

知无涯之回车换行的故事
source link: https://feihu.me/blog/2014/end-of-line/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
知无涯之回车换行的故事
17 Dec 2014 • 3 min. read • 8 Comments

不知各位有没有过这样的经历:
- Linux上创建的文件在Windows上打开时,结果所有内容会挤成一行。而Windows上创建的文件在Linux上打开时,每一行的结尾又多了一个奇怪字符
^M。 - 在安装Windows版的git时,安装向导在某一步会提示你选择”Configuring the line ending conversions”,里面提到了Windows-style和unix-style的line endings,为什么会有这些呢?
- 调用C语言的API
fopen时,会有text mode和binary mode,这两者有什么区别?
其实这一切都和我们常说的回车换行有关,但你有没有很奇怪,什么是回车?直接用换行不就好了,为什么要分开两个词?我们使用的键盘上的键明明起得是换行的作用,为什么叫回车?千万别被绕晕了,本文将和大家讨论有关回车换行的一段有趣的历史,随后将回答这些问题。
我们通常所说的回车换行其实只相当于一个概念,即一行结束,开始下一行,英文叫做End-of-Line,简写为EOL。你也可以将这理解为一个逻辑上的换行,但为了与回车换行中的换行区分开来,我们后面还是称呼它为EOL。
回车换行严格说起来是两个独立的概念,即回车和换行,它们的出现要追溯到计算机出现之前,那时有一种电传打字机:Teletype Model 33 ASR,如下图:

在打字机上,有一个部件叫Carriage,它是打字头,相当于打字机的光标。每输入一个字符,Carriage就前进一格。当输满一行后,想要切换到下一行时,需要Carriage在两个方向上的运动:水平和竖直。水平方向上需要将Carriage移到一行的起始位置,竖直方向上需要纸张向上移动一行,此时也就是相当于Carriage下移了一行。(这在很多影视作品里面可以看到,打字者们打完一行之后,通常会用手拨动一个滑块,然后听到“咔”的一声,接着输入下一行。只是在这款打字机中不再需要人为的去拨动。)而这两个动作分别对应着:
- Carriage Return(CR),也即回车,它在ASCII表中的值为0x0D,可以用转义符
\r表示 - Line Feed(LF),也即换行,它在ASCII表中的值为0x0A,可以用转义符
\n表示
因为打字机是机械的结构,所以虽然从逻辑上只表示为EOF,但从设计上它需要分为两个独立的操作,这也正是我们习惯连起来说回车换行的原因。可以参照下图看看其键盘的布局:

键盘的右方有一个Line Feed和Return,从名字可以看出,这分别对应着前面提到的两个操作。然而,通常一个回车操作不能够在一个字符打印的时间内完成,所以可以利用Carriage移动的时间,去完成另外一个完全独立的操作Line Feed,这也是通常Carriage Return会被放在Line Feed前面的原因。你可以想象,如果在在Carriage和纸移动的过程中按下了其它的字符键,打印的内容将变得十分混乱。所以在Carriage Return和Line Feed之后,有时会有1~3个NUL字符(即相当于汇编语言中的空指令,仅起占位作用),以等待前两个操作的完成。所以实际上打字机的EOL为:EOL = CR + LF + 1~3NUL。
等到早期的计算机发明时,很自然的这两个概念被拿了过来。但是由于那时的存储设备非常昂贵,一些人认为在每行的结尾加两个字符用于换行,实在是极大的浪费,于是各个厂商在这一点上便出现了分歧。
由于一些早期的微型计算机还没有用于隐藏底层硬件细节的设备驱动,所以它们直接沿用了打字机的惯例,使用不带NUL的CRLF作为一个EOL。而CP/M为了和这些微型计算机使用同一个终端,也采用了这种设计。所以它的克隆MS-DOS也同样使用CRLF,由于Windows又是基于MS-DOS,为保持兼容性,所以就导致了如今的Windows是采用CRLF作为EOL,即\r\n(或0x0D 0x0A)。
而Multics在被设计之时就非常认真的考虑了这一问题,设计者们觉得只需一个字符便完全足够来表示EOL,这样更加合理。那么选择CR还是LF呢?本来由于那时的键盘上都有一个Return键,所以可能更好的选择是CR。但当时考虑到CR可以用来重写一行,以完成如粗体和删除线等效果,所以他们选择了稍稍难以理解的LF。然后自己设计了一个设备驱动程序来将LF转换为各种打字机所需要的EOL,这个方案非常完美,当然除了LF稍微奇怪一些。随后一脉相承的Unix和Linux们都继承了这个选择,于是你在这些操作系统上可以发现每一行的结尾是一个LF,即\n(或0x0A)。
Mac系统的选择就更加复杂一些。Apple在设计Mac OS时,他们采用了一个最容易理解的选择:CR,即\r(或0x0D)。但这只维持到Mac OS 9,后一个版本的Mac OSX基于Mach-BSD内核,所以此后版本的Mac OSX在每行的结尾存储了与Linux一样的LF,即\n(或0x0A)。
混乱的状况
还有很多其它的操作系统采用更加不同的方案,这也导致了混乱的产生,文章开始提出的几个问题便由该混乱引起。因为Linux和Mac OSX上使用的是LF,而Windows上使用的是CRLF,那么Linux和Mac OSX上创建的文件在Windows上打开时,由于每一行的结尾只有一个LF,但Windows只认识CRLF,所以便不会有逻辑上的换行处理,故所有的文字被挤到了一行。反过来,如果Windows上的文件在Linux和Mac OSX上打开时,仅需LF便可换行,那么每一行的结尾便多了一个CR,对应的ASCII码为^M。
而git的安装向导会特意有一个这样的提醒页面也出于此,因为一个项目可能有多个开发者,每个开发者可能使用的是不同的系统,那么开发者checkout代码时,如果不做换行符的转换,有可能就会出现只有一行或者行尾多了^M的情况。当然,如果你有一个可以识别多种EOL的现代文本编辑器,那么不做转换也无妨(notepad不行)。
如果出现了上面的转换问题时,也别着急,可以对文件进行转换。那在我们写程序时如何正确的处理这些问题?像隐藏硬件细节的驱动程序一样,我们可寄希望于高级语言。
为了避免在这些不同的实现中挣扎,高级语言给我们带来了福音,它们各自使用了统一的方式来处理EOL。在C语言中,你一定知道在字符串中如果要增加一个换行符的话,直接用\n即可,比如:
printf("This is the first line! \nThis is a new line!");上面的输出将是:
This is the first line!
This is a new line!
为什么C语言选择了\n而不是\r?这绝非偶然。熟悉C语言历史的朋友可能知道当初C语言是Dennis Ritchie为开发Unix而设计,所以它沿用了Unix上EOL的惯例便很容易理解了。而我们知道Unix使用的LF的ASCII码为0x0A,转义符为\n,因此C语言中也使用\n作为换行。
Text Mode VS Binary Mode
但是,千万别简单的认为上面的\n最终写到文件中就一定是其ASCII码0x0A,或者文件中的0x0A被读到内存中就是其转义符\n。这取决于你打开文件的方式。在C语言中,在对文件进行读取操作之前,都需要先打开文件,可以使用下面的函数:
#inlcude <stdio.h>
FILE *fopen(const char *path, const char *mode);注意看第二个参数mode,它是一个字符指针,通常可以为读(r),写(w),追加(a)或者读写(r+, w+, a+),仅指定这些参数时,文件将被当成是文本文件来操作,即Text Mode,而如果在这些参数之外再指定一个额外的b时,文件便会被当成是二进制文件,即Binary Mode。这两种模式的区别在哪里呢?这里稍稍有些复杂,因为它们在不同的平台上表现不同。
Windows平台
对于Windows平台,因为其使用CRLF来表示EOL,故对于Text Mode需要做一定的转换才能够与C语言保持一致。接下来的两个图可以给出最为直观的描述。
先看二者对于读操作的区别:
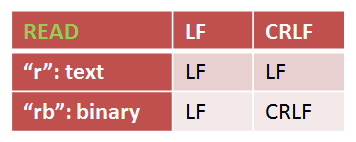
Text Mode下,C语言会尝试去“理解”这些回车与换行,它会知道LF和CRLF都可能是EOL,所以不管文件中是LF还是CRLF,被读进内存时都会变成LF。而Binary Mode下,C语言不会做任何的“理解”,所以这些字符在文件中什么样,读到内存中依然那样。
接下来是写操作的区别:
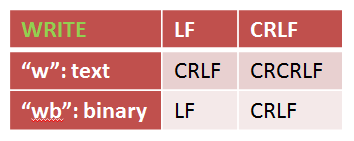
Text Mode下,内存中的每一个LF写入文件中时都会变为CRLF,当然,如果不幸内存中为CRLF,以此种模式写入到文件中时就会变成CRCRLF(注意:这里不是CRLF。原因我想大概是如果你认为内存中的数据是文本,那么它一定是以LF作为EOL,CR也一定是你有意而为之,是个有意义的字符,所以它并不会处理。)。而Binary Mode下,内存中的内容会被原封不动的写到文件中。
所以为了保证一致性,一定需要注意配套使用读和写,即读和写采用同一种模式打开文件。
Linux和Mac OSX平台
因为Linux和Mac OSX平台与C语言对待EOL的方式完全一致,所以Text Mode和Binary Mode在这些平台下没有任何区别,可以参考fopen的man page。实际上,所有遵循POSIX的平台都忽略了b这个参数。
虽说在这些平台上处理EOL非常简单,但是如果你的程序需要移植到其它非POSIX平台上时,请务必正确对待b参数。
如果还有兴趣,可以看看下面这些有趣的资料:
这样一个小小的EOL便如此复杂,给人们带来了极大的困扰,但就如我在知无涯之C++ typename的起源与用法最后讨论过的一样,这个决定是经历过无数决断、波折与妥协才有了现在的结果。你可以选择保守,为向后兼容而作出妥协,那么你得面对不断累加的“不完美”,甚至“丑陋”的设计;你也可大胆尝试,破旧立新,牺牲向后兼容换取进步,那你也许得忍受人们的“唾骂”,或许还需承担被人们抛弃的风险。如何在这之间作出选择,没有明确的答案,恐怕一切就只有靠自己去判断了吧。
(全文完)
feihu
2014.12.17 于 Shenzhen
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK