

我是小M,老板不当人子(MySQL的故事)
source link: https://my.oschina.net/u/3944379/blog/5012770
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
我是小M,在卡拉巴拉星球。
是一个立志建立 MySQL 帝国的男人。
上回说到我入职了 Y 公司,建了个叫 B+ 树的玩意来管理数据。
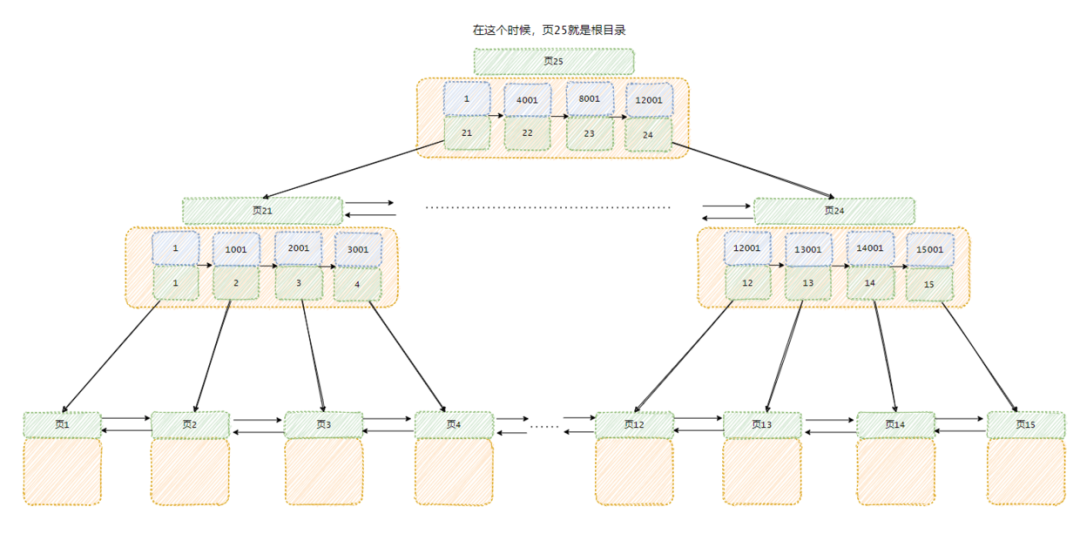
但是老板最后加了个需求,他需要通过姓名来查询用户的信息。
这....我是拿用户的 ID 来排序组装成索引的呀。
如果查询条件是姓名的话,这个索引就用不上了,那就得每页都翻阅过去,这就是全表扫描了呀!
查询的速度又会降下来了!
我盯着手上的奶茶思考了一会儿。

没办法,只能根据姓名再建立一个索引了。
这个索引的目录页没啥问题,把 ID 改为姓名,按字母序存储姓名和页号即可。
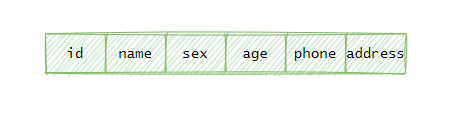
那索引的数据页存什么呢?难道把用户的所有信息都复制过来吗?
这也太冗余了,我这小办公室可装不下这么多数据。
嗦了几颗珍珠,来灵感了!
数据页只需要存储姓名和 ID 即可,这样我可以先通过姓名去找到 ID, 然后再通过 ID 去之前建立的那个索引查找全部数据,反正能利用索引查询都很快!
为了便于区分,我把之前用 ID 为主建立的索引称为聚簇索引。
现在用姓名建立的索引称为,“二级索引”或“辅助索引”。
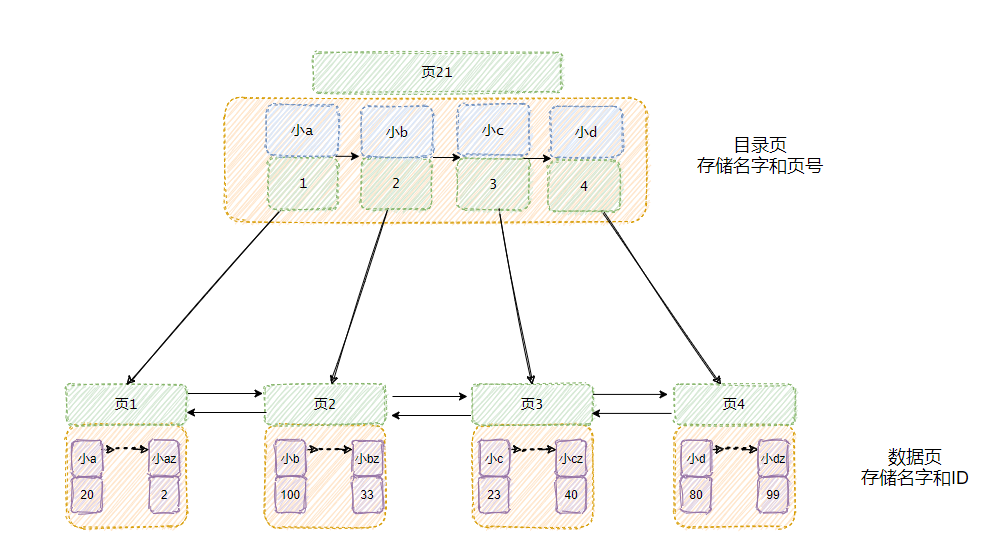
花了三天的时间,小 M 终于把这个由姓名为主的索引建好了!
“唉,数据有点多,这建索引还是费力的,还好这几天没人找我要数据,不然我可忙不过来。”
这个二级索引,帮助我解决了领导们依据姓名来查询数据的需求。
但是,二级索引的维护增加了我的工作量,之前我只要维护一个聚簇索引!
现在改个用户的姓名,我不仅得改聚簇索引上面的数据,同时还得修改二级索引呢!
如果有新添加的用户,除了往聚簇索引上插入数据,同时还得在二级索引上面也添加数据,删除也亦然。
不过,还好现在就一个二级索引,要是有十几个索引,我估计要改疯了!
上次有个憨憨领导说,“二级索引不错啊,索性你把所有字段都对应建立一个索引呗,未雨绸缪嘛。”

“无知!”
我还发现领导们很懒!每次查数据都说我要xxx的全部资料,然后实际上只要个 ID!
把我给气的!这是摆明是增加了我个工作量啊!
如果他说清楚只要 ID, 那我直接利用二级索引就能找到结果,就不需要再去聚簇索引上找数据了呀!
我把直接通过二级索引就能查询得到想要的数据,称为覆盖索引。
把需要利用二级索引查找 ID ,再回聚簇索引查找得到完整数据这一步骤,称为回表。
所以一些明明能用上覆盖索引的时候,老板偷懒想直接得到全部数据,害我不得不回表查询。
每次无用的回表查询我都拿小本本记录下来了,一共二十万七千三百五十二次!

我找他们说了这个事,有些小老板欣然接受,但有一些却说:“多说几个字好麻烦的。”
这些老板真的是!

不过有时候老板确实想要全部数据,所以我不得已还是得回表。
但渐渐地我发现,当查询的数据太多的时候,我先去二级索引查到得到 ID, 再拿 ID 去聚簇索引查找所花费的时间,还不如我直接全表扫描呢!
因此,根据姓名查询的时候,我不是无脑的利用二级索引+回表的操作,而是在脑海里进行一波评估。
如果需要回表的次数太多,那我就直接选择全表扫描!

有一段时间公司不知道怎么回事,老是有要查询一批男性或者女性数据的需求。
我寻思着公司是打算搞相亲大会嘛?
当时,我打算根据性别来建立个索引。
嗦了几颗珍珠之后我就感觉不太对劲,这性别也就男女两种选择呀。
即使我根据性别建了索引,这区分度也太低了。
假如公司有10W个男性、7W个女性,经过索引筛选最多只能过滤一半,留下的数据还是太多了,所以效率太低。
不划算不划算。
"咻咻",又吸了两口奶茶,我真佩服我的小脑袋瓜儿~
对了,我还发现老板们的记性还很差,每次姓名都叫不全。
经常会有老板说,“给我那个姓杨的资料。”
这种需求我可以接受,因为姓名已经根据字母序排序了,所以我通过索引可以定位到姓杨的同事们的数据。
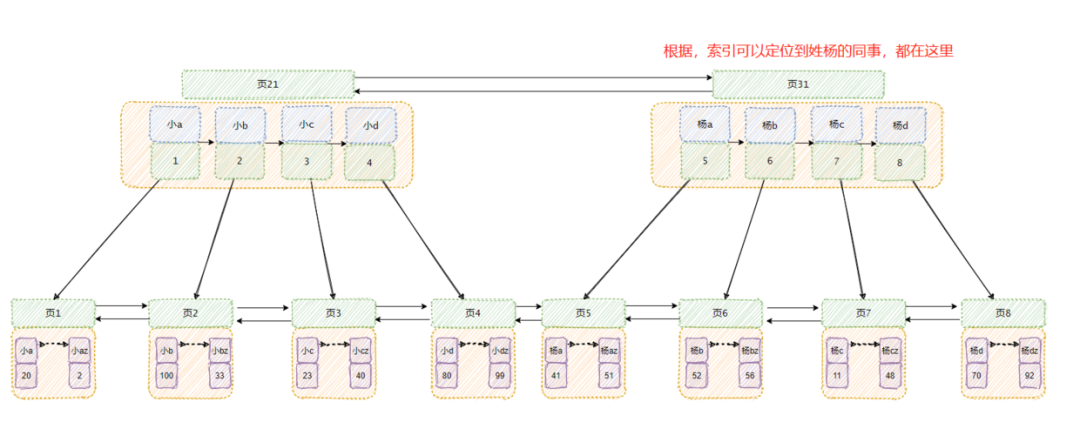
然后将这些数据都返回给领导就好啦!
但是有些领导姓记不住,他说给我找下叫 什么a 的人的资料。
这我就利用不上索引了呀!你看看上面的图,姓小的里面有叫a的、姓杨的里面也有叫a的,指不定别的姓里面也有呢,我就得把每个页都扫过去才行呀!
哎,这个索引终究不是万能的,它只能支持给予了左边条件(姓在名的左边)的查询请求,我称之为最左匹配原则。
看着办公室里面的数据越来越多,我对数据的操作也越发的得心应手。
这么多数据我都管理的妥妥当当,一份满足感油然而生,我真是个小天才。
这时大老板破门而入,“哟,007,上次给你发的 0.1 元年终奖花完了吗?”
这 Y 老板开口就是暴击,我心里:“@%#&*!”,嘴上:“还没呢大老板,请问有什么指示?”
Y老板:“我这里有个需求呀,我要......”
未完待续~
你好,我是 yes,这篇同样讲的是 MySQL InnoDB 索引的故事。
有些人可能没看过上一篇,我链接放这了,算是连贯的故事~
我补充一下回表,回表是因为查询的字段无法完全命中二级索引导致的。
回表的代价:
-
最直观的是多查一次,先去二级索引查,再去聚簇索引上查。
-
随机I/O问题。
如果你仔细看看上面的图会发现,二级索引上面的ID都是无序的。
所以如果你要查姓杨的资料,在二级索引上数据都是连续的,所以是顺序I/O,而每次回表查询的 ID 都不是连续的,也就无法用上磁盘预读功能,是随机I/O。
随机I/O的性能较差,所以如果查询的数据很多,需要回表的次数太多,那还不如直接全表扫描效率来的高。
在上面的故事中,我写到的是根据小M的小脑袋瓜里面进行一波评估是要二级索引+回表还是全表扫描。
在 MySQL 中是根据查询优化器来决定的,MySQL 会有一些预估值来作为参考,到底是哪一个划算,然后再决定用何种方式来查询。
好了,今儿就到这里。
我是yes,从一点点到亿点点,我们下篇见~
欢迎关注我的公众号【yes的练级攻略】,更多硬核文章等你来读。

本文分享自微信公众号 - yes的练级攻略(yes_java)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK