

[译]C++17,标准库新引入的并行算法
source link: https://blog.csdn.net/tkokof1/article/details/82713700
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
[译]C++17,标准库新引入的并行算法
看到一个介绍 C++17 的系列博文(原文),有十来篇的样子,觉得挺好,看看有时间能不能都简单翻译一下,这是第七篇~
C++17 对 STL 算法的改动,概念上其实很简单.标准库之前有超过100个算法,内容包括搜索,计数,区间及元素操作等等.新标准重载了其中69个算法并新增了7个算法.重载的算法和新增的算法都支持指定一个所谓执行策略(execution policy)的参数,通过调整这个参数,你可以指定算法是以串行,并行或者矢量并行的方式来运行.
我之前的文章介绍了很多重载的标准库算法,有兴趣的朋友可以看看.
这次,我要介绍一下 C++17 新引入的7个算法:
std::for_each_n
std::exclusive_scan
std::inclusive_scan
std::transform_exclusive_scan
std::transform_inclusive_scan
std::parallel::reduce
std::parallel::transform_reduce
其中除了 std::for_each_n 之外,其他几个算法的名字都很特殊.为了理解方便,我先介绍一下 Haskell 中相关的内容,之后再回到C++的讲解中.
A short detour
C++17 新引入的算法在纯函数式语言 Haskell 中都有对应的方法.
- for_each_n 对应的方法为 map.
- exclusive_scan 和 inclusive_scan 对应的方法为 scanl 和 scanl1
- transform_exclusive_scan 等同于组合使用 map 和 scanl, 而 transform_inclusive_scan 等同于组合或者 map 和 scanl1.
- reduce 对应 foldl 或者 foldl1.
- transform_reduce 对应 map 和 foldl 的组合或者 map 和 foldl1 的组合.
开始讲解之前,让我简单说一下这些方法的功能作用.
- map 可以对一个列表应用一个函数
- foldl 和 foldl1 可以对一个列表应用一个二元运算并将结果归纳为一个数值.foldl 与 foldl1 相比额外需要一个初始值.
- scanl 和 scanl1 的操作与 foldl 和 foldl1 基本一致,但是他们会产生所有的中间结果,所以最终你会获得一个列表,而不是一个数值.
- foldl, foldl1, scanl 和 scanl1 的操作都是从列表的左侧开始.
下面是一个 Haskell 的相关示例
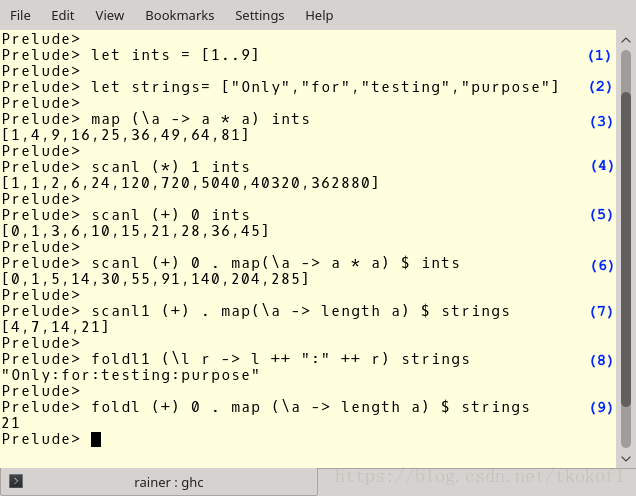
(1) 和 (2) 处的代码分别定义了一个整数列表(ints)和一个字符串列表(strings).在 (3) 中,我给整数列表(ints)应用了一个 lambda 函数(\a -> a * a).(4) 和 (5) 则更加复杂些:(4) 中我将整数列表中的所有整数对相乘(乘法单位元素1作为初始元素).(5) 中则做了所有整数对相加的操作.(6), (7), 和 (9) 中的操作可能有些难以理解,你必须从右往左来阅读这几个表达式.scanl1 (+) . map(\a -> length a) (即(7)) 是一个函数组合,其中的点号(.)用以组合左右两个函数.第一个函数将列表中的元素映射为元素的长度,第二个函数则将这些映射的长度相加.(9) 中的操作和 (7) 很相似,不同之处在于 foldl 只产生一个数值(而不是列表)并且需要一个初始元素(我指定初始元素为0),现在,表达式(8)看起来应该比较简单了,他以":"作为分隔符连接了列表中的各个字符串元素.
我想你也许好奇为什么我要在介绍C++的文章中写这么多 Haskell 的内容(这些内容还颇具挑战性),那是因为两个原因:
- 你可以知道 C++ 中相应算法的历史
- 比照 Haskell 的对应方法可以帮助我们理解 C++ 中 的相应算法.
好了,我们终于看个C++的示例了.
The seven new algorithms
做好心理准备,下面的代码可能有些难读.
#include <iostream>
#include <string>
#include <vector>
#include <execution>
int main()
{
std::cout << std::endl;
// for_each_n
std::vector<int> intVec{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; // 1
std::for_each_n(std::execution::par, // 2
intVec.begin(), 5, [](int& arg) { arg *= arg; });
std::cout << "for_each_n: ";
for (auto v : intVec) std::cout << v << " ";
std::cout << "\n\n";
// exclusive_scan and inclusive_scan
std::vector<int> resVec{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
std::exclusive_scan(std::execution::par, // 3
resVec.begin(), resVec.end(), resVec.begin(), 1,
[](int fir, int sec) { return fir * sec; });
std::cout << "exclusive_scan: ";
for (auto v : resVec) std::cout << v << " ";
std::cout << std::endl;
std::vector<int> resVec2{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
std::inclusive_scan(std::execution::par, // 5
resVec2.begin(), resVec2.end(), resVec2.begin(),
[](int fir, int sec) { return fir * sec; }, 1);
std::cout << "inclusive_scan: ";
for (auto v : resVec2) std::cout << v << " ";
std::cout << "\n\n";
// transform_exclusive_scan and transform_inclusive_scan
std::vector<int> resVec3{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
std::vector<int> resVec4(resVec3.size());
std::transform_exclusive_scan(std::execution::par, // 6
resVec3.begin(), resVec3.end(),
resVec4.begin(), 0,
[](int fir, int sec) { return fir + sec; },
[](int arg) { return arg *= arg; });
std::cout << "transform_exclusive_scan: ";
for (auto v : resVec4) std::cout << v << " ";
std::cout << std::endl;
std::vector<std::string> strVec{ "Only", "for", "testing", "purpose" }; // 7
std::vector<int> resVec5(strVec.size());
std::transform_inclusive_scan(std::execution::par, // 8
strVec.begin(), strVec.end(),
resVec5.begin(),
[](auto fir, auto sec) { return fir + sec; },
[](auto s) { return s.length(); });
std::cout << "transform_inclusive_scan: ";
for (auto v : resVec5) std::cout << v << " ";
std::cout << "\n\n";
// reduce and transform_reduce
std::vector<std::string> strVec2{ "Only", "for", "testing", "purpose" };
std::string res = std::reduce(std::execution::par, // 9
strVec2.begin() + 1, strVec2.end(), strVec2[0],
[](auto fir, auto sec) { return fir + ":" + sec; });
std::cout << "reduce: " << res << std::endl;
// 11
std::size_t res7 = std::transform_reduce(std::execution::par,
strVec2.begin(), strVec2.end(), 0u,
[](std::size_t a, std::size_t b) { return a + b; },
[](std::string s) { return s.length(); }
);
std::cout << "transform_reduce: " << res7 << std::endl;
std::cout << std::endl;
return 0;
}
与 Haskell 中的示例对应,我使用 std::vector 创建了整数列表 (1) 和字符串列表 (7).
在代码 (2) 处,我使用 for_each_n 将(整数)列表的前5个整数映射成了整数自身的平方.
exclusive_scan (3) 和 inclusive_scan (5) 非常相似,都是对操作的元素应用一个二元运算,区别在于 exclusive_scan 的迭代操作并不包含列表的最后一个元素, Haskell 中对应的表达式为: scanl (*) 1 ints.(译注:结果并不完全等同, Haskell 的 scanl 操作包含列表最后一个元素,后面提到的相关 Haskell 对应也是如此,注意区别)
transform_exclusive_scan (6) 执行的操作有些复杂,他首先将 lambda 函数 function [](int arg){ return arg *= arg; } 应用到列表 resVec3 的每一个元素上,接着再对中间结果(由上一步 lambda 函数产生的临时列表)应用二元运算 [](int fir, int sec){ return fir + sec; }(以 0 作为初始元素),最终结果存储于 resVec4.begin() 开始的内存处.Haskell 中对应表达式为:
scanl (+) 0 . map(\a -> a * a) $ ints.
(8) 中的 transform_inclusive_scan 和 transform_exclusive_scan 所执行的操作很类似,其中第一步的 lambda 函数将元素映射为了元素的长度,对应的 Haskell 表达式为:
scanl1 (+) . map(\a -> length a) $ strings.
现在,代码中的 reduce 函数 (9) 看起来就比较简单了,他需要在各个(字符串)元素之间放置 “:” 字符.因为结果的开头不能带有 “:” 字符, reduce 的迭代是从第二个元素开始的(strVec2.begin() + 1) ,并以第一个元素作为初始元素(strVec2[0]). Haskell 中对应表达式为: foldl1 (\l r -> l ++ “:” ++ r) strings.
如果你想深入了解一下 (11) 中的 transform_reduce,可以看看我之前的文章,这里同样给出 Haskell 中对应的表达式: foldl (+) 0 . map (\a -> length a) $ strings.
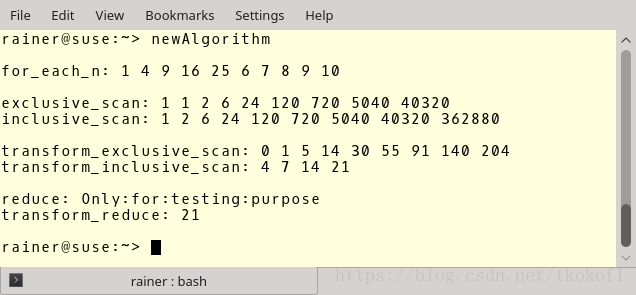
程序的输出如下,有兴趣的朋友可以仔细看看.
Final remarks
C++17 新引入的这7个算法有很多重载版本,调用的时候,你可以指定初始元素,也可以不指定初始元素,同样的,你可以指定执行策略,也可以不指定执行策略.你甚至可以在不指定二元运算的情况下调用需要二元运算的算法(例如std::reduce),这种情况下,这些算法会默认使用二元加法运算.为了能够以并行或者矢量并行的方式运行这些算法,指定给算法的二元运算必须满足可结合性,这个限制也很容易理解,因为并行化的算法很容易会在多个CPU核上同时运行(这种情况下,二元运算不可结合的话就会导致错误结果).更深入的一些信息你可以看看这里和这里.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK