shifts the original 
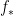

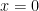


All simple and elegant prediction models are overconfident.
Indeed, Glickman’s own explanation on page 11 of his survey paper, “A Comprehensive Guide to Chess Ratings,” is philosophically general:
At first, this consistent overestimation of the expected score formula may seem surprising [but] it is actually a statistical property of the expected score formula.
To paraphrase what he says next: In a world with total ignorance of playing skill, we would have to put 
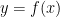


Newtonian Ratings and Grothendieck Nulls
The Glicko system solves this problem by giving every player 



However, Newton’s laws behave as though bodies have pinpoint mass values at their centers of gravity, no matter how the mass may “glob” around it. Trying to capture an inverse-square law for chess ratings leads to a curious calculation. Put

for 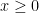
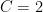




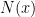

Then taking 

David Mumford and John Tate, in their 2015 obituary for Alexander Grothendieck, motivated Grothendieck’s use of nilpotent elements via situations where one can consider 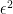

Here we have an ostensibly better situation: In our original expression for 
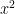



then the pinpoint value 
Alas, insofar as the real world runs on real algebra rather than Grothendieck algebra, we have to keep the numerator 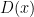


Open Problems
What will AI be able to tell from our “track records” that we cannot?
Several theories of test-taking postulate a sigmoid relationship between a student’s ability 

Aggregating the
[some word tweaks and typo fixes]
Like this:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK