

Incorporating Partitioning and Parallel Plans into the SCOPE optimizer
source link: https://zhuanlan.zhihu.com/p/369898082
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Incorporating Partitioning and Parallel Plans into the SCOPE optimizer
这篇paper中讨论是的Microsoft的cosmos DB,其本身是一个海量数据的大规模计算平台,有些类似hadoop,使用的是一种类SQL的脚本,叫做SCOPE,针对SCOPE的优化器负责生成最优的执行计划。在1998年前后Microsoft基本丢弃了Sybase原有的优化器实现,并由Graefe主导重写了基于cascades的优化器。因此和Microsoft所有其他的数据库产品一样,SCOPE optimizer也是基于Cascades的transformation-based的优化器。
本paper讨论的就是,如何在SCOPE的优化过程中,无缝接入对于并行计划的考虑,同时利用functional dependency +等价列等概念,利用partitioning/grouping/ordering等信息尽量减少/避免分区,排序,分组等操作,提高执行效率。PolarDB的并行优化方案中,在属性统一描述 + 兼容性判断 + 属性推导等方面,大量参考了这篇paper的思路。
概略来说,它扩展了cascades中property的概念,把partitioning/grouping/sorting,用一个统一的structural property来进行描述,并利用属性的兼容性来生成更高效的并行plan。例如下面这个简单的例子:
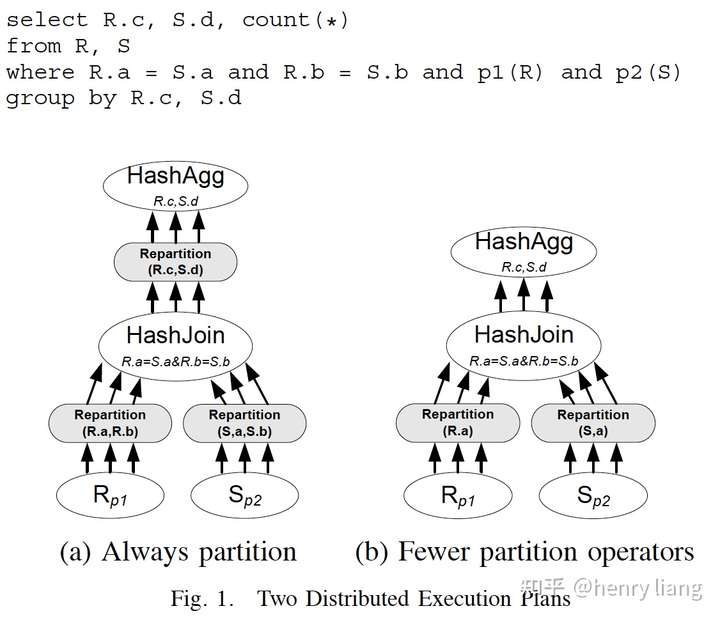
对于上图中的SQL query,最基础直观的并行执行方式如(a)所示,两个分区表先通过在join key上的repartition操作,形成co-locate join,并行join后根据后续group by key做二次repartition,完成aggregation的并行计算。这是一个合理的plan,但由于有多次的repartition而不那么高效。但如果基于R.a = S.a这个join条件,只在R.a / S.a上做第一轮repartition,且存在这样的functional dependency: R.c -> R.a(R.c是R的主键),则并行join后的结果也在R.c上分布,可以省去第二次repartition直接完成join。
可以看到通过利用FD等来推导分布的兼容性,就可以生成更简化的plan。
这篇paper就是以一种系统化的方式,统一且规范的描述了partitioning/grouping/sorting三方面的属性极其兼容性推导,然后融合到cascades的optimization rules中。此外,还引入了一系列利用FD / 数据约束的inference rules。
并行plan + exchange算子
data exchange operator是一个描述数据重新分布的算子,在并行/MPP环境下,exchange是保证数据并行处理的基本逻辑操作,具体实现中,exchange包含发(partition) + 收(merge)两个操作,在多台机器上同时执行。
这里主要考虑Initial Partitioning(1->n) , Full Repartitioning(m -> n), Full Merge (n -> 1) 这三种
- Partitioning 方案
一个公共前提是,Paritition本身是FIFO的方式,所以如果原来前后的两个tuple r1, r2,在分区之后如果还在一个分区内,则仍然保持这种前后关系。
- Hash Partitioning:基于partition key的hash value进行分发,partition之间无序,且不保证数据的均匀。
- Range Partitioning: 将partition key的domain分成若干不相交的range,partition之间整体有序,也不保证数据均匀。
- Non-deterministic Partitioning: 例如Round-robin/random分发,可以较好应对data skew。
- Broadcast: 将全量数据分发到所有目标节点,适合数据量较小的场景。
- Merging方案
将来自多个数据源的分发数据,汇总到单一节点。
- Random Merge: 从任一Input上获取数据,各input内部的顺序可以保留,各input之间的顺序无法保留。
- Sort Merge: 只有当各输入,在sort列上各自有序时,输出可以保证全体有序,使用例如多路归并的排序算法。
- Concat Merge: 一个input一个input的处理,各个input内部顺序可以保留,各input之间无法保证。
- Sort Concat Merge: 先确定各个input之间的顺序,然后按序对各input做处理,各个input内部顺序可以保留,input之间也可以全局有序。
optimizer中利用property
关于cascades优化器框架的介绍请看:
henry liang:The Cascades Framework for Query Optimizationzhuanlan.zhihu.com
在框架中,query expression用来描述某个特定的算子子树,其中的算子包括physical / logical operator,logical operator描述算子的操作类型,而physical operator则确定算子使用的物理算法。优化过程分为2种特定操作,Logical exploration和physical optimization。logical exploration应用transformation rules生成新的logical expressions,而physical optimization应用implementation rules将logical operator转换为physical operator。
如下算法描述了给定一个初始query expression以及对最终输出的property requirements后,超级简化的递归优化过程:
上图中有下划线的几个函数是优化中和physical property最为相关的几个操作:
- Determining child required properties
parent物理算子会对当前算子的输出施加某种property requirement,这个req必须被满足。例如如果parent是使用ordered group by的计算方式,会要求当前算子在group by key上具有有序性。同时当前算子的物理实现也会对其input children算子的输出提出某种property requirement,也同样需要被满足。
这个函数就是用来决定children的property requirement,它由父算子对当前算子的requirment和当前算子的物理实现决定。
- Deriving delivered properties
这个函数根据输入数据的物理属性和当前算子的物理实现算法,推导出其输出数据的物理属性。
- Property matching
一旦输出物理属性被推导出来,就需要判断其与当前算子的property requirement是否match,如果无法match则当前plan就是无效的,需要被丢弃。
注意所谓match并不要求完全一致,这里有一定的兼容性规则,后面会具体说明。
规范化描述
- Functional dependency / 约束 / 等价性
FD的含义是: 一组column set R与一组column set S,如果对其中任意两个tuple,其在R上的值相同,则在S上的值一定相同,则R -> S。
FD可能来源于几个方面:
- R -> R’ ,只要R’是R的子集
- key约束,一个relation的主键可以FD决定relation的所有其他列
- 等值谓词 col1 = col2 ,意味着 col1 -> col2 并且 col2 -> col1
- 等值常量 col1 = const,意味着
- grouping column,在做完group by后,grouping column成为结果的key
column等价类的含义在之前的文章[1]已经提及了,如果对于一个relation中的所有tuple,在某些column set上都具有相同的值,则这组column set构成column等价类,等价类中也可以包含常量,这和MySQL中的MEP概念一致。
- structural property
用一个统一结构来描述partitioning ,grouping, sorting这三方面的物理属性,属性根据其作用域分为了2个类别:parititioning是全局属性,描述全局的数据如何分布;grouping/sorting则是局部属性,描述了每个partition内部,数据的物理特性。(paper中使用了很多复杂的数学符号,其实概念是很简单的,为了便于说明这里就不一一列举了,只是口述下概念)
因此是property是从global/local两个维度,综合起来考虑。其中grouping是一个列的集合,分组列之间没有顺序要求,sorting则是一个列的列表,列之间的前后顺序不可变。
- 局部的property使用一组固定顺序的Action序列 {A1, A2 ... Am} 来描述,表示一个Action一个Action的进行操作,每个action都是基于前面action序列的结果进行操作,不破坏前面序列的属性:比如A1是分组{C1, C2},表示在C1,C2上分组,A2是排序C3,表示在每个C1,C2的分组内,进行排序。其中每个action要么是针对一组column做分组操作,要么针对单个column做排序操作。
- 全局的property描述partitioning方式,主要包含2种:ordered / non-ordered,non-ordered partition只能保证,在partition column上具有相同value的tuple会在同一个partition中;而ordered partition还可以额外保证,不同partition会覆盖disjoint的key range且partition间有序,也就是说,一个partition内tuple全部都小于另一个partition中的tuple。
把以上2个方面结合起来就构成了对structural property的规范描述:
前面是分区操作,其中 表示有序/无序的全局分区,后面则是一系列操作序列,用来构建分区内局部属性。而相关处理就在这2个正交的维度上,各自独立进行。
例如一个relation有C1, C2, C3列以及结构化属性{ },也就是说在C1上分区,而在每个分区内,数据首先在{C1, C2} 列上分组,而在每个分组内,按C3列有序。如下数据
Inference Rules
Rule 1. 局部属性可以从尾部truncate掉,这个很容易理解,因为每个action总是基于前序的action来操作,因此前序部分总可以被保留。
Rule 2. 全局属性可以expand,如果数据在C1列上做partition,它同样在{C1, C2}列上做partition,因为具有相同(c1,c2)组合值的元素具有相同c1值,因此必然在同一分区。
更广泛来说,在C1…Cm上分布,可以推导出在C1…Cm,Cm+1分布。
Rule 3. 在C列上有序,可以推导出在C列上分组,反过来不成立
Rule 4. 利用FD,可以尽量化简grouping列或者order列
对于group列集合,如果其中一些列可以functional的决定其他一些列,被决定的列可以从group列集合中去除。这里没有对列的顺序要求。
对于order列的集合,如果Cj的前缀部分可以functional的决定Cj,则Cj可以从order列集合中去除。注意这里是有列的顺序要求的,必须是前缀。
Rule 5. 对于local属性,还有一种化简方式
如果A1…Ai-1的操作序列所影响的列,可以完全决定Ai操作所影响的列,则Ai操作是无用的,可以去掉。
生成structural property
- Partition operator产生的property
前面已经提到,Partition本身是FIFO的方式,因此任一个分区内,tuple的顺序在partition前后是不会改变的,也就是partition只会影响全局属性,不会影响局部属性。exchange的output property会集成input property的局部属性,而改变其全局属性。
- 如果做hash distribution,则输出在partition列上呈现分组特定(相同数据位于同一分区)。
- 如果做range partition,则partition间整体有序,即ordered partition。
- 如果是随机分发,则
表示没有特定属性
- Broadcast时,
表示所有数据重复
- Merge operator产生的property
Merge操作会产生针对多个输入产生单一输出,其局部属性取决于input的局部属性和merge操作的类型。
- 对于non-ordered partitioning输入
random merge无法保留任何局部属性
Sort merge当输入的局部属性的有序列和全局的排序列一致,可以保证全局有序,否则无序
Concat merge当输入的局部属性已经在分区列上进行了分组,concat之后这个分组可以保留
Sort Concat merge同上
2. 对于ordered partitioning (range)输入:
random merge无法保留任何局部属性
Sort merge当输入的局部属性的有序列和全局的排序列一致,可以保证全局有序,否则无序
Concat merge当输入的局部属性已经在分区列上进行了分组,concat之后这个分组可以保留
Sort Concat merge,如果局部属性的排序列就是全局的分区列,则可以保证全局有序
- Repartition operator产生的property
repartition就是partition + merge的组合操作,是一个完整的exchange算子实现,因此其产生的属性也是前面2项的各种组合,如下图所示
生成property requirement
不同的算子的不同物理实现算法,会根据算子本身是串行或并行执行,对其输入的数据流的 property有不同的要求,列举在下图中
从上图可以看出,table scan/select/project对于输入无要求,主要是order by/group by/join。
- hash group by对输入无要求
- stream group by要求输入在分组列上已完成具有分组属性
- NL/HS join对输入无要求
- MergeJoin 要求输入在join列上有序
- hash group by要求输入的分区列是分组列的子集或相同。
- streaming group by除了这个要求外,还要求各个局部输入在分组列上已具有分组属性。
- NL/HS join要求输入的分区列,是join列的子集,且两侧的输入列要对应。
- MergeJoin 除了以上要求,还要求两侧的输入,在各个分区内按照join列有序
Property matching
有了output property和property requirement,下面就是两者之间如何匹配了。在评估output和requirement时,可以在global/local两个正交维度分别比较即可,方法类似于DB2中的order optimization的思路。
- 利用FD + 等价列,转换为最简且统一的normalized形式,具体就是首先用等价列中的head来统一替换其他列。
- 利用前面提到的各种推断规则,进行转换(truncate/expand/Co->Cg)和推导,判断是否可以从输出property => 要求property,如果可以,则说明两者match。
关于DB2具体如何处理order property,请看这篇文章
henry liang:Fundamental Techniques for Order Optimizationzhuanlan.zhihu.com
举个例子更容易说明白:
输出属性是
属性要求是
给定的FD是 { C6, C2 } -> { C3 },此外有两个等价列 { "C1", C6 }, { "C2", C7 },引号内的是head列。
先用等价列替换,变为
可以看到,这里不仅替换了属性描述本身,也替换了FD中的列信息!
然后应用{ C1, C2 } -> { C3 }这个FD,输出属性变为
先看全局分区属性,由于其可以expand,因此{C2,C1} => {C1,C2,C4}。
再看局部属性,由于其可以truncate,可以将尾部的C5排序去除掉,因此得到 ,同时由于inference rule 3,有序可以得到分组,因此得到
。
全局和局部属性都可以match,因此requirement可以被output满足。
Enforcer rules
在有了这些Property/Rules/Matching等之后,在Cascades的优化过程中,去集成parallel/serial的plan选项,就比较直接了:
- 在枚举每个物理算子实现时,既要枚举串行的实现,也要枚举不同的并行实现,不同的并行方式,可以产生不同的输出property,也会对输入有不同的property要求
- 利用enforcer rules,引入不同的enforcer (sort/exchange),并进行requirement的传导
enforcer rules包括对sorting/grouping/partition不同属性的处理,但思路都是一样的:
- 如果当前operator的物理实现,可以产生要求的property,则直接枚举该operator,然后递归到其child上,对child的要求就是该物理实现对于input的要求
- 如果当前operator的物理实现,只能维持输入的property,则枚举该operator,并递归到其child上,对child的要求,除了物理实现本身对于input的要求,还有透传下来的上层要求
- 如果当前operator的物理实现,无法产生要求的property,则枚举该operator,并在其上加入一个enforcer!这样改变了对该operator的输出要求,重新对该operator进行判断
以上过程其实就是cascades framework的处理流程的一部分,所有这些选择都要枚举到,然后基于cost选择最优。不过由于选项太多,会有一些heuristic,比如不同rules之间的优先级,从而做一些pruning。
这篇paper提出了这种统一的property处理框架,并集成到了cascades的优化流程中。
核心要素就是物理属性的推断规则 + 算子输出属性的生成 + 对输入属性的要求 + match推导。PolarDB的并行优化器参考了cascades的设计思路,因此也具备多属性的统一描述结构,其处理方式很多都参考了这篇paper,不过目前还没有这么完善的推断规则,后续有持续改进的空间。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK