
3

配置高可用K3s集群完全攻略
source link: http://dockone.io/article/2434107
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在本文中,我们将简要介绍在高可用性(HA)配置中设置K3s的参考架构。这意味着你的K3s集群可以容忍故障,并保持启动和运行,为你的用户提供流量。你的应用程序也应该针对高可用性进行构建和配置,但这部分内容不在本文的范围内。
在本教程中,我们将使用CLI工具在DigitalOcean上配置一个HA K3s集群。我们将使用MySQL进行数据存储,并使用TCP负载均衡器为Kubernetes API server提供一个稳定的IP地址。
那么,为什么我们需要高可用?我们可以创建的K3s集群是通过在一个有公共IP地址的虚拟机上部署一个K3s server。不幸的是,如果该虚拟机崩溃,我们的应用程序将会发生故障。通过添加多个server并配置它们协调工作,可以使得集群容忍一个或多个节点的故障。这就是所谓的高可用性。
控制平面的高可用性
对于K3s 1.19版本来说,以下两种方法都可以实现高可用:- SQL数据存储:SQL数据库可以用于存储集群状态,但SQL数据库也必须在高可用配置下运行才有效。
- 嵌入式etcd:与Kubernetes的传统配置方式最为类似,需要使用诸如kops和kubedam等工具
API Server的高可用
Kubernetes API server配置为端口 6443 的 TCP 流量。外部流量(如来自kubectl客户端的流量)使用KUBECONFIG文件中的IP地址或DNS条目连接到API server。该配置引入了我们所有server之间的TCP负载均衡器的需求,因为如果我们使用其中一台server的IP地址,这台server崩溃,我们将无法使用kubectl。Agent也是如此,需要连接到某个IP地址和端口6443的server上才能与集群通信。
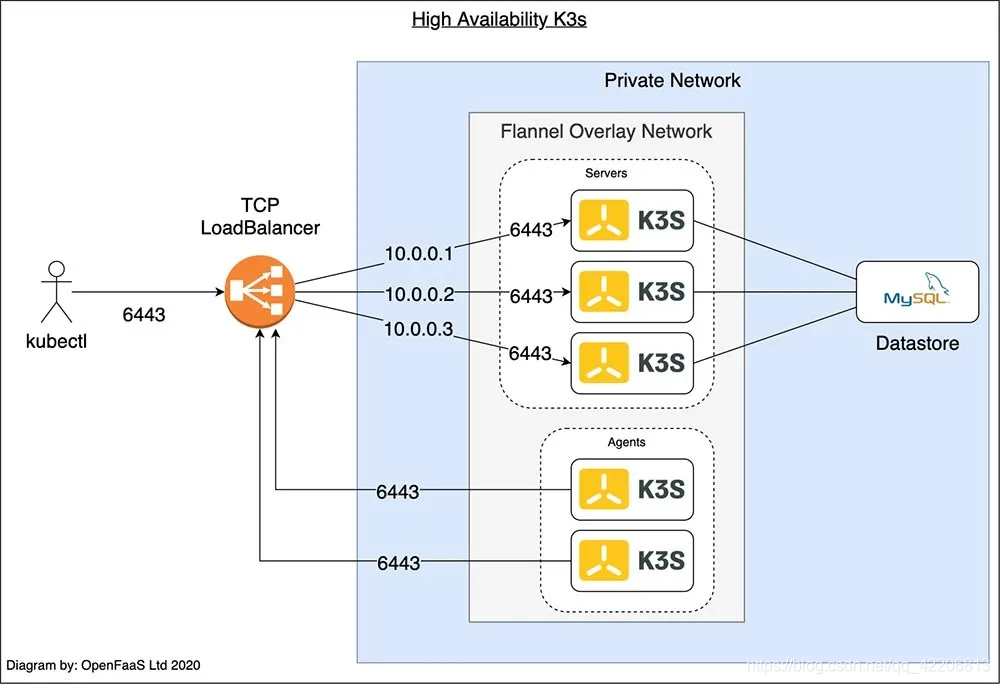
在上图中,运行kubectl的用户和两个agent都连接到TCP 负载均衡器。负载均衡器使用私有IP地址列表来平衡三个server之间的流量。如果其中一个server崩溃,它将从IP地址列表中删除。
Server使用SQL数据存储来同步集群的状态。
你也许需要一个DigtalOcean的账号来进行以下步骤,不过以下大多数内容也可以从其他云提供商中获取,此前我们发布过一篇使用阿里云进行K3s高可用的教程,欢迎你参考:
- 3个VM作为K3s server运行
- 2个VM作为K3s agent运行
- 托管的MySQL服务
- 托管的TCP 负载均衡器
这些说明需要与Windows上的Git Bash,MacOS Terminal,WSL1或2或Linux Terminal等终端一起运行。
确保您已下载并安装:
- DigitalOcean CLI (doctl)
- Kubernetes CLI (kubectl)
- K3sup:一个被广泛使用的开源工具,用于通过SSH安装K3s
Arkade:https://github.com/alexellis/arkade
brew:https://brew.sh/
如果你使用的是arkade,运行以下命令:
```
arkade get doctl
arkade get kubectl
arkade get k3sup
```
你安装了doctl之后,你需要在DigitalOcean的仪表盘上创建一个带有读写权限的API key,然后运行doctl auth init进行认证。
添加你的SSH key到你的Digital Ocean仪表盘上,然后查找SSH key的ID。当我们使用SSH来安装K3s时,我们需要使用它。
如果这是你第一次使用SSH key或者如果你想了解如何配置它们,你可以访问以下链接查看教程:
https://www.digitalocean.com/d ... keys/
现在列出你的SSH key并复制以下ID:
1. doctl compute ssh-key list
2. ID Name FingerPrint
3. 24824545 work e2:31:91:12:31:ad:c7:20:0b:d2:b1:f2:96:2a:22:da
运行以下命令:
export SSH_KEY='24824545'配置我们在教程中所需要的资源最简单的方式是使用DigitalOcean的仪表盘或CLI(doctl)进行配置。你完成了教程之后,你可能会需要使用类似Terraform的工具来自动化各种步骤。
你可以通过以下链接了解DigitalOcean的规模和区域选择:
https://www.digitalocean.com/d ... eate/
创建节点
创建三台服务器,内存为2GB,vCPU为1:
1. doctl compute droplet create --image ubuntu-20-04-x64 --size
s-1vcpu-2gb --region lon1 k3s-server-1 --tag-names k3s,k3s-server
--ssh-keys $SSH_KEY
2. doctl compute droplet create --image ubuntu-20-04-x64 --size
s-1vcpu-2gb --region lon1 k3s-server-2 --tag-names k3s,k3s-server
--ssh-keys $SSH_KEY
3. doctl compute droplet create --image ubuntu-20-04-x64 --size
s-1vcpu-2gb --region lon1 k3s-server-3 --tag-names k3s,k3s-server
--ssh-keys $SSH_KEY使用相同的配置创建2个worker:
1. doctl compute droplet create --image ubuntu-20-04-x64 --size
s-1vcpu-2gb --region lon1 k3s-agent-1 --tag-names k3s,k3s-agent
--ssh-keys $SSH_KEY
2. doctl compute droplet create --image ubuntu-20-04-x64 --size
s-1vcpu-2gb --region lon1 k3s-agent-2 --tag-names k3s,k3s-agent
--ssh-keys $SSH_KEY附带的标签会和负载均衡器一起使用,这样我们就不用指定节点IP了,以后如果需要的话可以增加更多的server。
创建负载均衡器
1. doctl compute load-balancer create --name k3s-api-server \
2. --region lon1 --tag-name k3s-server \ --forwarding-rules
3. entry_protocol:tcp,entry_port:6443,target_protocol:tcp,target_port:6443
\ --forwarding-rules
4. entry_protocol:tcp,entry_port:22,target_protocol:tcp,target_port:22
\ --health-check
5. protocol:tcp,port:6443,check_interval_seconds:10,response_timeout_seconds:5,healthy_threshold:5,unhealthy_threshold:3我们需要为Kubernetes API Server转发6443端口,22端口给k3sup稍后使用,以获取集群的”join token“。
这条规则将接收LB的IP上的传入流量,并将其转发到带有“k3s-server”标签的虚拟机上。
记下你获取的ID:
export LB_ID='da247aaa-157d-4758-bad9-3b1516588ac5'接下来,查找负载均衡器的IP地址:
doctl compute load-balancer get $LB_ID记下IP栏中的数值:
export LB_IP='157.245.29.149'配置一个托管的SQL数据库
```
doctl databases create k3s-data --region lon1 --engine mysql
```
以上命令将创建一个版本8的MySQL数据库。
你还会看到输出的URI与连接字符串,包括连接所需的密码。
```
- export
DATASTORE=mysql://doadmin:z42q6ovclcwjjqwq@tcpk3s-data-do-user-2197152- - 0.a.db.ondigitalocean.com:25060/defaultdb&sslmode=require"
要使用K3s,我们需要修改字符串如下:
export
DATASTORE='mysql://doadmin:z42q6ovclcwjjqwq@tcp(k3s-data-do-user-2197152-0.a.db.ondigitalocean.com:25060)/defaultdb' INSTALL_K3S_VERSION='v1.19.1+k3s1'我们移除了“?sslmode=require”后缀并在主机名和端口周围添加了tcp()。
启动集群
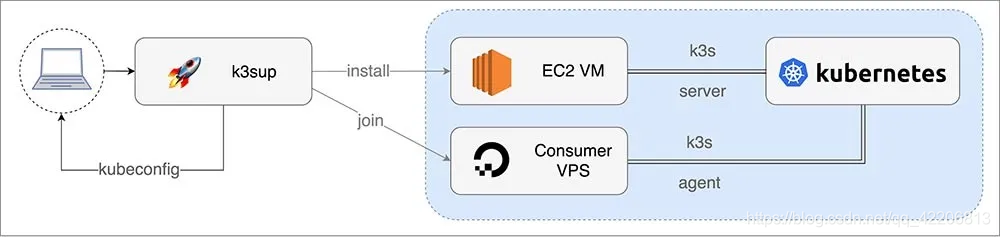
让我们使用k3sup来通过SSH启动K3s。
在k3sup中最重要的两个命令是:
- install:安装K3s到新server并为集群创建join token
- join:从server上获取“join token”,然后用它来安装k3s到agent上。
你可以通过运行:k3sup install --help 或 k3sup join --help 来找到这些标志和附加选项。
安装K3s到server
将channel设置到最新,撰写本文时最新版本为1.19
export CHANNEL=latest
在继续之前,请检查你的环境变量是否在之前被填充,如果没有请回溯并填充它们。
1. echo $DATASTORE
2. echo $LB_IP
3. echo $CHANNEL在下面的命令中,用Public IPv4一栏填写下面的IP地址:
1. doctl compute droplet ls --tag-name k3s
2. export SERVER1=134.209.16.225
3. export SERVER2=167.99.198.45
4. export SERVER3=157.245.39.44
5. export AGENT1=161.35.32.107
6. export AGENT2=161.35.36.40既然你已经填充了环境变量,请运行以下命令:
1.
k3sup install --user root --ip $SERVER1 \
2. --k3s-channel $CHANNEL \
3. --print-command \
4. --datastore='${DATASTORE}' \
5. --tls-san $LB_IP
6. List item
7. k3sup install --user root --ip $SERVER2 \
--k3s-channel $CHANNEL \
8. --print-command \
9. --datastore='${DATASTORE}' \
10. --tls-san $LB_IP
11. k3sup install --user root --ip $SERVER3 \
12. List item
13. --k3s-channel $CHANNEL \
14. List item
15. --print-command \
16. --datastore='${DATASTORE}' \
17. --tls-san $LB_IP
18. k3sup join --user root --server-ip $LB_IP --ip $AGENT1 \
19. List item
20. --k3s-channel $CHANNEL \
21. --print-command
22. List item
23. k3sup join --user root --server-ip $LB_IP --ip $AGENT2 \
24. List item
25. --k3s-channel $CHANNEL \
26. --print-command检查节点是否加入
1. export KUBECONFIG=`pwd`/kubeconfig
2. List item
3. NAME STATUS ROLES AGE VERSION
4. k3s-server-2 Ready master 18m v1.19.3+k3s1
5. k3s-server-3 Ready master 18m v1.19.3+k3s1
6. k3s-agent-1 Ready <none> 2m39s v1.19.3+k3s1
7. k3s-server-1 Ready master 23m v1.19.1+k3s1
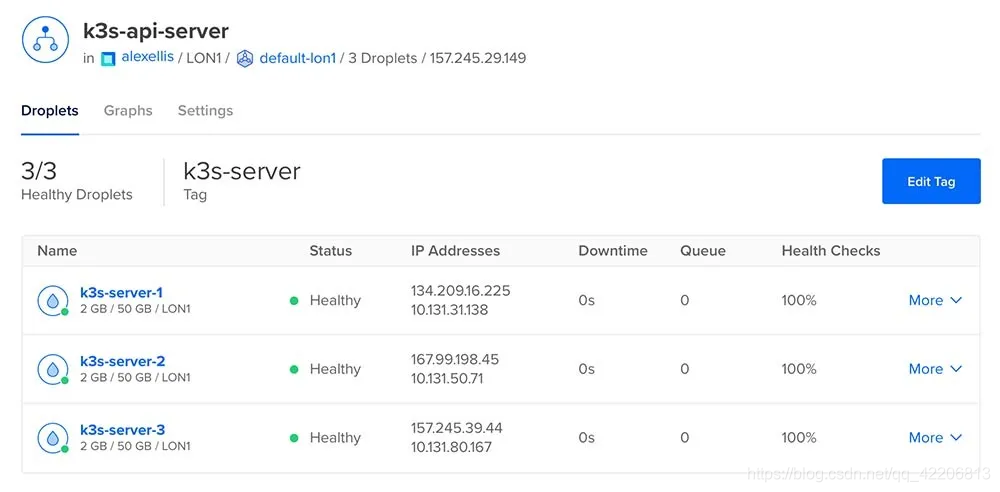
8. k3s-agent-2 Ready <none> 2m36s v1.19.3+k3s1打开KUBECONFIG文件,找到IP地址,应该是负载均衡器的地址。
片刻之后,你可以在DigitalOcean的仪表盘上看到负载均衡器的状态。
模拟故障
要模拟故障,需要在一个或多个k3s server上停止K3s服务,然后运行kubectl get nodes命令:
1. ssh root@SERVER1 'systemctl stop k3s'
2. ssh root@SERVER2 'systemctl stop k3s'此时,第三个server将会接管。
kubectl get nodes然后在其他两个server上重启服务:
1. ssh root@SERVER1 'systemctl start k3s'
2. ssh root@SERVER2 'systemctl start k3s'如果你还想了解更多关于Kubernetes如何处理节点中断的信息,请查看以下链接:
https://kubernetes.io/docs/con ... ions/
此时,你可以使用集群来部署一个应用程序,或者继续清理你配置的资源,这样你就不会因为任何额外的使用而被收取费用。
清理
删除droplets
doctl compute droplet rm --tag-name k3s对于负载均衡器和数据库,你需要获取ID,然后使用删除命令。
1. doctl compute load-balancer list/delete
2. doctl databases list/delete我们现在已经配置了一个容错、高可用性的K3s集群,并为用户提供了一个TCP负载均衡器,这样即使其中一台服务器宕机或崩溃,用户也可以访问kubectl。使用 "tag "也意味着我们可以添加更多的服务器,而不用担心必须手动更新负载平衡器的IP列表。
我们在这里使用的工具和技术也可以应用于其他支持托管数据库和托管负载均衡器的云平台,如AWS、谷歌云和Azure。
正如你可能已经从我们所经历的步骤中所注意到的那样,高可用性是一个需要花费一些时间和思考才能够进行正确配置。如果你打算创建许多HA K3s集群,那么使用Terraform自动化步骤可能会有好处。
你也可以使用k3sup使用嵌入式etcd,而不是托管数据库来配置HA K3s集群。这降低了成本,但增加了服务器的负载。
如果你想进一步了解K3s,欢迎查看以下文档:
https://docs.rancher.cn/k3s/
你也可以从GitHub上的仓库中找到更多关于k3sup如何工作的信息,包括使用etcd进行HA的替代方法:
https://k3sup.dev/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK