

[Reading] SSD: Single Shot MultiBox Detector
source link: https://blog.nex3z.com/2021/04/09/reading-ssd-single-shot-multibox-detector/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

[Reading] SSD: Single Shot MultiBox Detector
Author: nex3z 2021-04-09
SSD: Single Shot MultiBox Detector (2015/12)
Contents [show]
文章的主要贡献有:
- 提出了一种快速的单次(single-shot)目标检测器,称为 Single Shot Detector(SSD)。SSD 使用单个网络进行目标检测的方法,方法简单,易于训练,速度很快,同时也具有相当的准确度。
- 通过在多个特征图上输出多尺度的边界框,实现多尺度的检测。
当时的目标检测系统通常包含多个步骤:对边界框进行假设,再在边界框上进行像素或特征的重采样,最后使用分类器对框内物体进行分类。这样构造的系统非常准确,但计算量也很大,不适合在嵌入式系统中使用,即便在高端硬件平台上也无法做到实时预测。
SSD 的一大特色是在多个特征图上输出多尺度的边界框。通过将输出空间离散化为特征图各个位置上的不同长宽比例和尺寸的 default box ,网络预测每个 default box 中各个类别出现的概率,并对边界框进行调整来匹配物体形状。整个过程都在单个网络中计算完成,不需要生成候选区域,也不需要对像素或特征进行重采样。
虽然在之前 Overfeat 和 YOLO 都实现了单阶段的快速检测,但文章使用了一系列改进,包括使用小卷积过滤器来预测类别和边界框偏移,为不同长宽比例使用独立的过滤器,以及在多个特征图上使用这些过滤器来实现多尺度检测,这些改进对性能有显著提升。使用 300×300 的输入时,SSD 可以在 VOC2007 测试集上以 59 FPS 的速度(Titan X)达到 74.3% mAP。使用 512×512 分辨率时可以达到 76.9% mAP。
SSD 的不足之处在于,非常密集的采样使得正负样本的比例严重不均衡,增加了训练的难度,并对最终的性能产生影响。由于网络越往后特征图越小,SSD 较难对小物体进行分类,文章使用数据增强来提高检测小物体的准确率。
2. SSD
2.1. 模型
SSD 是一个卷积网络,如 Fig 2 所示。用于目标检测时,会输出一组固定数量的边界框,以及各个类别出现在框内的分数,然后通过 NMS(non-maximum suppression)得到最终的检测结果。网络的前端是标准的分类网络,在之后添加了额外的结构来输出检测结果,检测部分的主要特点如下。
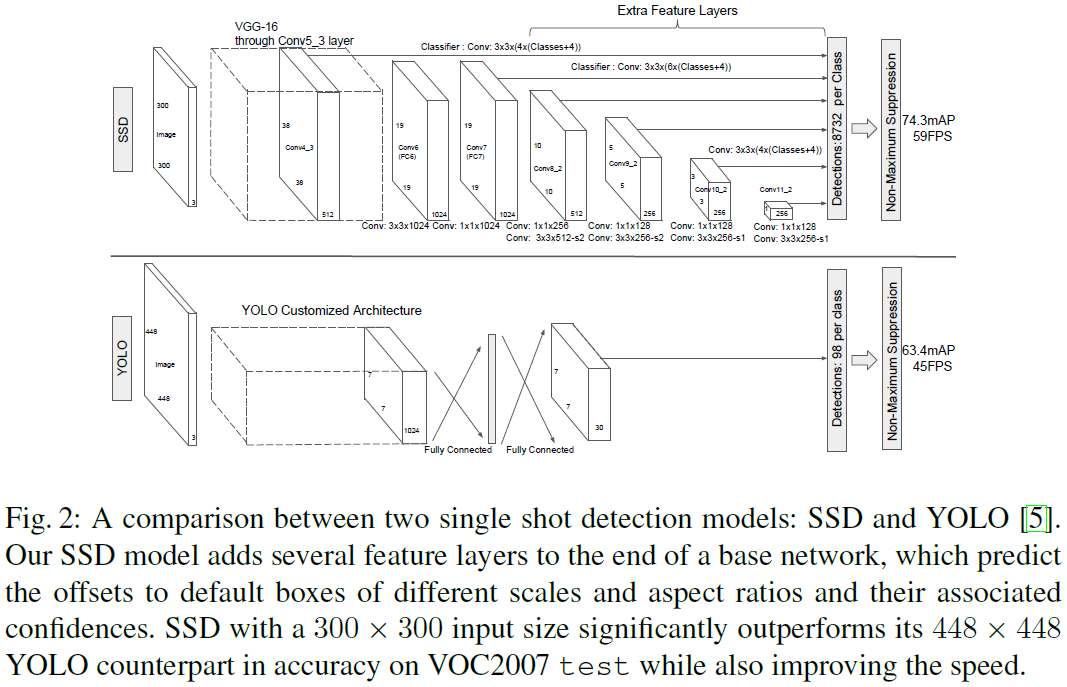 Fig 2
Fig 22.1.1. 多尺度特征图
在基础网络后添加了一系列尺寸逐渐减小的卷积特征层,在每一个特征层使用不同的卷积模型进行预测,实现多尺度的检测。相比之下,Overfeat 和 YOLO 都是在单尺度的特征图上进行预测。
2.1.2. 卷积预测器
每一个特征层都使用一组卷积过滤器来生成一组检测结果,如 Fig 1 所示。对于 m×n×p 的特征图,使用一个 3×3×p 的小过滤器,在 m×n 的每一个位置,对预测类别分数、边界框相对于 default box 的偏移量等进行预测。需要多个这样的过滤器,来得到所需的各个输出,如下所述。
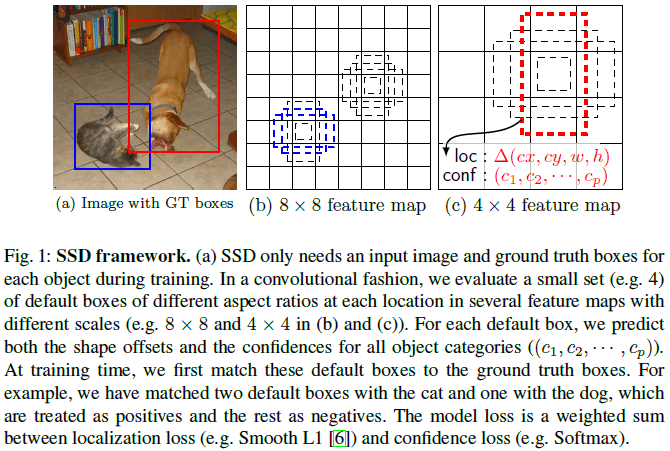 Fig 1
Fig 12.1.3. default box 和长宽比例
文章在特征图的每个位置上都使用了一组 default box,如 Fig 1 所示。通过在每个位置上预测目标相对于 default box 的偏移来得到边界框的位置,并预测每个类别出现在框内的分数。
对于每个边界框,要计算 c 个类别分数和 4 个偏移量;在每个位置上要预测 k 个边界框,于是总共需要 (c+4)k 个过滤器,这个过滤器要在 m×n 的特征图的每个位置上进行计算,得到 (c+4)kmn 个输出。
这里的 default box 类似于 Faster R-CNN 中的锚点框(anchor box),区别在于这里把 default box 用在不同分辨率的多个特征图,在多个特征图上使用不同的 default box 可以更有效地将输出边界框形状的空间离散化。
2.2. 训练
在训练 SSD 时,需要先将真实信息分配给特定的输出,之后可以使用待见啊函数和反向传播进行端到端的训练。训练时需要选择合适的 default box 和尺寸,并进行难例挖掘和数据增强。
2.2.1. 匹配策略
在训练时,需要决定哪个 default box 对应了真实的目标,即标注框,然后据此训练网络。众多的 default box 具有不同的位置、尺寸和长宽比,在进行匹配时,首先将每一个标注框匹配到具有最大 IOU(即 jaccard overlap)的 default box ;然后再将各 default box 匹配到与之 IOU 大于某个门限(0.5)的标注框。这样的匹配方式可以简化学习问题,使得网络可以对多个重叠的 default box 给出较高的预测分数,而不是选择具有最大重叠的一个。
2.2.2. 训练目标
记 xpij={1,0} 为将第 i 个 default box 匹配到类别 p 的第 j 个标注框的指示函数,由上述匹配策略,有 ∑ixpij≥1,即每个标注框会被匹配到至少 1 个 default box 。全局损失函数为定位损失(loc)和置信度损失(conf)的加权和
L(x,c,l,g)=1N(Lconf(x,c)+αLloc(x,l,g))
其中 N 为匹配的 default box 的数量,如果 N=0,则损失为 0。α 用于平衡两个损失,根据交叉验证设置为 1。l 为预测框,g 为标注框,定位损失为二者的 Smooth L1 损失,即
Lloc(x,l,g)=∑i∈Pos∑m∈{cx,cy,w,h}xkijsmoothL1(lmi–ˆgmi)
其中 cx,cy 表示框的中心坐标,w,h 表示框的宽和高。∑m∈{cx,cy,w,h} 表示 m 依次取 {cx,cy,w,h} 这 4 个维度之一,计算 Smooth L1 损失并相加,即计算这 4 个维度的损失之和。
类似于 Faster R-CNN,SSD 对边界框位置的回归目标是相对于 default box(d)中心(cx,cy)的偏移,对边界框宽高(w,h)的回归目标是二者与 default box 宽高之比的对数,即
ˆgcxj=(gcxj–dcxi)/dwiˆgcyj=(gcyj–dcyi)/dhiˆgwj=log(gwjdwi)ˆghj=log(ghjdhi)
置信度损失是在各个类别上置信度 c 的 softmax 损失
Lconf(x,c)=−N∑i∈Posxpijlog(ˆcpi)−N∑i∈Neglog(ˆc0i)
ˆcpi=exp(cpi)∑pexp(cpi)
2.2.3. 选择 default box 的尺寸和长宽比
为了检测不同尺寸的物体,之前的一些方法选择将图像预处理到不同的尺寸,进行检测并合并结果。SSD 的做法是检测单个网络中不同层的的特征图,充分利用网络的中间计算。如 Fig 1 所示,Fig 1b 和 Fig 1c 分别在 8×8 和 4×4 的特征图上进行检测。
SSD 通过使用一系列不同尺寸的 default box ,希望特定的特征图能够学会检测特定尺寸的物体。假设有 m 个特征图进行预测,每一个特征图使用的 default box 的尺寸为
sk=smin+smax–sminm–1(k–1),k∈[1,m]
其中 smin=0.2,smax=0.9,即最低和最高的尺寸分别为 0.2 和 0.9。
default box 也具有不同的长宽比,记 ar∈{1,2,3,12,13},则每个 default box 的长和宽分别为 wak=sk√ar、hak=sk/√ar。对于长宽比为 1 的 default box ,额外添加一个尺寸为 s′k=√sksk+1 的 default box 。由此特征图的每个位置上有 6 个 default box 。
值得注意的是,在如 Fig 2 所示的架构中,conv4_3、conv10_2 和 conv11_2 三层只使用了 4 种 default box,省去了 13 和 3 两种长宽比。
每个 default box 的中心位置设置为 (i+0.5|fk|,j+0.5|fk|),其中 |fk| 为第 k 个正方形特征图的尺寸,i,j∈[0,|fk|)。
结合多个特征图上不同位置、不同尺寸、长宽比例的 default box 的预测后,就得到了覆盖各种对象尺寸和形状的一组预测。如 Fig 1 所示,图中的狗匹配到了 4×4 特征图上的 default box ,而没有匹配到 8×8 的特征图上,因为 8×8 特征图中没有适合狗的尺寸的 default box 。
2.2.4. 难例挖掘
一张图像中通常只有少数几个物体,大部分 default box 都是负例,导致正例和负例的不平衡。文章对负例的 default box 根据置信度损失进行排序,选择最高的一部分负例,使得负例和正例的比例约为 3:1。这样可以加快优化速度,并使得训练更稳定。
2.2.5. 数据增强
文章对训练样本随机使用了如下的增强:
- 使用完整的原始图像
- 采样一个与对象最小 IOU 为 0.1、0.3、0.5、0.7 或 0.9 的图块
- 随机采样一个图块
采样的图块的尺寸范围为 [0.1,1],长宽比在 12 和 2 之间,如果标注框的中心在图块内,则保留重叠部分的标注框。之后将图块缩放到固定尺寸,进行随机的水平翻转,再加上一些扰动。
3. 实验结果
3.1. PASCAL VOC2007
文章比较了 SSD 在 VOC2007 上的性能,如 Table 1 所示。在使用 300×300 的分辨率时,SSD 的性能已经超过了 Faster R-CNN。在使用 512×512 的分辨率时,SSD 取得了最高的 81.6 的 mAP。
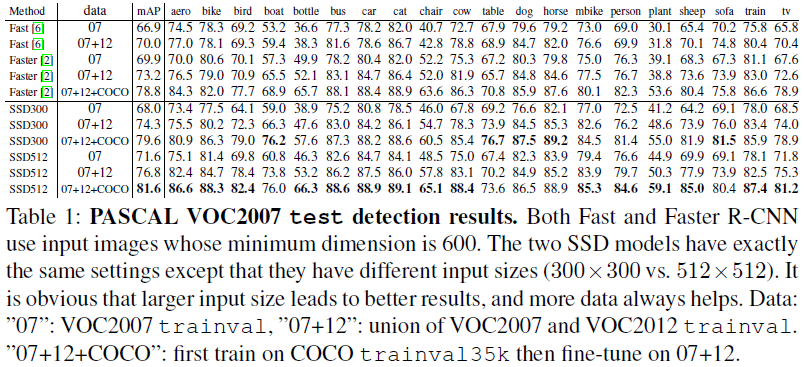 “Table 1
“Table 1文章进一步分析了 SSD 的性能如 Fig 3 所示。可见 SSD 可以给出高质量的预测。和 Faster R-CNN 相比,SSD 的定位错误更少,说明 SSD 通过直接学习回归物体形状和类别,可以获得更好的效果。SSD 较难区分相似类别的物体(如动物),部分原因是多个类别会共享位置。
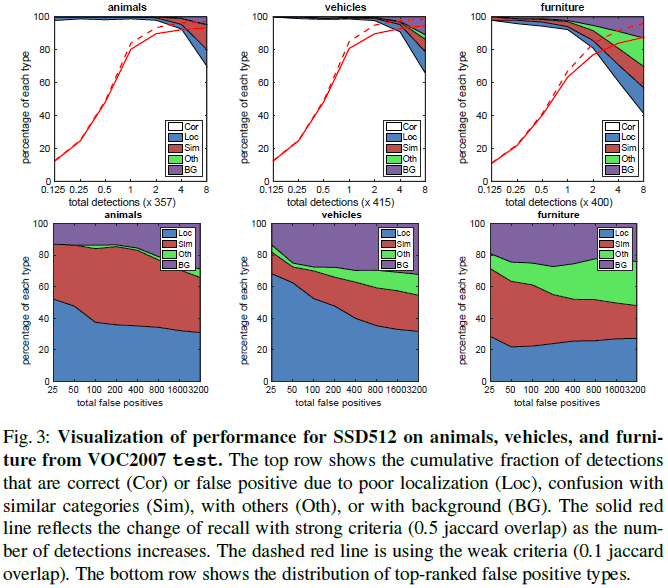 Fig 3
Fig 3Fig 4 表明 SSD 对边界框的尺寸非常敏感,在小物体上的效果要大幅差于大物体,因为在顶部的特征图中小物体的信息很少,增大分辨率有助于改善小物体的识别,但仍有提升空间。
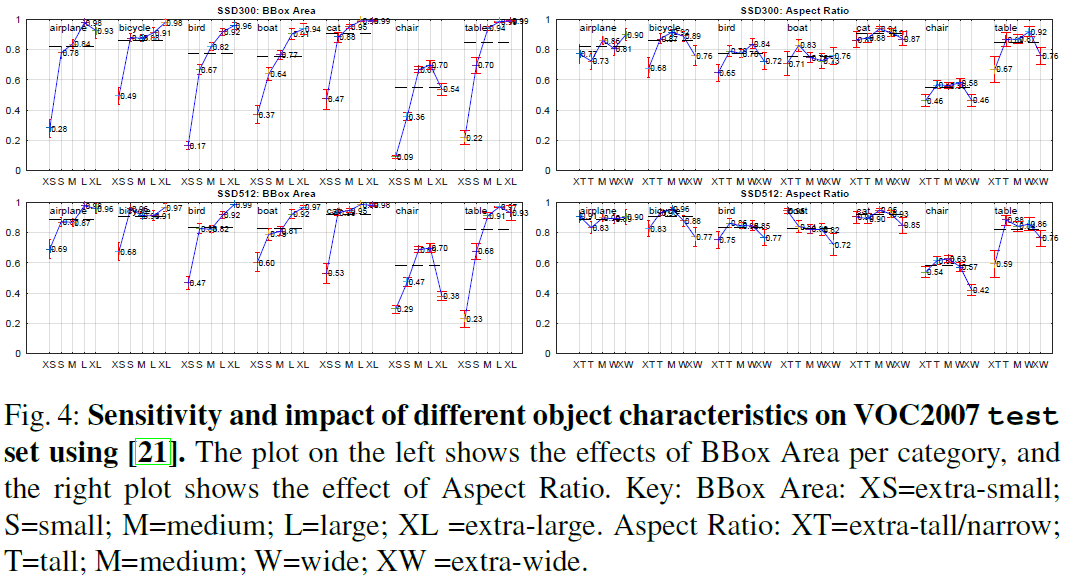 Fig 4
Fig 43.2. 模型分析
文章分析了 SSD 中的不同组件对性能的影响,如 Table 2 所示,可见数据增强可以带来很大的提升, default box 的形状越多性能也会越好。
 “Table 2
“Table 2SSD 的一大特点是在不同的输出层上使用不同尺寸的 default box 。文章比较了使用不同层进行预测的效果,如 Table 3 所示。可见使用的层数越多,mAP 越高,但使用最粗粒度的 conv11_2 会使得性能下降。只使用 conv7 时性能最差,说明在不同的层上使用不同尺寸的 default box 非常重要。
 “Table 3
“Table 3Recommend
-
37
README.md SSD: Single Shot MultiBox Object Detector, in PyTorch A PyTorch implementation of
-
31
README.md This is a PyTorch Tutorial to Object Detection. This is the third in
-
12
论文标题:SSD: Single Shot MultiBox Detector 论文作者: Wei Liu ,
-
14
RetinaFace 因为其速度快,精度高,是工程中常用的人脸检测模型,和 SSD 一样,它在训练和预测阶段也采用了先验框。最近拿到一份 PyTorch 版本的 RetinaFace,在损失函数(loss function)部分,明显采用了 SSD 的 multibox loss 计算方法。研究某个深度...
-
18
Single Shot MultiBox Detector (SSD) on Jetson TX2 Nov 30, 2017 2019-05-16 update: I just added the Installing and Testing SSD Caffe on Jetson Nan...
-
12
论文速递 | 基于 IoU 分支的 IoU-aware Single-stage Object Detector 11个月前...
-
10
Reading Self-supervised Single-view 3D Reconstruction via Semantic Consistency 发表 2022-01-22...
-
10
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid NetworkQijieZhao1, TaoSheng1, YongtaoWang1∗, ZhiTang1, YingCh...
-
6
Home ...
-
7
Reading Few-shot Video-to-Video Synthesis 2022-05-13
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK