

rabbitmq 如何保证消息的可靠传输(如何处理消息丢失的问题)?
source link: https://my.oschina.net/u/3287796/blog/5017132
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
(1)rabbitmq
1)生产者弄丢了数据
生产者将数据发送到rabbitmq的时候,可能数据就在半路给搞丢了,因为网络啥的问题,都有可能。
此时可以选择用rabbitmq提供的事务功能,就是生产者发送数据之前开启rabbitmq事务(channel.txSelect),然后发送消息,如果消息没有成功被rabbitmq接收到,那么生产者会收到异常报错,此时就可以回滚事务(channel.txRollback),然后重试发送消息;如果收到了消息,那么可以提交事务(channel.txCommit)。但是问题是,rabbitmq事务机制一搞,基本上吞吐量会下来,因为太耗性能。
所以一般来说,如果你要确保说写rabbitmq的消息别丢,可以开启confirm模式,在生产者那里设置开启confirm模式之后,你每次写的消息都会分配一个唯一的id,然后如果写入了rabbitmq中,rabbitmq会给你回传一个ack消息,告诉你说这个消息ok了。如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息id的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
事务机制和cnofirm机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是confirm机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息rabbitmq接收了之后会异步回调你一个接口通知你这个消息接收到了。
所以一般在生产者这块避免数据丢失,都是用confirm机制的。
2)rabbitmq弄丢了数据
就是rabbitmq自己弄丢了数据,这个你必须开启rabbitmq的持久化,就是消息写入之后会持久化到磁盘,哪怕是rabbitmq自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,rabbitmq还没持久化,自己就挂了,可能导致少量数据会丢失的,但是这个概率较小。
设置持久化有两个步骤,第一个是创建queue的时候将其设置为持久化的,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里的数据;第二个是发送消息的时候将消息的deliveryMode设置为2,就是将消息设置为持久化的,此时rabbitmq就会将消息持久化到磁盘上去。必须要同时设置这两个持久化才行,rabbitmq哪怕是挂了,再次重启,也会从磁盘上重启恢复queue,恢复这个queue里的数据。
而且持久化可以跟生产者那边的confirm机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者ack了,所以哪怕是在持久化到磁盘之前,rabbitmq挂了,数据丢了,生产者收不到ack,你也是可以自己重发的。
哪怕是你给rabbitmq开启了持久化机制,也有一种可能,就是这个消息写到了rabbitmq中,但是还没来得及持久化到磁盘上,结果不巧,此时rabbitmq挂了,就会导致内存里的一点点数据会丢失。
3)消费端弄丢了数据
rabbitmq如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,那么就尴尬了,rabbitmq认为你都消费了,这数据就丢了。
这个时候得用rabbitmq提供的ack机制,简单来说,就是你关闭rabbitmq自动ack,可以通过一个api来调用就行,然后每次你自己代码里确保处理完的时候,再程序里ack一把。这样的话,如果你还没处理完,不就没有ack?那rabbitmq就认为你还没处理完,这个时候rabbitmq会把这个消费分配给别的consumer去处理,消息是不会丢的。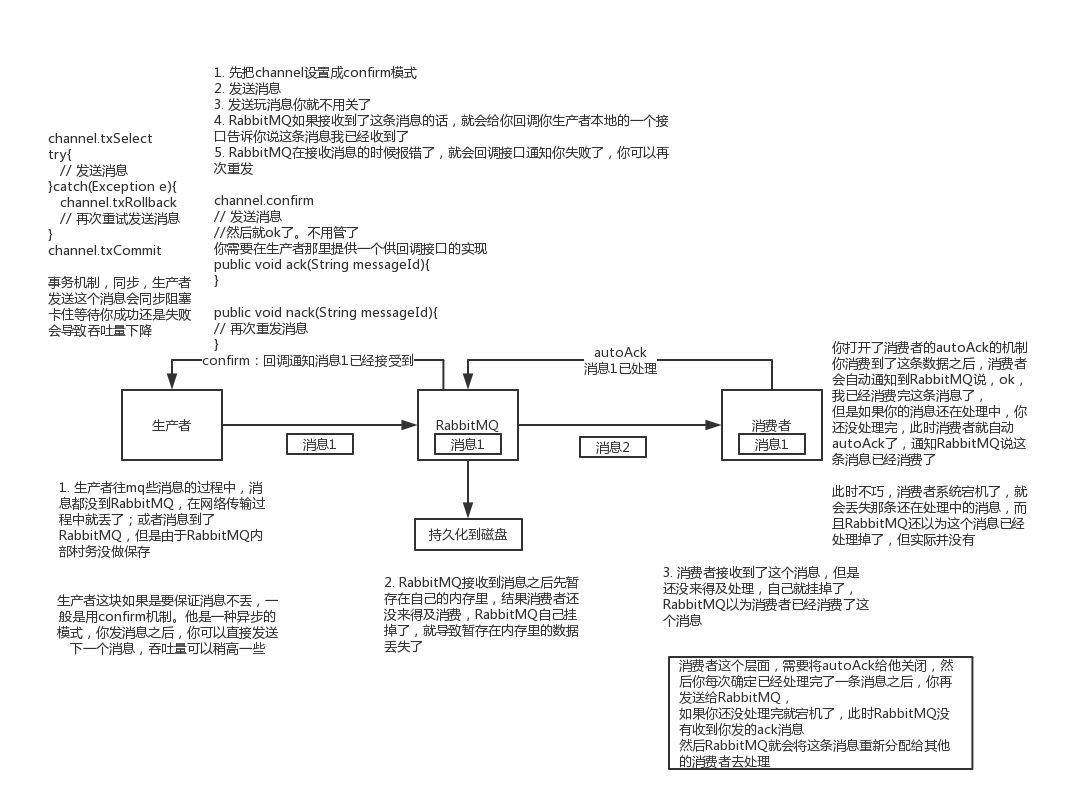
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK