

从微秒到纳秒:关于性能的奇妙旅程
source link: https://zhuanlan.zhihu.com/p/365905187
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
从微秒到纳秒:关于性能的奇妙旅程
在上文:《胖客户端,瘦服务器》中,我们描述了一个从客户端收集事件,排序和存储事件的架构:
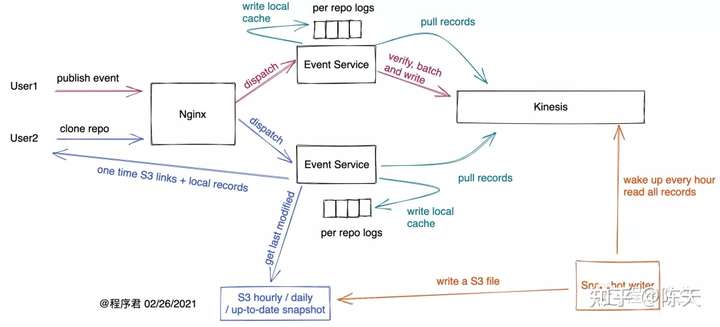
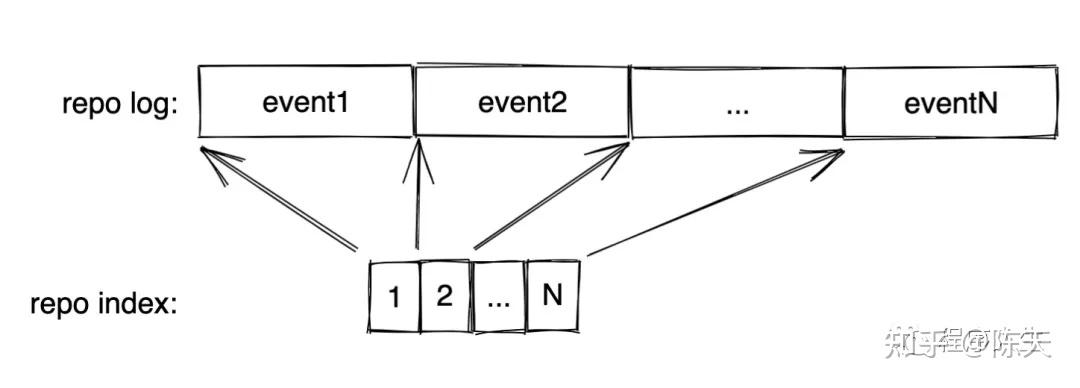
在这其中,比较有挑战的工作是如何构建一个足够高性能的带索引的 append only log。之前我拍脑门设计了这样的结构:
为了让磁盘的读写不成为瓶颈,我没有尝试建立缓冲区写文件的道路,而是直接使用了 mmap [1]。mmap 有它安全上的风险,但如果是本文描述的记录和存储事件的场景,安全问题还好。mmap 最让人心动的是,如果日志的索引或者日志本身既有读者又有写者,且它们分别在不同的进程,两者其实可以共享同一片物理内存(如果使用 MAP_SHARED),这样即节省了内存开销,读者还可以直接获得写者的更新。不过要注意一点:如果写者扩展了映射的内存区域(比如日志文件写满,需要扩容,做了 resize,然后又 remap),读者是不知道的,这个时候需要写者和读者同步一下。
在 Rust 下,mmap 的实现(主要是对 libc 对应函数的封装)有 prost 库作者 Danburkert 实现的 memmap-rs[2],不过这老哥精力估计都放在 prost 上面,没怎么维护这个库了(虽然,mmap 也没什么需要维护的)。我使用的 memmap2-rs [3],是 resvg 作者 RazrFalcon fork memmap 并维护的一个版本。
考虑到随着数据量的增加,每个 repo 下的日志文件需要不断拆分,因而如果创建一个对于 repo 来说全局的索引,那么每个 IndexEntry 里需要至少携带:
- filer_id:32bit 的正整数,对应这个事件在哪个日志文件中(0.log, 1.log, ...)
- pos:32bit 的正整数,对应这个事件在日志文件的哪个位置(因此,单个日志文件不能超过 4GB)
这样,一个有 1M 事件的 repo,索引的大小是 8M 多一点点。我们需要相同容量的内存来做 mmap。为了方便知道索引中有多少项,以及未来该怎么扩容,我们需要为索引定义一个文件头,它包含这些信息:
- magic number:简单校验文件
- total:目前写到第几项
- max:文件最大有多少项。如果 total ≥ max,则说明我们需要对其扩容。
- crc:为了更严谨起见,还应该为文件算一个 crc 校验,这个我没有加。
根据这些需求,最终索引文件长这个样子:
那位问了:为什么每个 IndexEntry 不添加一个字段描述事件的长度?好问题。记录长度有几种方法:
- IndexEntry 除了 file 和 pos 外,再加一个 32bit 的 len。但这样每个 IndexEntry 就不是 64bit 对齐了,在 64 位 CPU 略有性能损失。此外,1M index 的大小就是 12M,多出 50% 的大小。
- IndexEntry 里 file 和 len 使用 16 bit,pos 还是 32 bit,这样文件大小并不增长,一个 repo 理论的总事件容量是 65536 (16bit)x 4G (32bit) = 256T,似乎足够了。但单个事件的长度不能超过 64k(照理我想不到有什么情况会这么大,但谁知道呢),这个限制可能会埋下对未来扩展的隐患。
- 在 log 文件中用 varint 来记录长度。这样索引中不用记录事件的长度,只需要事件的起始就可以。varint 我使用了 integer-encoding [4] 这个非常强大的 crate。
权衡再三,我选择了第三个方案。基于此,日志文件的结构如下:
日志文件简单一些,日志头除了 magic 外,就是这个日志文件目前写到哪(pos),而文件长度多长(size)。如果 pos + 要写入的数据长度 > size,那么就扩容。
有了这两个基本的设计,append(event) 操作就显而易见:
- 找到日志中 pos 指向的位置,写入 varint 长度和数据本身。写完后更新 pos。
- 找到索引中 total 指向的位置,记录写入的是哪个日志文件,以及写之前的 pos。写完后更新 total。
get(idx) 操作也很直观:
- 找到 idx 对应的 IndexEntry(
INDEX_HEADER + idx * ENTRY_SIZE),取出 file 和 pos - 找到对应的日志文件从 pos 里用 varint decode 出长度,然后读出整个 event
iterator 实现类似,这里就不赘述。
由于文件 mmap 后,拿到的就是一个容量很大的 &[u8],所以各种操作爽到飞起,全程零拷贝,比如需要修改某个 IndexEntry,可以直接 data.align_to_mut::<IndexEntry>(),然后就往里灌数据。效率高到不能更高了。
然而,这里有一个待解决的问题:什么时候把 mmap 内存中修改的数据刷到磁盘上?间隔太短会影响性能,间隔太长万一进程崩溃,丢失的数据就太多(linux 4 以后支持 MAP_SYNC,理论上可以在崩溃后依然把内存内容写入文件)。不管怎么说,我们需要一定的刷新策略。我实现了一个简单的刷新策略:在配置文件中配置 flush size,比如 1024,那么每写入 1024 项,就会刷新一下索引文件和当前日志文件。
这会带来一个新的问题:每次刷新会急剧拉低整体的性能。
这是因为,对 mmap 的无脑刷新会导致 mmap 的所有内存页面被刷新到硬盘。我本以为 mmap 会更聪明一些,看看哪些页面是 dirty 再真正去刷新,但实际不是。由于我们写入的文件都是 append only 的,除了文件头,刷新过的部分就不会修改,因此就无需重新刷新。所以,我们只需要额外记录一下上次刷新到哪个位置,这样,刷新的时候只需要刷文件头(因为一直在修改),以及上次刷新的位置到当前写入的位置即可。做了这个调整后,写入性能急剧提升。我使用 criterion.rs [5] 做了这么几组 benchmark(所有刷新策略都是写入 1024 个事件就刷新一下):
- 在 index 中查找 1024 次数据:和优化无关,所以没有变化,1024 次查询 6.6us 左右(单次查询 6ns 左右)
- 在 index 中写入 1024 个 Index Entry:时间从 2.6ms 直线下降到 200us(单次写入小于 200ns)
- 在 log 中写入 122 字节大小的事件:时间从 10.5us 直线下降到 350ns
- 在 log 中写入 16373 字节大小的事件:时间从 107us 直线下降到 19us所有 benchmark 均使用 criterion.rs 完成(warm 3s,benchmark 5s)。
随后,我又做了一些其它的优化和功能上的增减(比如代码上对 Writer / Reader 做了分离,日志支持了 varint,以及把索引和日志结合起来提供完整方案的 logger),并没有明显变化:
在真实的使用场景中,添加一条事件,会写入日志和索引,所以 benchmark 把索引和日志结合起来提供完整方案的 logger 更有意义。根据上图,Logger 一次 append 1k 左右的数据,大概需要 1.59us,这意味着单核每秒钟可以写入 630k 条日志,或者 630MBps(我的 mbp 2019 SSD 写入速度在 2.6GBps 左右),而 append 16k 左右的数据,需要 18.3us,大概每秒 55k 条日志,或者约 900MBps。
这个设计存在一个架构上的问题 — 索引文件会随着日志数量的增加而不断增大。当 repo 中有 1M 条事件时,索引占用的内存将达到 8M,加上每个 repo 当前正在写入的日志(假设每 4M 我们 rotate 一次日志文件,内存中每个 repo 就会有 4M 日志 mmap 的内存),这样一共是 12M。乍一看这似乎没什么,占用内存很小啊,但如果同一台机器上要处理 1000 个活跃 repo 的数据(每个 repo 平均有 1M 条事件),内存的消耗就在 12G。如何在保持相同的读写性能的情况下,降低内存的消耗呢?
为了在同一台机器支持更多的 repo,我们需要索引文件也能够和日志文件同步 rotate,这样,我们可以降低索引文件的内存消耗。但如果这么做,我们何不干脆将二者合二为一呢?
于是我便有了下面的设计:
每个 IndexEntry 现在只需要 32bit 记录本文件中的开始位置。我们在日志文件创建的时候,就规定好一个日志文件容量有多少项,到达上限后,就不再增长,直接 rotate。假设我们每个日志文件规定 max = 8192,那么当 total = 8192 时,这个日志就被关闭,新的日志写到下一个文件中。
按照这样的 max,整个文件头是 128bit + 32bit * 8192 = 32784B。如果平均一个事件 512 字节,那么整个文件长度 4M 多一点。这也是一个 repo 占用内存最多的时候(因为除了一开始的 32k,后面的大小可以逐渐增长,但最大到 8192 条事件)。所以当系统里要处理 1000 个活跃的 repo 的数据时,内存占用是 4G,是之前方案的 1/3。
我们通过文件头限定 max 16 bit 来限制单个日志文件的最大条目数不超过 65536。这样,单个日志文件的长度可控,又有一定的灵活性。
此外,由于 index 的大小在 max 确定就确定好了,所以和之前的方案比,我们省去了 index grow 的时间。
下图单独比较旧的 logger 和新的 logger 的性能差异(上面那个图也有新的 logger,但不好对比看),可以看到,新的 logger 性能略微好一些:
进一步地,我在新 logger 的基础上做了 LTO[6],进一步提升了性能。我也尝试了使用 jemalloc[7],但没有效果(因为主要的操作都在 mmap 的内存中完成,没有什么堆上的分配),所以没有使用 jemalloc。这样一来,一次 append 1k 左右的数据,新 logger + LTO 仅需要 1.41us,提升了 11%。
到目前为止,所有测试还是单核单 repo。
那位问了,这看上去很好,但是,如何将其应用在真正的生产环境下(多核多线程多机器)?
多机器我们先放在一边。只要我们的 load balancing 策略保证一个 repo_id 只分配到一台机器,那么剩下的事情就是:我们如何在单机上把请求 dispatch 到多个工作线程上?
为了让要解决的问题简单一些,我们先做一些限制:每个 LoggerWriter 只能被一个线程访问。那么,我们只需要做 repo_id 到 N 个工作线程的映射即可。这可以用任何一个 hash 函数完成 — 我使用了 Ahash [8]。Ahash 是目前最快的哈希算法(注意:非加密算法的哈希),普遍用在 HashMap 的实现中(比如 hashbrown)。
那么,如何把某个 repo_id 的数据,发送给对应的工作线程呢?
在 Rust 里,解决方案很简单:channel。我没用标准库自带的 channel,而是使用了 crossbeam_channel[9]。它的性能比标准库的好不少[10],使用方法一致:
我们只需要创建 N 个 channel,把每个 channel 的 receiver move 给工作线程,sender 装到一个 Vec 里,保存在 LoggerServer 结构中。当某个 repo_id 下的事件到达 server,server 将其 hash 然后 mod N,到 Vec 里找到对应的 sender,通过 ender 将数据发送到 channel,然后对应的线程死循环从 channel 的 receiver 里取出数据,找到 hash table(使用 hashbrown[11]) 里 repo_id 对应的 Logger,然后 append。整个过程如下:
从这段描述我们可以看到整个过程虽然清晰,但似乎不好实现。其实不然,我只用了不到 50 行代码就实现了上图中的逻辑(见图中附带的代码),可见 Rust 的强大。
用 channel 做线程间的同步,数据的分发非常强大,但这涉及到一个问题:究竟我们该用 unbounded channel,还是 bounded channel,如果后者,那么这个容量究竟多大为好?
我的回答是:生产环境下不要用 unbounded。你需要通过 channel 来做 backpressure,降低生产者发送数据的速度。这样,不至于过于疯狂的生产者产生大量数据积压在 channel 中,最终导致内存耗尽。
那么,究竟多大的 channel size 合适呢?这需要做足够的 benchmark。
我还是继续使用 criterion 做 benchmark,然而,criterion 在预热数据后会关闭我在 server.start() 时创建的线程,然后重新建立,导致 channel 发送出问题,所以无法正常测试,我只好使用了 #![feature(test)] 来做 benchmark,这有两个问题:1) criterion 计算的数据统计学上更准确,test::bench 不那么好。2) 这个只能用 nightly 编译。然而这是唯一的选择。
我试验了 1,1024,8192,32768 和 1048576 这些不同的容量的表现(server 使用了 8 个线程),最后发现,32k 大小的 channel 性能足够好。8 个线程所有 channel 积压满,每个事件如果 1k 大小,那么积压的事件占用的内存是 32 x 8k x 1k = 256M,不成问题:
在这个测试中,我还对比了 unbounded。使用 unbounded 的话,每个事件的处理是 bug 级别的 400ns-600ns!仔细思考一下,我们可以认为这个测试并没有反应真实情况,它实际测试的是往 channel 里发送数据的速度,而不是处理速度 — 因为数据可以在 unbounded channel 中无限积压,不必等待 receiver 处理。但这个测试告诉我们:往 channel 里写入数据的速率可以达到 2.5M/s!这就是 Rust 的威力。
我还好奇线程多寡对性能的影响究竟有多大,于是在 32k 这个 channel size 上,又实验了 1 个线程(32768_1t)和 16 个线程(32768_16t)的情况,测试结果看 1 个线程不负众望,比多线程表现差,而 8 个线程表现比 16 个线程还更好,但总体差别不大。这个我觉得是 benchmark 自己还需要多线程运行来测试,所以工作线程用满了反而导致整体性能下降。
如果我们把多线程 server 和之前单线程的 new logger + LTO 的数据放在一起(因为使用不同的 benchmark 工具,所以结果并不完全精确),我们可以看到,数据很小的时候(122 字节和 253 字节),不使用多线程的方案效率更好(因为 channel send 就占用了 400ns 的时间),但数据大于 1k 时,多线程方案显示出了卓越的性能。
在 16k 事件大小的情况下,8 线程,1m channel size,每个事件处理时间只有 6.703us,换算成写入速度,达到了 2.39GBps,几乎达到了我 mbp 的 SSD 能力上限(2.6GBps)。即便 32k channel size,每个事件也只需要 8.575us,或者说 1.87GBps 的写入速度,和之前计算的单线程写入速度相比,提升了一倍多。
如果仅仅从效率的提升来看,似乎收益不成比例(2:8),但通过额外短短几十行代码就能达到这样的效果,而且可以处理多个 repo 的数据,还是相当 NB 的。
以上图形是把如下的 cargo bench 的结果整理出来:
running 28 tests
test bench_server_dispatch_16t_32768_1013 ... bench: 1,166 ns/iter (+/- 715)
test bench_server_dispatch_16t_32768_122 ... bench: 977 ns/iter (+/- 1,012)
test bench_server_dispatch_16t_32768_16373 ... bench: 8,835 ns/iter (+/- 23,716)
test bench_server_dispatch_16t_32768_253 ... bench: 1,278 ns/iter (+/- 1,013)
test bench_server_dispatch_1t_32768_1013 ... bench: 2,093 ns/iter (+/- 863)
test bench_server_dispatch_1t_32768_122 ... bench: 961 ns/iter (+/- 312)
test bench_server_dispatch_1t_32768_16373 ... bench: 25,934 ns/iter (+/- 12,855)
test bench_server_dispatch_1t_32768_253 ... bench: 1,101 ns/iter (+/- 864)
test bench_server_dispatch_8t_0_1013 ... bench: 3,039 ns/iter (+/- 945)
test bench_server_dispatch_8t_0_122 ... bench: 2,234 ns/iter (+/- 3,355)
test bench_server_dispatch_8t_0_16373 ... bench: 14,030 ns/iter (+/- 63,776)
test bench_server_dispatch_8t_0_253 ... bench: 2,460 ns/iter (+/- 2,800)
test bench_server_dispatch_8t_1024_1013 ... bench: 1,095 ns/iter (+/- 945)
test bench_server_dispatch_8t_1024_122 ... bench: 1,013 ns/iter (+/- 207)
test bench_server_dispatch_8t_1024_16373 ... bench: 8,586 ns/iter (+/- 16,483)
test bench_server_dispatch_8t_1024_253 ... bench: 994 ns/iter (+/- 86)
test bench_server_dispatch_8t_1m_1013 ... bench: 580 ns/iter (+/- 185)
test bench_server_dispatch_8t_1m_122 ... bench: 1,122 ns/iter (+/- 1,445)
test bench_server_dispatch_8t_1m_16373 ... bench: 6,703 ns/iter (+/- 4,665)
test bench_server_dispatch_8t_1m_253 ... bench: 641 ns/iter (+/- 1,120)
test bench_server_dispatch_8t_32768_1013 ... bench: 1,230 ns/iter (+/- 839)
test bench_server_dispatch_8t_32768_122 ... bench: 908 ns/iter (+/- 347)
test bench_server_dispatch_8t_32768_16373 ... bench: 8,575 ns/iter (+/- 14,662)
test bench_server_dispatch_8t_32768_253 ... bench: 926 ns/iter (+/- 593)
test bench_server_dispatch_8t_8192_1013 ... bench: 805 ns/iter (+/- 493)
test bench_server_dispatch_8t_8192_122 ... bench: 948 ns/iter (+/- 264)
test bench_server_dispatch_8t_8192_16373 ... bench: 9,974 ns/iter (+/- 20,120)
test bench_server_dispatch_8t_8192_253 ... bench: 1,028 ns/iter (+/- 457)
test result: ok. 0 passed; 0 failed; 0 ignored; 28 measured; 0 filtered out; finished in 138.70s之后写入 csv,最后用 pandas + altair 绘制而成。
One more thing
那位又问了:万一不小心另一个应用程序打开了日志文件改写,怎么办?会不会造成当前的 LoggerWriter 出问题?
当然会出问题。所以我们需要文件锁 — flock [12]。这是 libc 的一个功能,然而并没有对应的 crate。我借用了 cargo 源代码的 flock 实现 [13]。
我曾经是一个 C 程序员,在 Juniper CNRD 的六年多时光里,徜徉在指针,哈希表,各种同步原语,各种网络协议,各种硬件 spec 的海洋,和四种不同的 CPU 的 ABCI 打交道,为了艾泽拉斯那不起眼的几十个字节,我一个 bit 一个 bit 扣内存,为了在一次中断中处理更多的报文,我想方设法在 mips branch delay cycle 塞入一个有意义的语句。ager ring,mpmc,rb tree,radix tree 都是我们常挂在嘴边的数据结构,在微秒级以内处理数据,是天经地义的使命。然而,在我随后的互联网生涯中,这一切都成了过去。毫秒级别完成一次请求,毫无压力,反正可以加机器;管它数据结构不数据结构,有状态就交给数据库;内存优化?拜托,我连我自己的系统为啥吃掉那么多内存都不知道,你让我一个 bit 一个 bit 优化?
幸而有了 Rust,我可以在实现高级别抽象的业务逻辑的同时,还能关注底层性能;幸而有了 Rust,我可以拾起封存了多年的对底层的认知,上下求索,而无需忍受写 C 的诸多折磨。为了开发这个小项目,我花了差不多一周的时间,每天晚上 8 点写到将近 12 点,加上周末,终于有些样子。
从微秒到纳秒的这个奇妙旅程,让我仿佛又回到了 2006 年,那夜以继日地研究 ScreenOS flow 代码的 good old days。
程序员致敬 good old days 最好的方法,自然是写上一些和 good old days 有关的代码。
谨以此文献给培养了我的 Juniper CNRD。2004-2021。
[1] mmap: https://man7.org/linux/man-pages/man2/mmap.2.html
[2] memmap-rs:https://github.com/danburkert/memmap-rs
[3] memmap2-rs: https://docs.rs/memmap2/0.2.1/memmap2/
[4] integer-encoding-rs: https://github.com/dermesser/integer-encoding-rs
[5] criterion: https://github.com/bheisler/criterion.rs
[6] LTO:https://doc.rust-lang.org/cargo/reference/profiles.html#lto
[7] jemalloc:https://github.com/gnzlbg/jemallocator
[8] Ahash: https://github.com/tkaitchuck/aHash
[9] crossbeam-channel: https://docs.rs/crossbeam-channel/0.5.0/crossbeam_channel/
[10] crossbeam-benchmark: https://github.com/crossbeam-rs/crossbeam/tree/master/crossbeam-channel/benchmarks
[11] hashbrown: https://github.com/rust-lang/hashbrown
[12] flock: https://linux.die.net/man/2/flock
[13] cargo flock: https://github.com/rust-lang/cargo/blob/master/src/cargo/util/flock.rs
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK