

Self-supervised Video Object Segmentation by Motion Grouping
source link: https://charigyang.github.io/motiongroup/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Self-supervised Video Object Segmentation by Motion Grouping Visual Geometry Group, University of Oxford PDF | ArXiv | Code | Bibtex
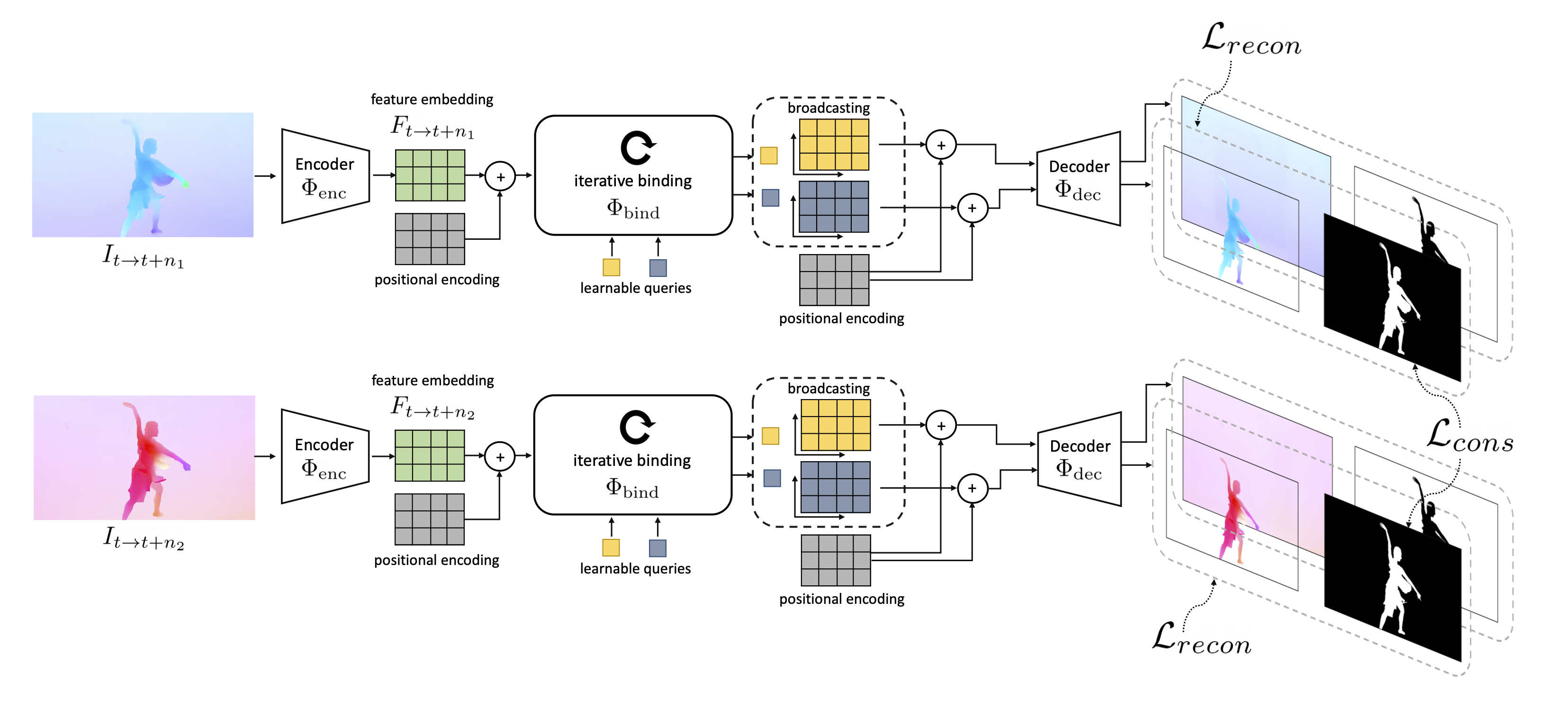
Abstract
Animals have evolved highly functional visual systems to understand motion, assisting perception even under complex environments. In this paper, we work towards developing a computer vision system able to segment objects by exploiting motion cues, i.e. motion segmentation. We make the following contributions: First, we introduce a simple variant of the Transformer to segment optical flow frames into primary objects and the background. Second, we train the architecture in a self-supervised manner, i.e. without using any manual annotations. Third, we analyze several critical components of our method and conduct thorough ablation studies to validate their necessity. Fourth, we evaluate the proposed architecture on public benchmarks (DAVIS2016, SegTrackv2, and FBMS59). Despite using only optical flow as input, our approach achieves superior results compared to previous state-of-the-art self-supervised methods, while being an order of magnitude faster. We additionally evaluate on a challenging camouflage dataset (MoCA), significantly outperforming the other self-supervised approaches, and comparing favourably to the top supervised approach, highlighting the importance of motion cues, and the potential bias towards visual appearance in existing video segmentation models.Results
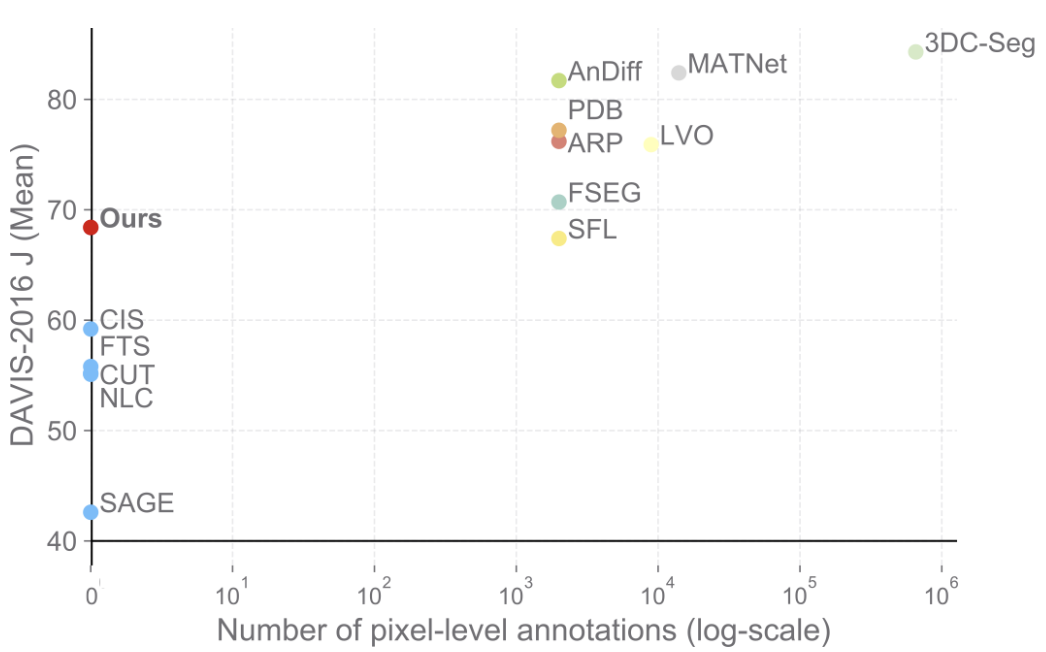
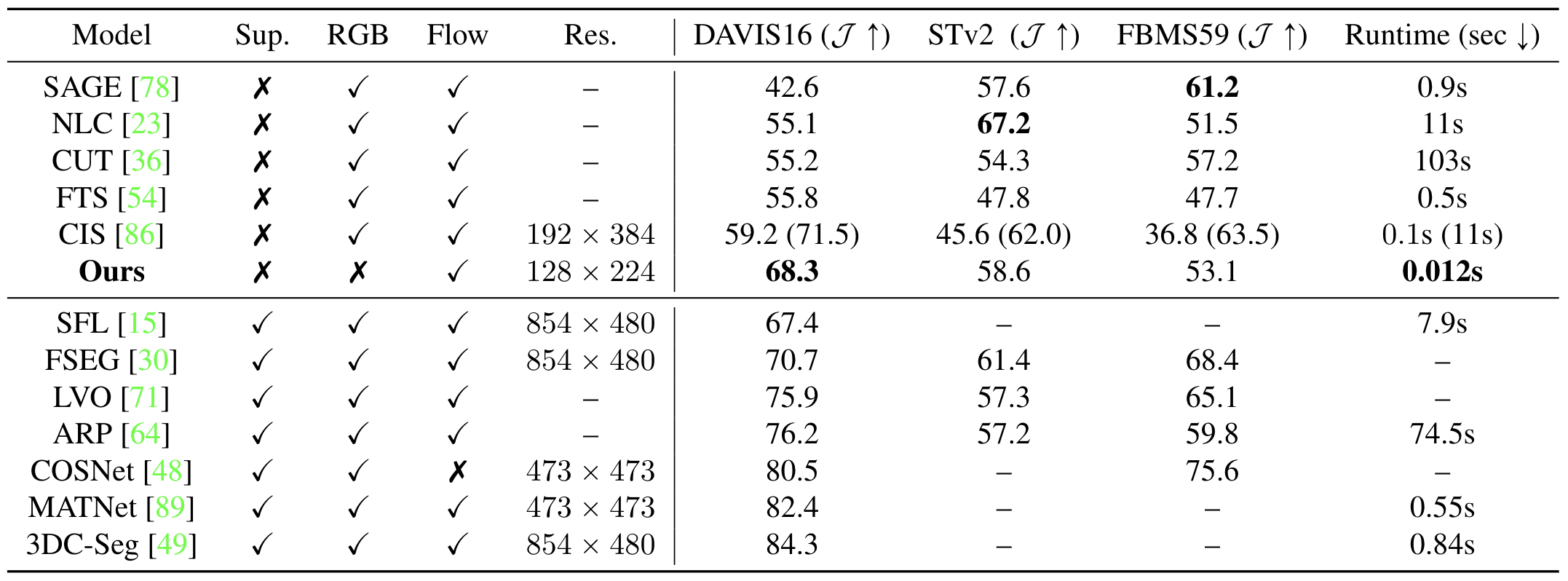
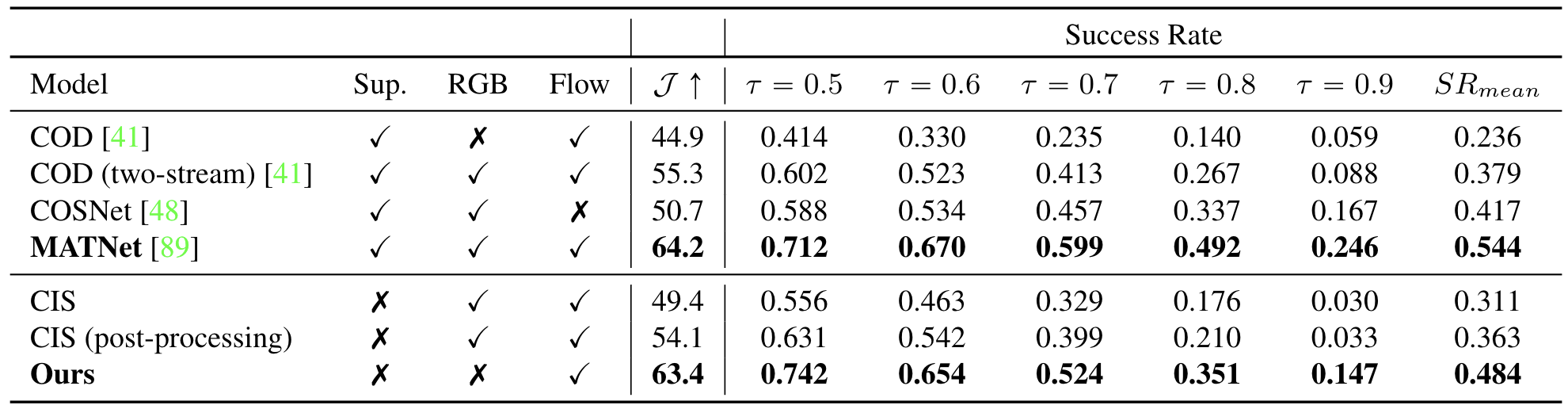
Visualizations




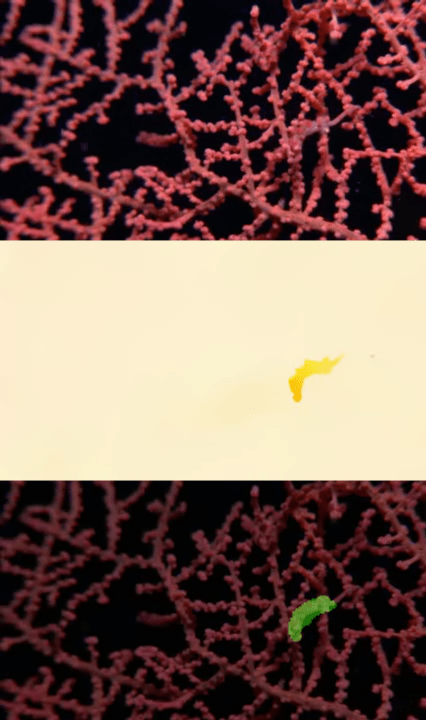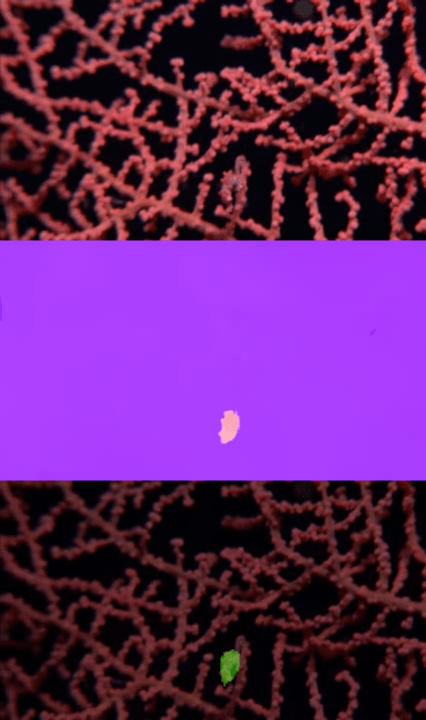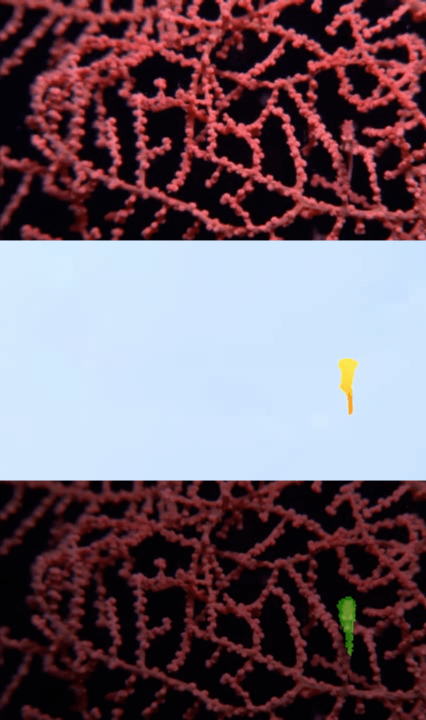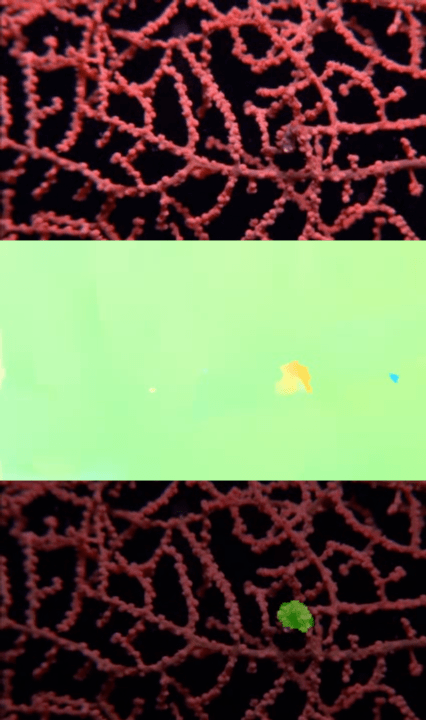





Publication
 C. Yang, H. Lamdouar, E. Lu, A. Zisserman, W. Xie
C. Yang, H. Lamdouar, E. Lu, A. Zisserman, W. XieSelf-supervised Video Object Segmentation by Motion Grouping
PDF | ArXiv | Code | Bibtex
Acknowledgements
This research is supported by Google-DeepMind Studentship, UK EPSRC CDT in AIMS, Schlumberger Studentship, and the UK EPSRC Programme Grant Visual AI (EP/T028572/1).This template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here.
Recommend
-
77
Photo by Kevin Gent on
-
25
Contrastive self-supervised learning techniques are a promising class of methods that build representations by learning to encode what makes two things similar or different. The prophecy that self-supervised...
-
26
FickleNet Weakly and Semi Supervised Semantic Image Segmentation Using Stochastic Inference
-
9
This real-world multiplayer game lets you spend other people’s money — really by Mix — 4 months ago...
-
7
Facebook details self-supervised AI that can segment images and videos Join Transform 2021 this July 12-16. Register fo
-
7
Redundant Encoding Strengthens Segmentation and Grouping in Visual Displays of Data 所属分类:computer graphic 摘要...
-
12
论文地址:https://openaccess.thecvf.com/content/CVPR2021/papers/Hu_Self-Supervised_3D_Mesh_Recons...
-
11
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Sel...
-
11
Reading Self-supervised Single-view 3D Reconstruction via Semantic Consistency 发表 2022-01-22...
-
7
Why self-supervised learning is a medical AI game-changer Skip to main content...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK