

如何实现校园疫情防控自动打卡
source link: https://noionion.top/7431.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
如何实现校园疫情防控自动打卡
免责声明 本教程仅提供参考学习使用,若读者参考本教程编写脚本后违反相关法律法规造成损失,将由读者自行承担,教程所有者不承担一切责任!
请在法律循序范围内自行参考制作自己的打卡脚本,当发生发烧等异常现象是仍需如实填报
此教程针对有爬虫基础的同学编写
本来是想开源的,但考虑到前阵子的健康码 APP 事件,以及自动打卡扩散出去实际上是影响疫情防控的行为已公开,仓库地址为 https://github.com/2X-ercha/HNU-AutoClockIn ,还有水一篇博文的需要
使用说明书地址:https://noionion.top/3355.html
就决定写教程了(本教程分几次写完,时间不定)
理论上来说,只要是能用网页进入打卡页面的打卡网站,都可以参考本教程实现。身在湖大,就用湖大的疫情防控打卡举个栗子了
教程分三步
打卡 - 微信提醒(已过期)- 自动化
- 一个 Github 账号
- 微信(X)
教程开始!
用 Python 实现打卡功能
最开始想的是用模拟浏览器的方式进行点击处理,但未免过于复杂。后来从大佬那了解到只要知道登录和打卡时网页发送了什么数据给后台 (post) 就可
打开湖大的打卡界面,进行登录,康康网页发送了些什么
找到右侧的 login 文件并查看它的请求内容,显然,Code 是我们的账号,Password 是我们的密码,VerCode 是验证码,那 Token 又是什么东西呢?
回到登录页,刷新验证码,网络会得到两个传输文件
可以看到,它向 https://fangkong.hnu.edu.cn/api/v1/account/getimgvcode 这个网址 get 了一下,然后得到了响应,显然响应得到的 token 就是了
通过检索网页 html 可以得到,这个验证码的地址格式为
"https://fangkong.hnu.edu.cn/imagevcode?token=" + token
所以第一步要登录所发送的数据就剩验证码内容了
step 1: 爬取验证码并解析
爬取验证码的操作就和爬图片没什么区别,只是前面先加了一步爬取 token 的操作(这里的请求头不做严格要求)
token_json = requests.get("https://fangkong.hnu.edu.cn/api/v1/account/getimgvcode", headers=headers_1)
对爬取的数据解码成字典并取出 token
import json
data = json.loads(token_json.text)
token = data["data"]["Token"]
爬验证码并保存
img_url = "https://fangkong.hnu.edu.cn/imagevcode?token=" + token
with open("img.jpg", "wb") as img:
img.write(requests.get(img_url).content)
为了自动化方便一些,这里采用在线调用接口的方式进行(接口来自于百度飞桨 OCR 识别)
这里安利一篇教程(来自大二学长):使用 Python 快速实现图片文字识别(30 行代码)
直接放代码(我也是直接 ctrl+c 和 ctrl+v 过来的)
import base64
headers_3 = {
'Host': 'cloud.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76',
'Accept': '*/*',
'Origin': 'https://cloud.baidu.com',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://cloud.baidu.com/product/ocr/general',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
} # 百度OCR识别验证码
with open("img.jpg",'rb') as f:
img = base64.b64encode(f.read())
data = {
'image': 'data:image/jpeg;base64,'+str(img)[2:-1],
'image_url': '',
'type': 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic',
'detect_direction': 'false'
}
response = requests.post('https://cloud.baidu.com/aidemo', headers=headers_3, data=data)
result = response.json()['data']['words_result'][0]['words']
result 就是我们的验证码内容了(识别率还挺高的)
step 2: 登录
登录需要发送的信息在上文已经说明了,是一个 JSON 字符串 (注意键值对都是字符串(除了 null))
data = {
"Code":"2020****0131",
"Password":"**********",
"WechatUserinfoCode":null, # 非必要
"VerCode":result,
"Token":token
}
现在我们可以向网页发送请求了!
为了保持会话(服务器才知道你登录和提交打卡信息用的是一个号),这里建立一个临时会话
session = requests.Session()
然后复制粘贴再打引号你的请求头 (注意一定要 login 文件的 headers, 和上面爬验证码和解析验证码用的 headers_1 不同,这里记为 headers_2)
然后 post 你的账号密码验证码(注意 url 也是 login 文件的请求地址,记得对 data 做 json 字符串处理)
response = session.post("https://fangkong.hnu.edu.cn/api/v1/account/login", headers=headers_2, data=json.dumps(data))
如果得到的 response.json()["code"] 不为 0,那么验证码错误,需要重新登录(百度的 OCR 也有一定概率出错的)
至此,登录部分就完成啦!
step 3: 打卡
我们试着打卡一次,得到的请求如下(因为今天已经打卡过了,我也不记得打卡时网络传输的文件是啥,我只能找一下昨天的截图
唉,找不到
大概就这些数据吧
data1 = { # 假期版本
# "Temperature":null,
"RealProvince":RealProvince,
"RealCity":RealCity,
"RealCounty":RealCounty,
"RealAddress":RealAddress,
"IsUnusual":"0",
"UnusualInfo":"",
"IsTouch":"0",
"IsInsulated":"0",
"IsSuspected":"0",
"IsDiagnosis":"0",
"tripinfolist":[
{
"aTripDate":"",
"FromAdr":"",
"ToAdr":"",
"Number":"",
"trippersoninfolist":[]
}
],
"toucherinfolist":[],
"dailyinfo":
{
"IsVia":"0",
"DateTrip":""
},
"IsInCampus":"0",
"IsViaHuBei":"0",
"IsViaWuHan":"0",
"InsulatedAddress":"",
"TouchInfo":"",
"IsNormalTemperature":"1"
# "Longitude":null,
# "Latitude":null
}
data2 = { #上学期间版本
"BackState": 1,
"MorningTemp": "36.5",
"NightTemp": "36.5",
"RealAddress": RealAddress,
"RealCity": RealCity,
"RealCounty": RealCounty,
"RealProvince": RealProvince,
"tripinfolist": []
}
和上面一样 post 数据即可 (注意是 session.post() 而不是 requests.post())
提交的 url 为 https://fangkong.hnu.edu.cn/api/v1/clockinlog/add, 请求头和登录时的请求头 headers_2 一样即可。
如果你要查看结果
msg = response.json()["msg"]
print(msg)
即可,如果打卡成功返回的信息即为成功
至此,你已经可以实现一键打卡了!
微信提醒(已过期)
这里安利一个应用 server 酱 。你可以向指定的网页发送一个 get/post 请求来达到微信推送的目的。
server 酱的登录就需要开头说到的 github 账号了。如果你没有 github 的账号,可以点此去注册一个 https://github.com
登录后根据官网上的提示绑定微信号,获取你的 SCKEY。然后在你代码你需要的地方嵌入请求即可
例如,我在打卡成功后嵌入这样一段代码(其中 sckey 就是 server 提供的 SCKEY 字符串,msg 是上文打卡时返回的信息):
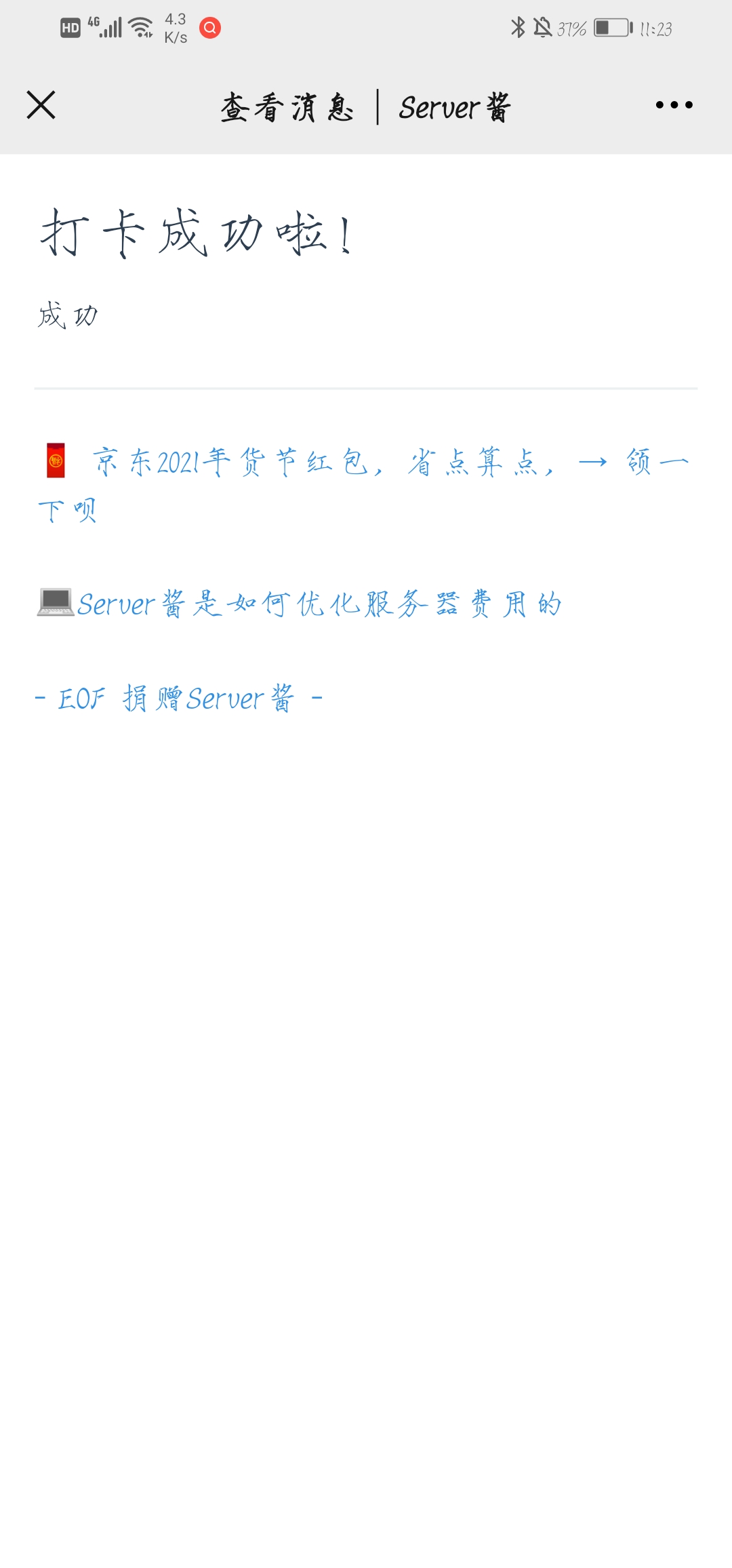
requests.get("http://sc.ftqq.com/"+ sckey +".send?text=打卡成功啦!&desp=" + msg)
打卡成功会给我发送如下消息:


利用 github action 实现自动化
github 账号实现微信提醒其实只是次要部分,其真正的用途实际上是实现自动化打卡
毕竟你不太可能 24 小时开着电脑,也不太可能白嫖服务器 (如果能的话麻烦告诉我,我也要!)
step 1: 设置 TOKEN (如果之前已经设置过,请跳过此步)
鼠标放在右上角,选择 setting (这边直接偷走小康的图,懒得自己截图上传了)
点击 Developer settings。
选择 Personal access tokens,添加一个新的 TOKEN。
这个 TOKEN 主要使用来启动 actions 和上传结果用的。
设置名字为 GITHUB_TOKEN , 然后勾选 repo , admin:repo_hook , workflow 等选项,最后点击 Generate token 即可。
名字请务必使用 GITHUB_TOKEN 。
step 2: 编写 action 配置文件
github 会自动对 .github/workflows/ 目录下的 xxx.yml 自动运行。例如我的目录结构为:
其中的 AutoClockIn.py 就是打卡的程序代码
yml 代码说明:
1 为自动运行的时间,遵循
UTF-0时间,+8h 后才是北京时间。如果想自行设定其他时间可以百度cron表达式在线转换, 然后删除年和秒的部分。
2 为手动运行的时间,点仓库那个
star(unstar要多点一次) 就可以手动运行啦!
其他的代码注释应该看得懂,看不懂照着打就是了。
step 3: 创建仓库
这里建议创建个私有仓库(公开被白嫖后出事你是负责任的,免责声明可能都救不了你)
(而且公开的话意味着你的账号密码公开,除非你像我一样采用了密钥处理) (什么,你想学?我这里不讲这个东西)
熟悉 git 操作的我就不多说了
不熟悉也没关系,我们手动创建也可
然后建立你的 py 文件并把打卡代码复制上去
创建文件夹类似 /github ,同样的,我们创建 yml 文件并复制粘贴代码
这里再次强调文件目录结构要和上面截图的一样!!!
全部保存完后可以启动试试啦!
step 4: 启动 action
为了保证自动的正常进行,手动启动调试是一个好习惯
点击仓库右上角的 star 按钮,然后点击 actions
成功的话应该是这样的(因为我已经打卡好多天了,所以记录挺多的)
最后再次强调,当发生发烧等异常现象是仍需如实填报!!!
完结撒花!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK