

【2w字干货】ArrayList与LinkedList的区别以及JDK11中的底层实现
source link: https://segmentfault.com/a/1190000039811042
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本文主要讲述了ArrayList与LinkedList的相同以及不同之处,以及两者的底层实现(环境OpenJDK 11.0.10)。
2 两者区别
在详细介绍两者的底层实现之前,先来简单看一下两者的异同。
2.1 相同点
- 两者都实现了
List接口,都继承了AbstractList(LinkedList间接继承,ArrayList直接继承) - 都是线程不安全的
- 都具有增删查改方法
2.2 不同点
- 底层数据结构不同:
ArrayList基于Object[]数组,LinkedList基于LinkedList.Node双向链表 - 随机访问效率不同:
ArrayList随机访问能做到O(1),因为可以直接通过下标找到元素,而LinkedList需要从头指针开始遍历,时间O(n) - 初始化操作不同:
ArrayList初始化时需要指定一个初始化容量(默认为10),而LinkedList不需要 - 扩容:
ArrayList当长度不足以容纳新元素的时候,会进行扩容,而LinkedList不会
3 ArrayList底层
3.1 基本结构
底层使用Object[]数组实现,成员变量如下:
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = new Object[0];
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = new Object[0];
transient Object[] elementData;
private int size;
private static final int MAX_ARRAY_SIZE = 2147483639;默认的初始化容量为10,接下来是两个空数组,供默认构造方法以及带初始化容量的构造方法使用:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else {
if (initialCapacity != 0) {
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
}
this.elementData = EMPTY_ELEMENTDATA;
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}下面再来看一些重要方法,包括:
add()remove()indexOf()/lastIndexOf()/contains()
3.2 add()
add()方法有四个:
add(E e)add(int index,E e)addAll(Collection<? extends E> c)addAll(int index, Collection<? extends E> c
3.2.1 单一元素add()
先来看一下add(E e)以及add(int index,E eelment):
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length) {
elementData = this.grow();
}
elementData[s] = e;
this.size = s + 1;
}
public boolean add(E e) {
++this.modCount;
this.add(e, this.elementData, this.size);
return true;
}
public void add(int index, E element) {
this.rangeCheckForAdd(index);
++this.modCount;
int s;
Object[] elementData;
if ((s = this.size) == (elementData = this.elementData).length) {
elementData = this.grow();
}
System.arraycopy(elementData, index, elementData, index + 1, s - index);
elementData[index] = element;
this.size = s + 1;
}add(E e)实际调用的是一个私有方法,判断是否需要扩容之后,直接添加到末尾。而add(int index,E element)会首先检查下标是否合法,合法的话,再判断是否需要扩容,之后调用System.arraycopy对数组进行复制,最后进行赋值并将长度加1。
关于System.arraycopy,官方文档如下:
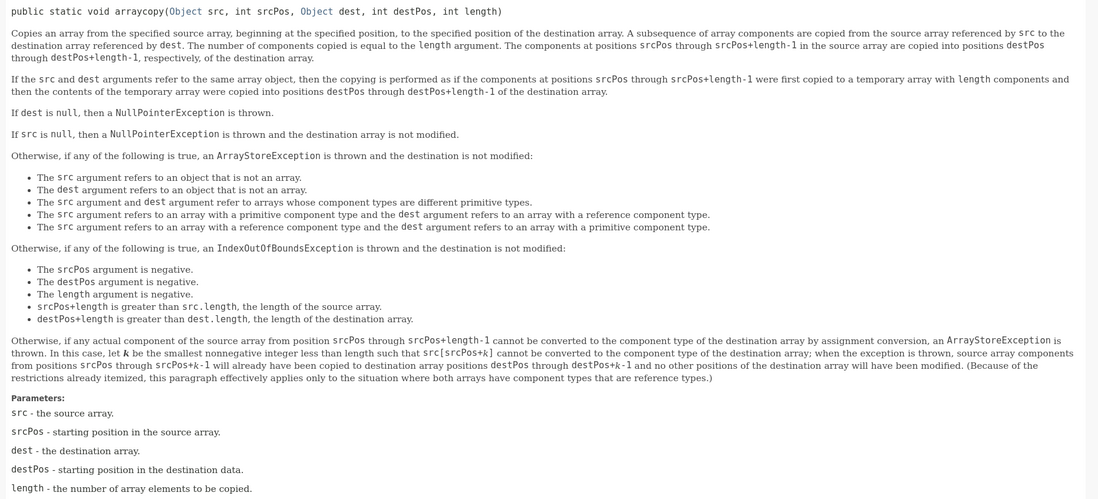
一共有5个参数:
- 第一个参数:原数组
- 第二个参数:原数组需要开始复制的位置
- 第三个参数:目标数组
- 第四个参数:复制到目标数组的开始位置
- 第五个参数:需要复制的数目
也就是说:
System.arraycopy(elementData, index, elementData, index + 1, s - index);的作用是将原数组在index后面的元素“往后挪”,空出一个位置让index进行插入。
3.2.2 addAll()
下面来看一下两个addAll():
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
++this.modCount;
int numNew = a.length;
if (numNew == 0) {
return false;
} else {
Object[] elementData;
int s;
if (numNew > (elementData = this.elementData).length - (s = this.size)) {
elementData = this.grow(s + numNew);
}
System.arraycopy(a, 0, elementData, s, numNew);
this.size = s + numNew;
return true;
}
}
public boolean addAll(int index, Collection<? extends E> c) {
this.rangeCheckForAdd(index);
Object[] a = c.toArray();
++this.modCount;
int numNew = a.length;
if (numNew == 0) {
return false;
} else {
Object[] elementData;
int s;
if (numNew > (elementData = this.elementData).length - (s = this.size)) {
elementData = this.grow(s + numNew);
}
int numMoved = s - index;
if (numMoved > 0) {
System.arraycopy(elementData, index, elementData, index + numNew, numMoved);
}
System.arraycopy(a, 0, elementData, index, numNew);
this.size = s + numNew;
return true;
}
}在第一个addAll中,首先判断是否需要扩容,接着也是直接调用目标集合添加到尾部。而在第二个addAll中,由于多了一个下标参数,处理步骤稍微多了一点:
- 首先判断下标是否合法
- 接着判断是否需要扩容
- 再计算是否需要把原来的数组元素“往后挪”,也就是
if里面的System.arraycopy - 最后把目标数组复制到指定的
index位置
3.2.3 扩容
上面的add()方法都涉及到了扩容,也就是grow方法,下面来看一下:
private Object[] grow(int minCapacity) {
return this.elementData = Arrays.copyOf(this.elementData, this.newCapacity(minCapacity));
}
private Object[] grow() {
return this.grow(this.size + 1);
}
private int newCapacity(int minCapacity) {
int oldCapacity = this.elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (this.elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(10, minCapacity);
} else if (minCapacity < 0) {
throw new OutOfMemoryError();
} else {
return minCapacity;
}
} else {
return newCapacity - 2147483639 <= 0 ? newCapacity : hugeCapacity(minCapacity);
}
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) {
throw new OutOfMemoryError();
} else {
return minCapacity > 2147483639 ? 2147483647 : 2147483639;
}
}grow()首先通过newCapacity计算需要扩容的容量,接着调用Arrays.copyOf将旧元素复制过去,并将返回值覆盖到原来的数组。而在newCapacity中,有两个变量:
newCapacity:新的容量,默认是旧容量的1.5倍,也就是默认扩容1.5倍minCapacity:最低需要的容量
如果最低容量大于等于新容量,则是如下情况之一:
- 通过默认构造初始化的数组:返回
minCapacity与10的最大值 - 溢出:直接抛
OOM - 否则返回最小容量值
如果不是,则判断新容量是否达到最大值(这里有点好奇为什么不用MAX_ARRAY_SIZE,猜测是反编译的问题),如果没有到达最大值,则返回新容量,如果到达了最大值,调用hugeCapacity。
hugeCapacity同样会首先判断最小容量是否小于0,小于则抛OOM,否则将其与最大值(MAX_ARRAY_SIZE)判断,如果大于返回Integer.MAX_VALUE,否则返回MAX_ARRAY_SIZE。
3.3 remove()
remove()包含四个方法:
remove(int index)remove(Object o)removeAll()removeIf()
3.3.1 单一元素remove()
也就是remove(int index)以及remove(Object o):
public E remove(int index) {
Objects.checkIndex(index, this.size);
Object[] es = this.elementData;
E oldValue = es[index];
this.fastRemove(es, index);
return oldValue;
}
public boolean remove(Object o) {
Object[] es = this.elementData;
int size = this.size;
int i = 0;
if (o == null) {
while(true) {
if (i >= size) {
return false;
}
if (es[i] == null) {
break;
}
++i;
}
} else {
while(true) {
if (i >= size) {
return false;
}
if (o.equals(es[i])) {
break;
}
++i;
}
}
this.fastRemove(es, i);
return true;
}其中remove(int index)的逻辑比较简单,先检查下标合法性,然后保存需要remove的值,并调用fastRemove()进行移除,而在remove(Object o)中,直接对数组进行遍历,并判断是否存在对应的元素,如果不存在直接返回false,如果存在,调用fastRemove(),并返回true。
下面看一下fastRemove():
private void fastRemove(Object[] es, int i) {
++this.modCount;
int newSize;
if ((newSize = this.size - 1) > i) {
System.arraycopy(es, i + 1, es, i, newSize - i);
}
es[this.size = newSize] = null;
}首先修改次数加1,然后将数组长度减1,并判断新长度是否是最后一个,如果是最后一个则不需要移动,如果不是,调用System.arraycopy将数组向前“挪”1位,最后将末尾多出来的一个值置为null。
3.3.2 removeAll()
public boolean removeAll(Collection<?> c) {
return this.batchRemove(c, false, 0, this.size);
}
boolean batchRemove(Collection<?> c, boolean complement, int from, int end) {
Objects.requireNonNull(c);
Object[] es = this.elementData;
for(int r = from; r != end; ++r) {
if (c.contains(es[r]) != complement) {
int w = r++;
try {
for(; r < end; ++r) {
Object e;
if (c.contains(e = es[r]) == complement) {
es[w++] = e;
}
}
} catch (Throwable var12) {
System.arraycopy(es, r, es, w, end - r);
w += end - r;
throw var12;
} finally {
this.modCount += end - w;
this.shiftTailOverGap(es, w, end);
}
return true;
}
}
return false;
}removeAll实际上调用的是batchRemove(),在batchRemove()中,有四个参数,含义如下:
Collection<?> c:目标集合boolean complement:如果取值true,表示保留数组中包含在目标集合c中的元素,如果为false,表示删除数组中包含在目标集合c中的元素from/end:区间范围,左闭右开
所以传递的(c,false,0,this.size)表示删除数组里面在目标集合c中的元素。下面简单说一下执行步骤:
- 首先进行判空操作
- 接着找到第一符合要求的元素(这里是找到第一个需要删除的元素)
- 找到后从该元素开始继续向后查找,同时记录删除后的数组中最后一个元素的下标
w try/catch是一种保护性行为,因为contains()在AbstractCollection的实现中,会使用Iterator,这里catch异常后仍然调用System.arraycopy,使得已经处理的元素“挪到”前面- 最后会增加修改的次数,并调用
shiftTailOverGap,该方法在后面会详解
3.3.3 removeIf()
public boolean removeIf(Predicate<? super E> filter) {
return this.removeIf(filter, 0, this.size);
}
boolean removeIf(Predicate<? super E> filter, int i, int end) {
Objects.requireNonNull(filter);
int expectedModCount = this.modCount;
Object[] es;
for(es = this.elementData; i < end && !filter.test(elementAt(es, i)); ++i) {
}
if (i < end) {
int beg = i;
long[] deathRow = nBits(end - i);
deathRow[0] = 1L;
++i;
for(; i < end; ++i) {
if (filter.test(elementAt(es, i))) {
setBit(deathRow, i - beg);
}
}
if (this.modCount != expectedModCount) {
throw new ConcurrentModificationException();
} else {
++this.modCount;
int w = beg;
for(i = beg; i < end; ++i) {
if (isClear(deathRow, i - beg)) {
es[w++] = es[i];
}
}
this.shiftTailOverGap(es, w, end);
return true;
}
} else if (this.modCount != expectedModCount) {
throw new ConcurrentModificationException();
} else {
return false;
}
}在removeIf中,删除符合条件的元素,首先会进行判空操作,然后找到第一个符合条件的元素下标,如果找不到(i>=end),判断是否有并发操作问题,没有的话返回false,如果i<end,也就是正式进入删除流程:
- 记录开始下标
beg deathRow是一个标记数组,长度为(end-i-1)>>6 + 1,从beg开始如果遇到符合条件的元素就对下标进行标记(调用setBit)- 标记后进行删除,所谓的删除其实就是把后面不符合条件的元素逐个移动到
beg之后的位置上 - 调用
shiftTailOverGap处理末尾的元素 - 返回
true,表示存在符合条件的元素并进行了删除操作
3.3.4 shiftTailOverGap()
上面的removeAll()以及removeIf()都涉及到了shiftTailOverGap(),下面来看一下实现:
private void shiftTailOverGap(Object[] es, int lo, int hi) {
System.arraycopy(es, hi, es, lo, this.size - hi);
int to = this.size;
for(int i = this.size -= hi - lo; i < to; ++i) {
es[i] = null;
}
}该方法将es数组中的元素向前移动hi-lo位,并将移动之后的在末尾多出来的那部分元素置为null。
3.4 indexOf()系列
indexOf()lastIndexOf()contains()
3.4.1 indexOf
public int indexOf(Object o) {
return this.indexOfRange(o, 0, this.size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = this.elementData;
int i;
if (o == null) {
for(i = start; i < end; ++i) {
if (es[i] == null) {
return i;
}
}
} else {
for(i = start; i < end; ++i) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}indexOf()实际上是一个包装好的方法,会调用内部的indexOfRange()进行查找,逻辑很简单,首先判断需要查找的值是否为空,如果不为空,使用equals()判断,否则使用==判断,找到就返回下标,否则返回-1。
3.4.2 contains()
contains()实际上是indexOf()的包装:
public boolean contains(Object o) {
return this.indexOf(o) >= 0;
}调用indexOf()方法,根据返回的下标判断是否大于等于0,如果是则返回存在,否则返回不存在。
3.4.3 lastIndexOf()
lastIndexOf()实现与indexOf()类似,只不过是从尾部开始遍历,内部调用的是lastIndexOfRange():
public int lastIndexOf(Object o) {
return this.lastIndexOfRange(o, 0, this.size);
}
int lastIndexOfRange(Object o, int start, int end) {
Object[] es = this.elementData;
int i;
if (o == null) {
for(i = end - 1; i >= start; --i) {
if (es[i] == null) {
return i;
}
}
} else {
for(i = end - 1; i >= start; --i) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}4 LinkedList底层
4.1 基本结构
首先来看一下里面的成员变量:
transient int size;
transient LinkedList.Node<E> first;
transient LinkedList.Node<E> last;
private static final long serialVersionUID = 876323262645176354L;一个表示长度,一个头指针和一个尾指针。
其中LinkedList.Node实现如下:
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}可以看到LinkedList实际是基于双链表实现的。
下面再来看一些重要方法,包括:
add()remove()get()
4.2 add()
add()方法包括6个:
add(E e)add(int index,E e)addFirst(E e)addLast(E e)addAll(Collection<? extends E> c)addAll(int index, Collection<? extends E> c)
4.2.1 linkFirst/linkLast/linkBefore实现的add()
先看一下比较简单的四个add():
public void addFirst(E e) {
this.linkFirst(e);
}
public void addLast(E e) {
this.linkLast(e);
}
public boolean add(E e) {
this.linkLast(e);
return true;
}
public void add(int index, E element) {
this.checkPositionIndex(index);
if (index == this.size) {
this.linkLast(element);
} else {
this.linkBefore(element, this.node(index));
}
}可以看到,上面的四个add()不进行任何的添加元素操作,add()只是添加元素的封装,真正实现add操作的是linkLast()、linkFirst()和linkBefore(),这些方法顾名思义就是把元素链接到链表的末尾或者头部,或者链表某个节点的前面:
void linkLast(E e) {
LinkedList.Node<E> l = this.last;
LinkedList.Node<E> newNode = new LinkedList.Node(l, e, (LinkedList.Node)null);
this.last = newNode;
if (l == null) {
this.first = newNode;
} else {
l.next = newNode;
}
++this.size;
++this.modCount;
}
private void linkFirst(E e) {
LinkedList.Node<E> f = this.first;
LinkedList.Node<E> newNode = new LinkedList.Node((LinkedList.Node)null, e, f);
this.first = newNode;
if (f == null) {
this.last = newNode;
} else {
f.prev = newNode;
}
++this.size;
++this.modCount;
}
void linkBefore(E e, LinkedList.Node<E> succ) {
LinkedList.Node<E> pred = succ.prev;
LinkedList.Node<E> newNode = new LinkedList.Node(pred, e, succ);
succ.prev = newNode;
if (pred == null) {
this.first = newNode;
} else {
pred.next = newNode;
}
++this.size;
++this.modCount;
}实现大体相同,一个是添加到尾部,一个是添加头部,一个是插入到前面。另外,三者在方法的最后都有如下操作:
++this.size;
++this.modCount;第一个表示节点的个数加1,而第二个,则表示对链表的修改次数加1。
比如,在unlinkLast方法的最后,有如下代码:
--this.size;
++this.modCount;unlinkLast操作就是移除最后一个节点,节点个数减1的同时,对链表的修改次数加1。
另一方面,通常来说链表插入操作需要找到链表的位置,但是在三个link方法里面,都看不到for循环找到插入位置的代码,这是为什么呢?
由于保存了头尾指针,linkFirst()以及linkLast()并不需要遍历找到插入的位置,但是对于linkBefore()来说,需要找到插入的位置,不过linkBefore()并没有类似“插入位置/插入下标”之类的参数,而是只有一个元素值以及一个后继节点。换句话说,这个后继节点就是通过循环得到的插入位置,比如,调用的代码如下:
this.linkBefore(element, this.node(index));可以看到在this.node()中,传入了一个下标,并返回了一个后继节点,也就是遍历操作在该方法完成:
LinkedList.Node<E> node(int index) {
LinkedList.Node x;
int i;
if (index < this.size >> 1) {
x = this.first;
for(i = 0; i < index; ++i) {
x = x.next;
}
return x;
} else {
x = this.last;
for(i = this.size - 1; i > index; --i) {
x = x.prev;
}
return x;
}
}这里首先通过判断下标是位于“哪一边”,如果靠近头部,从头指针开始往后遍历,如果靠近尾部,从尾指针开始向后遍历。
4.2.2 遍历实现的addAll()
public boolean addAll(Collection<? extends E> c) {
return this.addAll(this.size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
this.checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0) {
return false;
} else {
LinkedList.Node pred;
LinkedList.Node succ;
if (index == this.size) {
succ = null;
pred = this.last;
} else {
succ = this.node(index);
pred = succ.prev;
}
Object[] var7 = a;
int var8 = a.length;
for(int var9 = 0; var9 < var8; ++var9) {
Object o = var7[var9];
LinkedList.Node<E> newNode = new LinkedList.Node(pred, o, (LinkedList.Node)null);
if (pred == null) {
this.first = newNode;
} else {
pred.next = newNode;
}
pred = newNode;
}
if (succ == null) {
this.last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
this.size += numNew;
++this.modCount;
return true;
}
}首先可以看到两个addAll实际上调用的是同一个方法,步骤简述如下:
- 首先通过
checkPositionIndex判断下标是否合法 - 接着把目标集合转为
Object[]数组 - 进行一些特判处理,判断
index的范围是插入中间,还是在末尾插入 for循环遍历目标数组,并插入到链表中- 修改节点长度,并返回
4.3 remove()
与add()类似,remove包括:
remove()remove(int index)remove(Object o)removeFirst()removeLast()removeFirstOccurrence(Object o)removeLastOccurrence(Object o)
当然其实还有两个removeAll与removeIf,但实际上是父类的方法,这里就不分析了。
4.3.1 unlinkFirst()/unlinkLast()实现的remove()
remove()、removeFirst()、removeLast()实际上是通过调用unlinkFirst()/unlinkLast()进行删除的,其中remove()只是removeFirst()的一个别名:
public E remove() {
return this.removeFirst();
}
public E removeFirst() {
LinkedList.Node<E> f = this.first;
if (f == null) {
throw new NoSuchElementException();
} else {
return this.unlinkFirst(f);
}
}
public E removeLast() {
LinkedList.Node<E> l = this.last;
if (l == null) {
throw new NoSuchElementException();
} else {
return this.unlinkLast(l);
}
}逻辑很简单,判空之后,调用unlinkFirst()/unlinkLast():
private E unlinkFirst(LinkedList.Node<E> f) {
E element = f.item;
LinkedList.Node<E> next = f.next;
f.item = null;
f.next = null;
this.first = next;
if (next == null) {
this.last = null;
} else {
next.prev = null;
}
--this.size;
++this.modCount;
return element;
}
private E unlinkLast(LinkedList.Node<E> l) {
E element = l.item;
LinkedList.Node<E> prev = l.prev;
l.item = null;
l.prev = null;
this.last = prev;
if (prev == null) {
this.first = null;
} else {
prev.next = null;
}
--this.size;
++this.modCount;
return element;
}而在这两个unlink中,由于已经保存了头指针和尾指针的位置,因此两者可以直接在O(1)内进行移除操作,最后将节点长度减1,修改次数加1,并返回旧元素。
4.3.2 unlink()实现的remove()
再来看一下remove(int index)、remove(Object o)、removeFirstOccurrence(Object o)、removeLastOccurrence(Object o):
public E remove(int index) {
this.checkElementIndex(index);
return this.unlink(this.node(index));
}
public boolean remove(Object o) {
LinkedList.Node x;
if (o == null) {
for(x = this.first; x != null; x = x.next) {
if (x.item == null) {
this.unlink(x);
return true;
}
}
} else {
for(x = this.first; x != null; x = x.next) {
if (o.equals(x.item)) {
this.unlink(x);
return true;
}
}
}
return false;
}
public boolean removeFirstOccurrence(Object o) {
return this.remove(o);
}
public boolean removeLastOccurrence(Object o) {
LinkedList.Node x;
if (o == null) {
for(x = this.last; x != null; x = x.prev) {
if (x.item == null) {
this.unlink(x);
return true;
}
}
} else {
for(x = this.last; x != null; x = x.prev) {
if (o.equals(x.item)) {
this.unlink(x);
return true;
}
}
}
return false;
}这几个方法实际上都是调用unlink去移除元素,其中removeFirstOccurrence(Object o)等价于remove(Object o),先说一下remove(int index),该方法逻辑比较简单,先检查下标合法性,再通过下标找到节点并进行unlnk。
而在remove(Object o)中,需要首先对元素的值是否为null进行判断,两个循环实际上效果等价,会移除遇到的第一个与目标值相同的元素。在removeLastOccurrence(Object o)中,代码大体一致,只是remove(Object o)从头指针开始遍历,而removeLastOccurrence(Object o)从尾指针开始遍历。
可以看到,这几个remove方法实际上是找到要删除的节点,最后调用unlink()进行删除,下面看一下unlink():
E unlink(LinkedList.Node<E> x) {
E element = x.item;
LinkedList.Node<E> next = x.next;
LinkedList.Node<E> prev = x.prev;
if (prev == null) {
this.first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
this.last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
--this.size;
++this.modCount;
return element;
}实现逻辑与unlinkFirst()/unlinkLast()类似,在O(1)内进行删除,里面只是一些比较简单的特判操作,最后将节点长度减1,并将修改次数加1,最后返回旧值。
4.4 get()
get方法比较简单,对外提供了三个:
get(int index)getFirst()getLast()
其中getFirst()以及getLast()由于保存了头尾指针,特判后,直接O(1)返回:
public E getFirst() {
LinkedList.Node<E> f = this.first;
if (f == null) {
throw new NoSuchElementException();
} else {
return f.item;
}
}
public E getLast() {
LinkedList.Node<E> l = this.last;
if (l == null) {
throw new NoSuchElementException();
} else {
return l.item;
}
}而get(int index)毫无疑问需要O(n)时间:
public E get(int index) {
this.checkElementIndex(index);
return this.node(index).item;
}get(int index)判断下标后,实际上进行操作的是this.node(),由于该方法是通过下标找到对应的节点,源码前面也写上了,这里就不分析了,需要O(n)的时间。
ArrayList基于Object[]实现,LinkedList基于双链表实现ArrayList随机访问效率要高于LinkedListLinkedList提供了比ArrayList更多的插入方法,而且头尾插入效率要高于ArrayList- 两者的删除元素方法并不完全相同,
ArrayList提供了独有的removeIf(),而LinkedList提供了独有的removeFirstOccurrence()以及removeLastOccurrence() ArrayList的get()方法始终为O(1),而LinkedList只有getFirst()/getLast()为O(1)ArrayList中的两个核心方法是grow()以及System.arraycopy,前者是扩容方法,默认为1.5倍扩容,后者是复制数组方法,是一个native方法,插入、删除等等操作都需要使用LinkedList中很多方法需要对头尾进行特判,创建比ArrayList简单,无须初始化,不涉及扩容问题
6 附录:关于插入与删除的一个实验
关于插入与删除,通常认为LinkedList的效率要比ArrayList高,但实际上并不是这样,下面是一个测试插入与删除时间的小实验。
相关说明:
- 测试次数:1000次
- 数组长度:4000、40w、4000w
- 测试数组:随机生成
- 插入与删除下标:随机生成
- 结果值:插入与删除1000次的平均时间
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args){
int len = 40_0000;
Random random = new Random();
List<Integer> list = Stream.generate(random::nextInt).limit(len).collect(Collectors.toList());
LinkedList<Integer> linkedList = new LinkedList<>(list);
ArrayList<Integer> arrayList = new ArrayList<>(list);
long start;
long end;
double linkedListTotalInsertTime = 0.0;
double arrayListTotalInsertTime = 0.0;
int testTimes = 1000;
for (int i = 0; i < testTimes; i++) {
int index = random.nextInt(len);
int element = random.nextInt();
start = System.nanoTime();
linkedList.add(index,element);
end = System.nanoTime();
linkedListTotalInsertTime += (end-start);
start = System.nanoTime();
arrayList.add(index,element);
end = System.nanoTime();
arrayListTotalInsertTime += (end-start);
}
System.out.println("LinkedList average insert time:"+linkedListTotalInsertTime/testTimes+" ns");
System.out.println("ArrayList average insert time:"+arrayListTotalInsertTime/testTimes + " ns");
linkedListTotalInsertTime = arrayListTotalInsertTime = 0.0;
for (int i = 0; i < testTimes; i++) {
int index = random.nextInt(len);
start = System.nanoTime();
linkedList.remove(index);
end = System.nanoTime();
linkedListTotalInsertTime += (end-start);
start = System.nanoTime();
arrayList.remove(index);
end = System.nanoTime();
arrayListTotalInsertTime += (end-start);
}
System.out.println("LinkedList average delete time:"+linkedListTotalInsertTime/testTimes+" ns");
System.out.println("ArrayList average delete time:"+arrayListTotalInsertTime/testTimes + " ns");
}
}在数组长度为4000的时候,输出如下:
LinkedList average insert time:4829.938 ns
ArrayList average insert time:745.529 ns
LinkedList average delete time:3142.988 ns
ArrayList average delete time:1703.76 ns而在数组长度40w的时候(参数-Xmx512m -Xms512m),输出如下:
LinkedList average insert time:126620.38 ns
ArrayList average insert time:25955.014 ns
LinkedList average delete time:119281.413 ns
ArrayList average delete time:25435.593 ns而将数组长度调到4000w(参数-Xmx16g -Xms16g),时间如下:
LinkedList average insert time:5.6048377238E7 ns
ArrayList average insert time:2.5303627956E7 ns
LinkedList average delete time:5.4753230158E7 ns
ArrayList average delete time:2.5912990133E7 ns虽然这个实验有一定的局限性,但也是证明了ArrayList的插入以及删除性能并不会比LinkedList差。实际上,通过源码(看下面分析)可以知道,ArrayList插入以及删除的主要耗时在于System.arraycopy,而LinkedList主要耗时在于this.node(),实际上两者需要的都是O(n)时间。
至于为什么ArrayList的插入和删除速度要比LinkedList快,笔者猜测,是System.arraycopy的速度快于LinkedList中的for循环遍历速度,因为LinkedList中找到插入/删除的位置是通过this.node(),而该方法是使用简单的for循环实现的(当然底层是首先判断是位于哪一边,靠近头部的话从头部开始遍历,靠近尾部的话从尾部开始遍历)。相对于System.arraycopy的原生C++方法实现,可能会慢于C++,因此造成了速度上的差异。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK