

一次死锁导致CPU异常飘高的整个故障排查过程
source link: https://www.cnblogs.com/operationhome/p/14695886.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一、问题详情
linux一切皆文件
2021年4月2号,晚上10.45分左右,线上业务异常,后排查 线上服务器CPU 异常高,机器是 16核 64G的。但是实际负载已经达到了 140左右。
top 命令截图
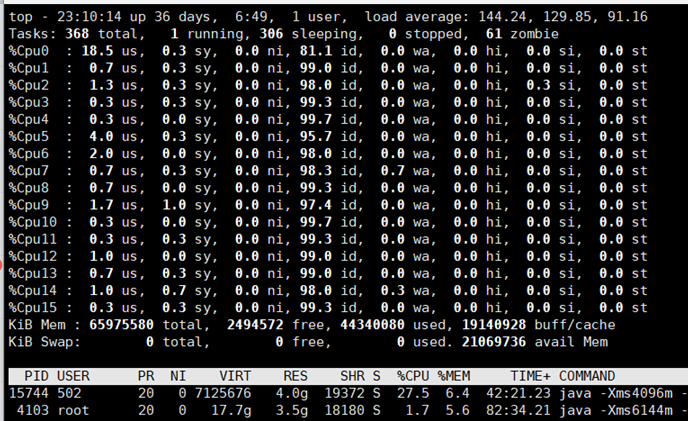
联系腾讯云排查
- 虚拟机所属于物理机是否有故障。
- 虚拟机所用的资源是否有抖动或者变更。(网络/存储等)
腾讯云回复暂无异常。
检查系统日志发现异常
Apr 2 22:45:22 docker-machine systemd: Reloading.
Apr 2 22:46:37 docker-machine systemd-logind: Failed to start session scope session-175098.scope: Connection timed out
Apr 2 22:47:26 docker-machine systemd-logind: Failed to start session scope session-175101.scope: Connection timed out
Apr 2 22:47:51 docker-machine systemd-logind: Failed to start session scope session-175102.scope: Connection timed out
Apr 2 22:48:26 docker-machine systemd-logind: Failed to start session scope session-175104.scope: Connection timed out
Apr 2 22:48:51 docker-machine systemd-logind: Failed to start session scope session-175105.scope: Connection timed out
Apr 2 22:49:06 docker-machine kernel: INFO: task systemd:1 blocked for more than 120 seconds.
Apr 2 22:49:06 docker-machine kernel: Not tainted 4.4.108-1.el7.elrepo.x86_64 #1
Apr 2 22:49:06 docker-machine kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Apr 2 22:49:06 docker-machine kernel: systemd D ffff880fd8bebc68 0 1 0 0x00000000
Apr 2 22:49:06 docker-machine kernel: ffff880fd8bebc68 ffff880fd5e69c00 ffff880fd8be0000 ffff880fd8bec000
Apr 2 22:49:06 docker-machine kernel: ffff880fd8bebdb8 ffff880fd8bebdb0 ffff880fd8be0000 ffff88039c6a9140
Apr 2 22:49:06 docker-machine kernel: ffff880fd8bebc80 ffffffff81700085 7fffffffffffffff ffff880fd8bebd30
Apr 2 22:49:06 docker-machine kernel: Call Trace:
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700085>] schedule+0x35/0x80
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81702d97>] schedule_timeout+0x237/0x2d0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff813392cf>] ? idr_remove+0x17f/0x260
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700b81>] wait_for_completion+0xf1/0x130
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810aa6a0>] ? wake_up_q+0x80/0x80
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810e2804>] __synchronize_srcu+0xf4/0x130
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810e1c70>] ? trace_raw_output_rcu_utilization+0x60/0x60
Apr 2 22:49:06 docker-machine kernel: [<ffffffff810e2864>] synchronize_srcu+0x24/0x30
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81249b3b>] fsnotify_destroy_group+0x3b/0x70
Apr 2 22:49:06 docker-machine kernel: [<ffffffff8124b872>] inotify_release+0x22/0x50
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81208b64>] __fput+0xe4/0x210
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81208cce>] ____fput+0xe/0x10
Apr 2 22:49:06 docker-machine kernel: [<ffffffff8109c1e6>] task_work_run+0x86/0xb0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81079acf>] exit_to_usermode_loop+0x73/0xa2
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81003bcd>] syscall_return_slowpath+0x8d/0xa0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81703d8c>] int_ret_from_sys_call+0x25/0x8f
Apr 2 22:49:06 docker-machine kernel: INFO: task fsnotify_mark:135 blocked for more than 120 seconds.
Apr 2 22:49:06 docker-machine kernel: Not tainted 4.4.108-1.el7.elrepo.x86_64 #1
Apr 2 22:49:06 docker-machine kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Apr 2 22:49:06 docker-machine kernel: fsnotify_mark D ffff880fd4993c88 0 135 2 0x00000000
Apr 2 22:49:06 docker-machine kernel: ffff880fd4993c88 ffff880fdf597648 ffff880fd8375900 ffff880fd4994000
Apr 2 22:49:06 docker-machine kernel: ffff880fd4993dd8 ffff880fd4993dd0 ffff880fd8375900 ffff880fd4993e40
Apr 2 22:49:06 docker-machine kernel: ffff880fd4993ca0 ffffffff81700085 7fffffffffffffff ffff880fd4993d50
Apr 2 22:49:06 docker-machine kernel: Call Trace:
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700085>] schedule+0x35/0x80
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81702d97>] schedule_timeout+0x237/0x2d0
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81062aee>] ? kvm_clock_read+0x1e/0x20
Apr 2 22:49:06 docker-machine kernel: [<ffffffff81700b81>] wait_for_completion+0xf1/0x130
Apr 2 22:49:11 docker-machine kernel: INFO: task java:12560 blocked for more than 120 seconds.
Apr 2 22:49:11 docker-machine kernel: Not tainted 4.4.108-1.el7.elrepo.x86_64 #1
Apr 2 22:49:11 docker-machine kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Apr 2 22:49:11 docker-machine kernel: java D ffff880bfbdc7b00 0 12560 4206 0x00000180
Apr 2 22:49:11 docker-machine kernel: ffff880bfbdc7b00 ffff880bfbdc7b40 ffff880bfbdac2c0 ffff880bfbdc8000
Apr 2 22:49:11 docker-machine kernel: ffff8809beb142d8 ffff8809beb14200 0000000000000000 0000000000000000
Apr 2 22:49:11 docker-machine kernel: ffff880bfbdc7b18 ffffffff81700085 ffff880b155adfc0 ffff880bfbdc7b98
Apr 2 22:49:11 docker-machine kernel: Call Trace:
Apr 2 22:49:11 docker-machine kernel: [<ffffffff81700085>] schedule+0x35/0x80
Apr 2 22:49:11 docker-machine kernel: [<ffffffff8124ca55>] fanotify_handle_event+0x1b5/0x2f0
Apr 2 22:49:11 docker-machine kernel: [<ffffffff810c2b50>] ? prepare_to_wait_event+0xf0/0xf0
Apr 2 22:49:11 docker-machine kernel: [<ffffffff8124933f>] fsnotify+0x26f/0x460
Apr 2 22:49:11 docker-machine kernel: [<ffffffff810a1fd1>] ? in_group_p+0x31/0x40
Apr 2 22:49:11 docker-machine kernel: [<ffffffff812111fc>] ? generic_permission+0x15c/0x1d0
Apr 2 22:49:11 docker-machine kernel: [<ffffffff812b355b>] security_file_open+0x8b/0x90
Apr 2 22:49:11 docker-machine kernel: [<ffffffff8120484f>] do_dentry_open+0xbf/0x320
Apr 2 22:49:11 docker-machine kernel: [<ffffffffa02cb552>] ? ovl_d_select_inode+0x42/0x110 [overlay]
Apr 2 22:49:11 docker-machine kernel: [<ffffffff81205e15>] vfs_open+0x55/0x80
Apr 2 22:49:11 docker-machine kernel: [<ffffffff81214143>] path_openat+0x1c3/0x1300
查看日志,觉得很大可能性是: cache 落盘故障,有可能是 io 的问题。通过 iotop 进行排查,未发现异常。
当时我们认为是 腾讯云底层存储或者网络出现问题导致的。
在排查了近一个小时,机器上面的cpu 还是没有降低。我们对机器进行了重启。重启后,一些恢复了正常。
二、 问题解析
-
认为是存储的问题
首先上面的故障是同时出现在两台机器(A和B)的, 询问腾讯云 A 的系统盘和A的数据盘以及B的数据盘都是在同一个远端存储的,所以这更加深了我们认为是存储导致的问题,有可能是到物理机到存储之间的网络,也有可能是存储本身的性能问题。
腾讯云排查后说这两个机器,所用的存储和存储网络没有问题,所以存储问题不成立。
-
系统的僵尸进程很多
在上面top 命令我们可以看到有僵死进程,后面也是一直在增加僵死进程。
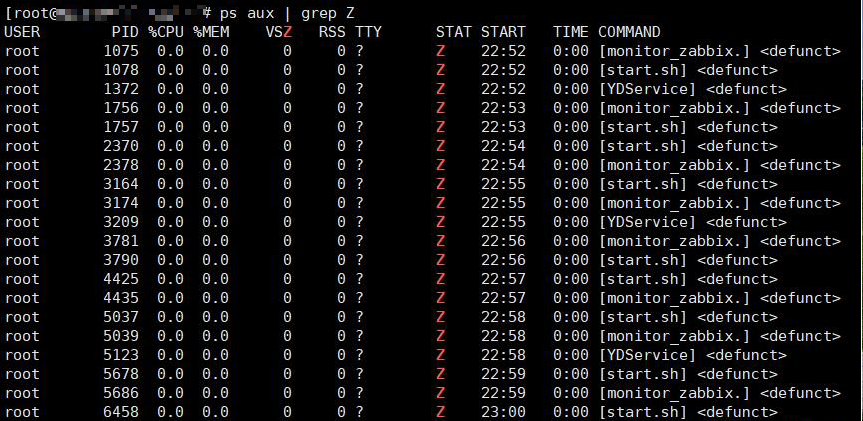
僵死进程的来源:
- 上面的僵死进程来源是我们的定时任务导致的,我们定时任务脚本执行的进程变成的僵死进程。
如何看僵死进程
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' -
/var/log/message 异常信息
我们再看看
/var/log/message的日志,我们可以看到一个很关键的信息kernel: INFO: task systemd:1 blocked for more than 120 seconds.网上大多数时是说
vm.dirty_ratio和vm.dirty_background_ratio这两个参数设置的有问题。我们查看了我们这两个内核参数的配置,都是正常合理的。
$ sysctl -a|grep -E 'vm.dirty_background_ratio|vm.dirty_ratio' vm.dirty_background_ratio = 10 # vm.dirty_ratio = 30具体的参数详解,见下文。
-
我们再看看
/var/log/message的日志,我们可以看到一个很关键的信息Apr 2 22:45:22 docker-machine systemd: Reloading. Apr 2 22:49:06 docker-machine kernel: INFO: task systemd:1 blocked for more than 120 seconds. Apr 2 22:49:06 docker-machine kernel: systemd D ffff880fd8bebc68 0 1 0 0x00000000 Apr 2 22:49:06 docker-machine kernel: INFO: task fsnotify_mark:135 blocked for more than 120 seconds. Apr 2 22:49:06 docker-machine kernel: fsnotify_mark D ffff880fd4993c88 0 135 2 0x00000000 Apr 2 22:49:11 docker-machine kernel: INFO: task java:12560 blocked for more than 120 seconds. Apr 2 22:49:11 docker-machine kernel: java D ffff880bfbdc7b00 0 12560 4206 0x00000180就是
systemd在Reloading,systemd和fsnotify_mark都被block了,那么被锁了原因是什么,按道理来说应该io的问题啊,就是写得慢啊,但是我们忽略了一个问题,如果要写的文件加锁了,那么也是会出现这个情况的啊。寻找加锁的原因: 腾讯云主机安全产品 云镜, 没错就很大可能性是它导致的。 具体内容见下文。
三、问题原因
为什么会定位到云镜产品,首先是我们认为如果底层 io 没有问题的话,那么就只能是文件可能被锁了,并且如果你细心的话,你会发现僵死进程里面,有云镜的身影
为什么云镜会变成僵死进程,是因为云镜启动失败了,一直在启动。
我们再说回为什么会定位到云镜上面,主要是因为云镜会对系统上文件有定期扫描的,为什么会想到就是安全产品(https://access.redhat.com/solutions/2838901)。 安全产品就是云镜。
我们观察云镜的日志,我们又发现了一个问题,原来在 22:45 左右,云镜在更新,这个很巧合啊,我们出问题的两个机器都在这个时间段进行了更新,而没有异常的机器,都没有更新操作。
-
云镜更新的日志
-
更新后一直没有云镜一直启动失败
-
redhat官方文档也是说到安全产品会可能触发这个问题。
最终让腾讯云排查云镜此次版本升级,得到答复:
推测YDService在exit group退出的时未及时对fanotify/inotify进行适当的清理工作,导致其它进程阻塞等待,因此针对此点进行了优化。
问题1: 针对为什么只有两台机器在那个时间点进行更新,是因为那个云镜后端调度策略是分批升级。
进程的几种状态
https://liam.page/2020/01/10/the-states-of-processes-on-Linux/
进程通常处于以下两种状态之一:
-
在 CPU 上执行(此时,进程正在运行) 在
ps或是top中,状态标识为R的进程,即处于正在运行状态。 -
不在 CPU 上执行(此时,进程未在运行)
未在运行的进程可能处于不同状态:
-
可运行状态 (R)
进程获取了所有所需资源,正等待 CPU 时,就会进入可运行状态。处于可运行状态的进程在
ps的输出中,也已R标识。举例来说,一个正在 I/O 的进程并不立即需要 CPU。当进程完成 I/O 操作后,就会触发一个信号,通知 CPU 和调度器将该进程置于运行队列(由内核维护的可运行进程的列表)。当 CPU 可用时,该进程就会进入正在运行状态。
-
可中断之睡眠状态 (S)
可中断之睡眠状态表示进程在等待时间片段或者某个特定的事件。一旦事件发生,进程会从可中断之睡眠状态中退出。
ps命令的输出中,可中断之睡眠状态标识为S。 -
不可中断之睡眠状态(D)
不可中断之睡眠状态的进程不会处理任何信号,而仅在其等待的资源可用或超时时退出(前提是设置了超时时间)。
不可中断之睡眠状态通常和设备驱动等待磁盘或网络 I/O 有关。在内核源码
fs/proc/array.c中,其文字定义为"D (disk sleep)", /* 2 */。当进程进入不可中断之睡眠状态时,进程不会处理信号,而是将信号都积累起来,等进程唤醒之后再处理。在 Linux 中,ps命令使用D来标识处于不可中断之睡眠状态的进程。系统会为不可中断之睡眠状态的进程设置进程运行状态为:
p->state = TASK_UNINTERRUPTABLE;由于处于不可中断之睡眠状态的进程不会处理任何信号,所以
kill -9也杀不掉它。解决此类进程的办法只有两个:- 对于怨妇,你还能怎么办,只能满足它啊:搞定不可中断之睡眠状态进程所等待的资源,使资源可用。
- 如果满足不了它,那就只能 kill the world——重启系统。
-
僵死状态(Z)
进程可以主动调用
exit系统调用来终止,或者接受信号来由信号处理函数来调用exit系统调用来终止。当进程执行
exit系统调用后,进程会释放相应的数据结构;此时,进程本身已经终止。不过,此时操作系统还没有释放进程表中该进程的槽位(可以形象地理解为,「父进程还没有替子进程收尸」);为解决这个问题,终止前,进程会向父进程发送SIGCHLD信号,通知父进程来释放子进程在操作系统进程表中的槽位。这个设计是为了让父进程知道子进程退出时所处的状态。子进程终止后到父进程释放进程表中子进程所占槽位的过程,子进程进入僵尸状态(zombie state)。如果在父进程因为各种原因,在释放子进程槽位之前就挂掉了,也就是,父进程来不及为子进程收尸。那么,子进程就会一直处于僵尸状态。而考虑到,处于僵尸状态的进程本身已经终止,无法再处理任何信号,所以它就只能是孤魂野鬼,飘在操作系统进程表里,直到系统重启。
在前面的日志中,也就是下面:
Apr 2 22:49:06 docker-machine kernel: systemd D ffff880fd8bebc68 0 1 0 0x00000000 Apr 2 22:49:06 docker-machine kernel: INFO: task fsnotify_mark:135 blocked for more than 120 seconds. Apr 2 22:49:06 docker-machine kernel: fsnotify_mark D ffff880fd4993c88 0 135 2 0x00000000我们部分进程处于
不可中断之睡眠状态(D), 在这个状态的服务,前面也说到只能给他资源,或者重启系统。 也就可以说明:解释疑问:
-
为什么我们故障机器上面部分服务存在问题,部分服务正常。
因为部分进程处于
不可中断之睡眠状态(D)。文件(linux一切皆文件)被锁,导致了部分服务进程进入了不可中断睡眠状态。
-
如何快速清理僵尸进程(Z)
用top查看系统中的僵尸进程情况
top
再看看这些僵尸是什么程序来的
ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]'
kill -s SIGCHLD pid (父进程pid)
内核参数相关
- dirty_background_ratio 指当文件系统缓存脏页数量达到系统内存百分之多少时(默认10%)唤醒内核的 flush 等进程,写回磁盘。
- dirty_ratio 为最大脏页比例,当脏页数达到该比例时,必须将所有脏数据提交到磁盘,同时所有新的 IO 都会被阻塞,直到脏数据被写入磁盘,通常会造成 IO 卡顿。系统先会达到
vm.dirty_background_ratio的条件然后触发 flush 进程进行异步的回写操作,此时应用进程仍然可以进行写操作,如果达到vm.dirty_ratio这个参数所设定的值,此时操作系统会转入同步地处理脏页的过程,阻塞应用进程。
如何查看哪些文件被哪些进程被锁
cat /proc/locks
1: POSIX ADVISORY WRITE 3376 fd:10:805736756 0 EOF
2: FLOCK ADVISORY WRITE 1446 00:14:23843 0 EOF
3: FLOCK ADVISORY WRITE 4650 00:14:32551 0 EOF
4: POSIX ADVISORY WRITE 4719 fd:01:531689 1073741824 1073742335
5: OFDLCK ADVISORY READ 1427 00:06:1028 0 EOF
6: POSIX ADVISORY WRITE 4719 00:14:26155 0 EOF
7: POSIX ADVISORY WRITE 4443 00:14:26099 0 EOF
8: FLOCK ADVISORY WRITE 4561 00:14:34870 0 EOF
9: POSIX ADVISORY WRITE 566 00:14:15509 0 EOF
10: POSIX ADVISORY WRITE 4650 fd:01:788600 0 EOF
11: OFDLCK ADVISORY READ 1713 00:06:1028 0 EOF
12: FLOCK ADVISORY WRITE 1713 fd:10:268435553 0 EOF
13: FLOCK ADVISORY WRITE 1713 fd:10:268435528 0 EOF
14: POSIX ADVISORY WRITE 12198 fd:01:526366 0 EOF
15: POSIX ADVISORY WRITE 3065 fd:10:805736741 0 EOF
16: FLOCK ADVISORY WRITE 1731 fd:10:268435525 0 EOF
17: FLOCK ADVISORY WRITE 4459 00:14:37972 0 EOF
18: POSIX ADVISORY WRITE 1444 00:14:14793 0 EOF
我们可以看到/proc/locks下面有锁的信息:我现在分别叙述下含义:
-
POSIX FLOCK这个比较明确,就是哪个类型的锁。flock系统调用产生的是FLOCK,fcntl调用F_SETLK,F_SETLKW或者lockf产生的是POSIX类型,有次可见两种调用产生的锁的类型是不同的; -
ADVISORY表明是劝告锁;
-
WRITE顾名思义,是写锁,还有读锁;
-
18849 是持有锁的进程ID。当然对于flock这种类型的锁,会出现进程已经退出的状况。
-
08:02:852674表示的对应磁盘文件的所在设备的主设备好,次设备号,还有文件对应的inode number。 -
0 表示的是所的其实位置
-
EOF表示的是结束位置。 这两个字段对fcntl类型比较有用,对flock来是总是0 和EOF。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK