

[Reading] Searching for MobileNetV3
source link: https://blog.nex3z.com/2021/04/06/reading-searching-for-mobilenetv3/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
[Reading] Searching for MobileNetV3
Author: nex3z 2021-04-06
Searching for MobileNetV3 (2019/5)
Contents [show]
文章的主要贡献有:
- 提出了一种新的用于构建高效网络的 block 结构,结合了 MobileNetV1 中的深度可分离卷积、MobileNetV2 中的 linear bottleneck 和 inverted residual,以及 MnasNet 在 bottleneck 中使用 SE(squeeze and excitation)的结构。
- 使用硬件感知的网络架构搜索的方法(hardware-aware network architecture search)对网络架构进行搜索,针对手机 CPU 进行优化。使用 block-wise 和 layer-wise 两种互补的搜索方法,并进一步对网络的设计进行调整,如重设计计算量大的层,使用更高效的 h-swish 激活函数等,在保持性能的基础上进一步降低计算量。这些优化技巧也考虑了量化这一在移动端模型上常用的处理步骤,使得模型能更好地部署在实际设备上。
- 提出了名为 MobileNetV3 的新一代 MobileNets,进一步提高了准确率,并降低了计算量。针对计算资源的限制,给出了 MobileNetV3-Large 和MobileNetV3-Small 两种模型,以在资源和性能之间进行取舍。
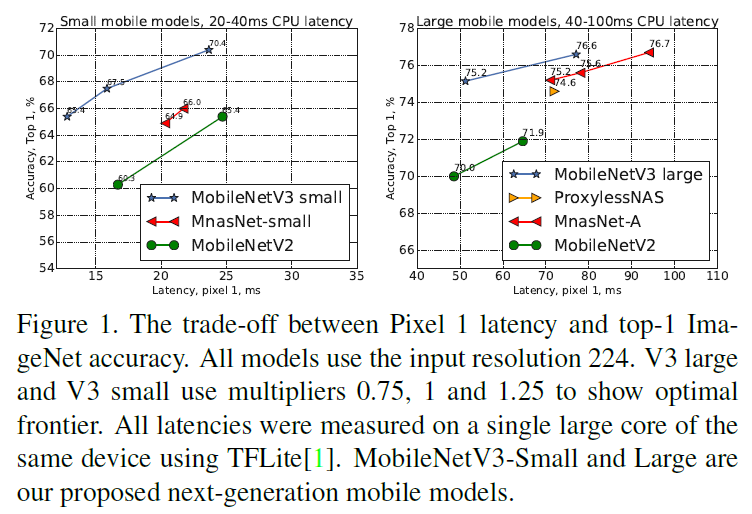 Figure 1
Figure 1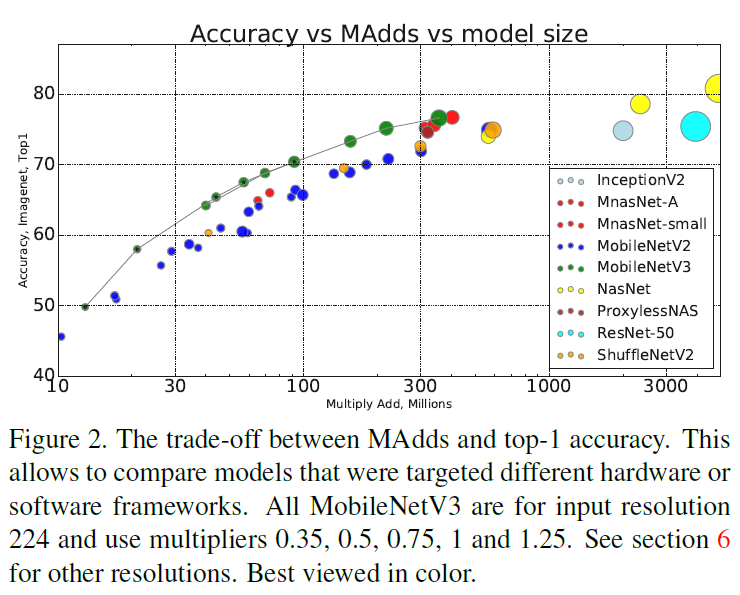 Figure 2
Figure 22. Building Block
回顾 MobileNets 系列模型,MobileNetV1 引入了深度可分离卷积(depthwise separable convolution),将标准的卷积分解为一个 depthwise 卷积和一个 1×1 pointwise 卷积,大幅降低了计算量。
MobileNetV2 引入的 bottleneck residual block 先将输入扩展到高维,然后进行 depthwise 卷积,再压缩回低维,同时通过 residual connection 连接输入和输出(仅当输入和输出具有相同的通道数),如 Figure 3 所示。
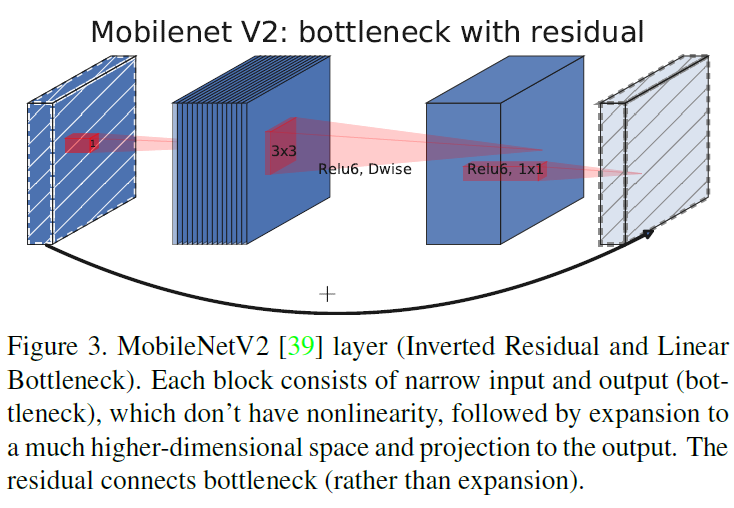 Figure 3
Figure 3之后出现的 MnasNet 在 MobileNetV2 的基础上引入注意力机制,在 bottleneck 中加入了基于 SE 的轻量级注意力模块。为了让注意力能作用在最大尺寸的特征表示上,SE 模块放在 depthwise 卷积之后,如 Figure 4 所示。
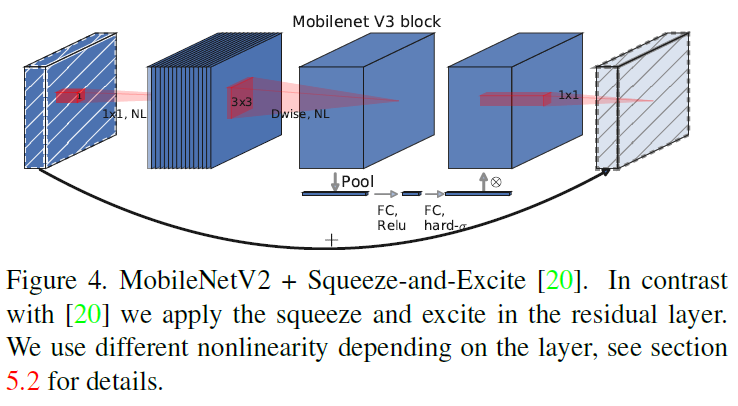 Figure 4
Figure 4MobileNetV3 充分吸收了前面的工作,构造更加高效的模型。
3. 网络搜索
如标题中的 Searching 所强调的,文章通过网络搜索技术得到了 MobileNetV3 的基本结构。具体来说,文章使用了互补的两种搜索技术:首先通过 platform-aware NAS 对各个 block 进行优化,来搜索全局的网络结构;然后通过 NetAdapt 算法搜索每层的过滤器数量。
3.1. Block-wise Search
首先进行的 block-wise search 使用了 platform-aware NAS。这是一个多目标的搜索,同时优化准确率和 延迟,优化目标为 ACC(m)×[LAT(m)/TAR]w,其中 ACC(m) 和 LAT(m) 分别为模型 m 的准确率和延迟,TAR 为目标延迟,w 是一个用于在准确率和延迟之间取舍的超参数,platform-aware NAS 原文使用 w=−0.07。文章注意到对于小模型,准确率的变化要比延迟的变化大得多,因此使用了更小(绝对值更大)的 w=−0.15,来放大延迟的变化。通过这一步得到初始的种子模型。
3.2. Layer-wise Search
在得到种子模型后,文章又通过 NetAdapt 按顺序对各个层进行微调,作为 platform-aware NAS 的补充,大致步骤为:
- 使用通过 platform-aware NAS 得到的种子网络架构作为初始网络。
- 对每一步:
- 生成一系列候选,每一个候选代表对架构的一个改动,使得延迟比上一步得到的结果至少减少 δ。
- 对于每一个候选,使用上一步得到的预训练模型填充候选架构,对于缺失的权重,进行适当的裁剪和随机初始化。对每一个候选进行 T 步的 fine tune,来得到对准确率的一个粗粒度的估计。
- 根据特定指标选择最佳候选。
- 不停迭代上述步骤,直到达到目标延迟。
文章使用的产生候选的方法为:
- 减小任意扩展层(expansion layer)的尺寸;
- 减小所有 block 中具有相同尺寸的 bottleneck,这里强调 bottleneck 具有相同尺寸是为了保持 residual connection。
NetAdapt 原文中使用的指标是最小化准确率变化,而本文使用的指标是最小化延迟变化和准确率变化之比,即最大化 ΔAcc|Δlatency|,即选择能最大化收益曲线斜率的候选。
持续执行以上步骤,直到延迟达到目标延迟,然后重新训练整个新模型。
4. 网络改善
在网络搜索的基础上,文章还对网络结构进行了进一步改善,在保证准确率的基础上,降低计算量。
4.1. 重新设计大计算量的层
4.1.1. 末端
在网络末端输出用于分类的最终特征时,MobileNetV2 仍使用了 bottleneck,如 MobileNetV2 中 Table 2 所示。最后一个 bottleneck 输出的是压缩后的低维特征,尺寸为 7×7×320。为了给接下来的分类提供足够多的特征,还需要通过 1×1 卷积将特征扩展到高维,得到 7×7×1280 的特征图,再通过平均池化。扩展到高维的步骤会引入大量的延迟。
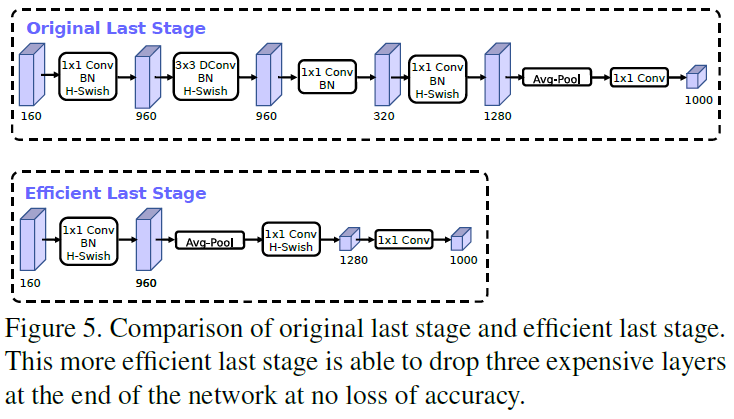 Figure 5
Figure 5为了在保留高维特征的前提下降低延迟,文章将特征扩展移到了最后的平均池化之后,池化后的特征图分辨率只有 1×1,相比之前的 7×7,在进行维度扩展的计算量会大幅降低。由于这里已经降低了计算量,就不再需要 bottleneck 来降低计算量了,可以移除 bottleneck 中的 depthwise 卷积和压缩步骤,进一步降低计算复杂度,如 Figure 5 下图所示。这一结构可以降低 7ms 的延迟(占总计算时间的 11%),降低了 30M 的 MAdds,同时几乎没有损失准确率。
4.1.2. 前端
MobileNetV2 在第一层使用了 32 个 3×3 的过滤器,也引入了大量的计算。文章通过实验,最终选择使用 16 个过滤器和 h-swish 激活函数,在保持准确率的前提下,减少了 2ms 的延迟和 10M 的 MAdds。
4.2. 非线性
4.2.1. 非线性的近似
相比 ReLU,swish 激活函数可以显著提高神经网络的准确率,其定义如下:
swishx=x⋅σ(x)
其中 σ(x) 为 sigmoid 函数,它的计算量要比 ReLU 大得多。为了让 swish 更适合在移动端使用,文章提出了两个解决方法。
其一是使用一个计算量更少的 h-sigmoid 函数来对 sigmoid 进行近似,如下所示:
h-sigmoid[x]=ReLU6(x+3)6
由此得到对 swish 的近似:
h-swish[x]=xReLU6(x+3)6
二者和原始函数的比较如 Figure 6 所示。
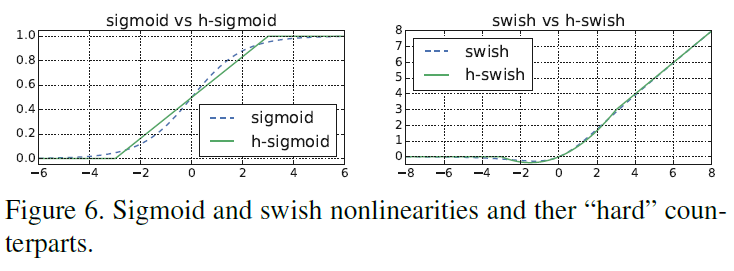 Figure 6
Figure 6文章通过实验得知,使用这些近似函数并不会对准确率产生可见的影响,同时由于 ReLU6 在各种软硬件框架中都有高效实现,且这些近似函数在量化时不会受到精度损失,再加上 h-swish 可以实现为分段函数来进一步降低内存访问并降低延迟,使得这些近似函数更适合实际部署。
4.2.2. 非线性的使用
随着层数的深入,特征的分辨率会逐渐减小,因此计算非线性的代价也在逐渐降低。文章指出,swish 的大部分效用发生在较深的层中,因此只在后半段网络中使用 h-swish。
5. MobileNetV3 网络结构
使用如上所述的各种技术,文章给出 MobileNetV3-Large 和 MobileNetV3-Small 的网络结构分别如 Table 1 和 Table 2 所示。
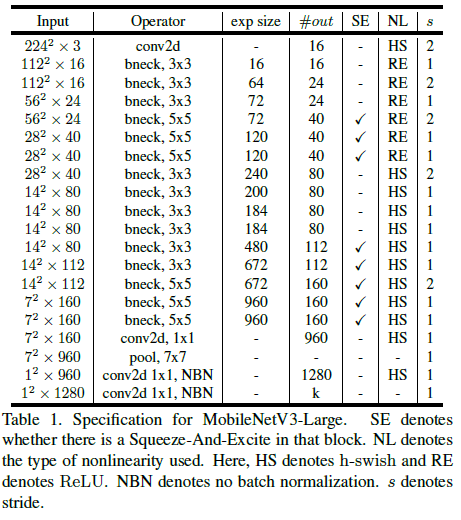 Table 1
Table 1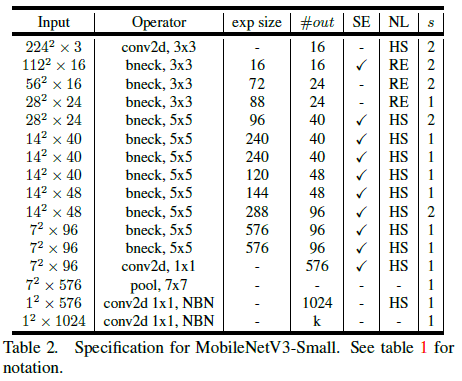 Table 2
Table 26. 实验结果
文章最后给出了 MobileNetV3 在分类、检测、语义识别任务上的性能。对于分类任务,文章给出了浮点和量化后两种情况的性能,并比较了不同 multipliers 和分辨率的性能差异,以及不同非线性的差异。对于目标检测,仍使用了 SSDLite。在语义分割任务上,文章在 R-ASPP 的基础上进行改进,得到了新的轻量级分割解码器,称为 LR-ASPP(Lite R-ASPP)。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK