

数据结构之栈
source link: https://blog.csdn.net/mingyunxiaohai/article/details/86015804
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本篇是数据结构与算法之美学习笔记
栈是一种特殊的线性表,仅能在线性表的一端操作数据,只允许在栈顶操作,特性:后进先出。
就像我们往一个盒子里放东西,最先放的东西总是在下面,往外拿的时候,先拿到最后放进去的。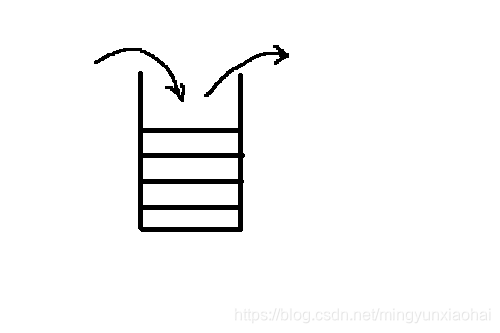
当某个数据集合,只涉及在一端插入和删除数据,并且满足后进先出的特性,这时候首选栈这种数据结构。
从上面的定义可以看出,栈主要包括两个操作,入栈和出栈,也就是从栈顶插入一个数据,和从栈顶删除一个数据。那怎么来实现一个栈呢?
栈可以用数组来实现也可以用链表来实现,用数组实现的栈叫顺序栈,用链表实现的栈叫链式栈、
使用数组实现一个栈:
public class ArrayStack {
private String[] items;
private int count;//栈中的元素的个数
private int n;//栈的总大小
public ArrayStack(int n) {
this.n = n;
this.items = new String[n];
this.count = 0;
}
//入栈操作
public boolean push(String item){
//如果栈满了,直接返回false
if(count == n) return false;
items[count] = item;
++count;
return true;
}
//出栈操作
public String pop(){
//如果栈为空 返回null
if(count == 0) return null;
String tmp = items[count-1];
--count;
return tmp;
}
}
上面是实现的一个固定大小的栈,在创建栈的时候需要制定栈的大小,栈满了之后就无法再往里面添加数据了,虽然使用链式栈大小不受限制,但是需要存储next指针,内存消耗比较多。那么怎么使用数组实现一个可以动态扩容的栈呢?
我们先看数组动态扩容的原理:当数组的空间不够的时候,就重新申请一块更大的内存,把原来的数组中数据全部拷贝过去。
所以想要实现一个可动态扩容的栈,让其底层依赖一个可动态扩容的数组就可以了。
使用链表实现一个栈:
public class LinkedListStack {
private Node top = null;
public void push(int value) {
Node newNode = new Node(value, null);
// 判断是否栈空
if (top == null) {
top = newNode;
} else {
newNode.next = top;
top = newNode;
}
}
/**
* -1表示栈中没有数据。
*/
public int pop() {
if (top == null) return -1;
int value = top.data;
top = top.next;
return value;
}
private static class Node {
private int data;
private Node next;
public Node(int data, Node next) {
this.data = data;
this.next = next;
}
public int getData() {
return data;
}
}
}
函数调用栈:
操作系统给每个线程分配了一块独立的内存空间,这块内存空间被组织成‘栈’这种结构,用来存储函数调用时的临时变量。每进入一个函数,就会把临时变量作为一个栈帧入栈,当被调用函数执行完成之后,把这个函数对应的栈帧出栈。
比如下面的函数
public int main(){
int a = 1;
int res = 0;
int ret = 0;
ret = add(5,6);
res = a + ret;
System.out.println("res"+res);
return res;
}
public int add(int x ,int y){
int sum = 0;
sum = x + y;
return sum;
}
从上面代码可以看到,main()方法调用了add()函数,并且与临时变量a相加。最后打印出res并返回。
main栈帧:a = 1,res = 0,ret = 0
add栈帧: x = 5,y = 6,sum = 0
为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗?
因为函数调用符合后进先出的特性,使用栈这种数据结构来实现比较好
从调用函数进入被调用函数,从数据来说,作用域发生了变化,所以,从根本上只要能保证每进入一个新的函数,都是一个新的作用域就可以了。要实现这个,使用栈就非常方便。在进入被调用的函数的时候,分配一段栈控件给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK