

Python爬虫实战:抓取博客文章列表
source link: https://blog.csdn.net/nokiaguy/article/details/114326333
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Python爬虫实战:抓取博客文章列表
本文节选自《Python爬虫技术:深入理解原理、技术与开发》。

本文将实现可以抓取博客文章列表的定向爬虫。定向爬虫的基本实现原理与全网爬虫类似,都需要分析HTML代码,只是定向爬虫可能并不会对每一个获取的URL对应的页面进行分析,即使分析,可能也不会继续从该页面提取更多的URL,或者会判断域名,例如,只抓取包含特定域名的URL对应的页面。
这个例子抓取博客园(https://www.cnblogs.com)首页的博客标题和URL,并将博客标题和URL输出到Console。
编写定向爬虫的第一步就是分析相关页面的代码。现在进入博客园页面,在页面上单击鼠标右键,在弹出菜单中单击“检查”菜单项打开开发者工具,然后单击开发者工具左上角黑色箭头,并用鼠标单击博客园首页任意一个博客标题,在开发者工具的Elements面板会立刻定位到该博客标题对应的HTML代码,图1中黑框内就是包含博客园首页所有博客标题以及相关信息的HTML代码。

图1 博客标题以及相关信息对应的HTML代码
接下来让我们分析相关的HTML代码。为了更容易识别相关的代码,将第一条博客相关的HTML代码提出来,如下所示:
从这段代码中可以找到很多规律,例如,每条博客的所有信息都包含在一个<div>节点中,这个<div>节点的class属性值都是post_item,每一条博客的标题和URL都包含在一个<a>节点中,这个<a>节点的classs属性值是titlelnk。根据这些规律,很容易过滤出我们想要的信息。由于本例只需要得到博客的标题和URL,所以只关注<a>节点即可。
本例的基本原理就是通过正则表达式过滤出所有class属性值为titlelnk的<a>节点,然后从<a>节点中提炼出博客标题和URL。
程序运行结果如图2所示。
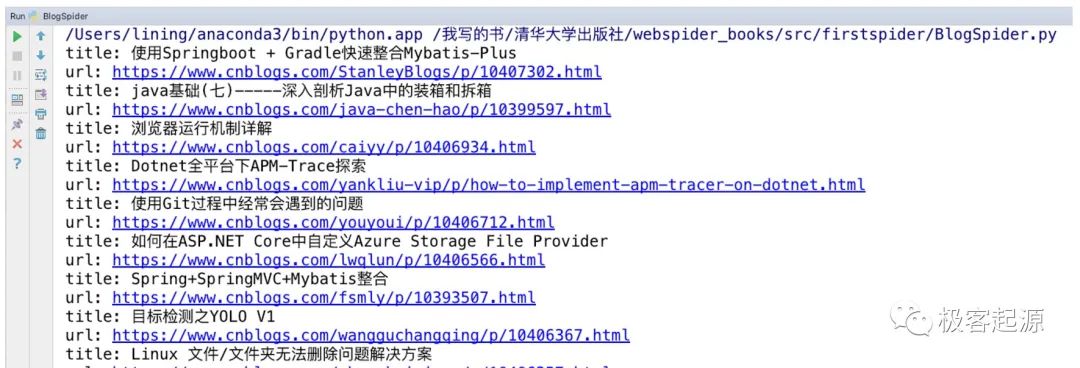
图2 抓取博客列表的效果
本例在提取<a>节点以及URL时使用了正则表达式,而提取博客标题时直接通过Python语言的字符串搜索功能实现的。其实过滤HTML代码的方式非常过,包括普通的字符串搜索API,正则表达式,以及后面要学习的XPath、Beautiful Soup、pyquery。读者可以根据实际情况来选择过滤方式。例如,过滤规则比较简单,就可以直接用Python语言的字符串搜索API进行过滤,如果过滤规则非常复杂,可以利用Beautiful Soup和XPath来完成任务。
- EOF -
推荐阅读 点击标题可跳转
Python装饰器(decorator)不过如此,是我想多了
关注「极客起源」公众号,加星标,不错过精彩技术干货

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK