

天罗地网——Python爬虫初初初探
source link: https://blog.csdn.net/eclipsexys/article/details/48193541
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
天罗地网——Python爬虫初初初探
Python
我们使用Python2.7进行开发,注意配置好环境变量。
我们使用Pycharm进行开发,它和大名鼎鼎的Android Studio、IDEA同出一门——Jet Brains。
关于破解,很无耻的贴两个:
用户名:yueting3527
注册码:
===== LICENSE BEGIN =====
93347-12042010
00001FMHemWIs"6wozMZnat3IgXKXJ
2!nV2I6kSO48hgGLa9JNgjQ5oKz1Us
FFR8k"nGzJHzjQT6IBG!1fbQZn9!Vi
===== LICENSE END =====用户名:yueting3527
注册码:
===== LICENSE BEGIN =====
93347-12042010
00001FMHemWIs"6wozMZnat3IgXKXJ
2!nV2I6kSO48hgGLa9JNgjQ5oKz1Us
FFR8k"nGzJHzjQT6IBG!1fbQZn9!Vi
===== LICENSE END =====Requests模块
Requests模块是一个用于替代Python URLLib2的一个第三方网络请求库。
- Windows:pip install requests
- Linux & Mac:sudo pip install requests
但由于有些比较奇怪的原因,导致这个下载过程异常艰辛,所以我们经常需要使用这样一个网站来帮助我们下载:
http://www.lfd.uci.edu/~gohlke/pythonlibs/
这里面镜像收集了几乎所有的Python第三方库,我们搜索Requests,点击下载。
下载完毕后,更改后缀名为zip。并将解压出的Requests文件夹放到Python的Lib文件夹下。
通过Requests获取网页源代码
无反爬虫机制
直接使用Requests库的get方法获取网页源代码:
import requests
html = requests.get('http://www.hujiang.com/')
print(html.text)
在终端中,我们就可以看见生成的网页源代码了。
有反爬虫机制
但是,很多网站并不会轻松的让爬虫获取到网页信息,这时候,我们就需要通过修改Http头信息的方式来获取。
例如我们使用同样的代码去爬我的博客 http://blog.csdn.net/eclipsexys 在终端中,我们可以看见这样一段话:
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>403,这时候,我们就需要修改下爬虫代码。
首先,我们在页面上点击右键选择审查元素,找到Network,刷新下, 选择任意一个元素,找到最后的User—Agent:
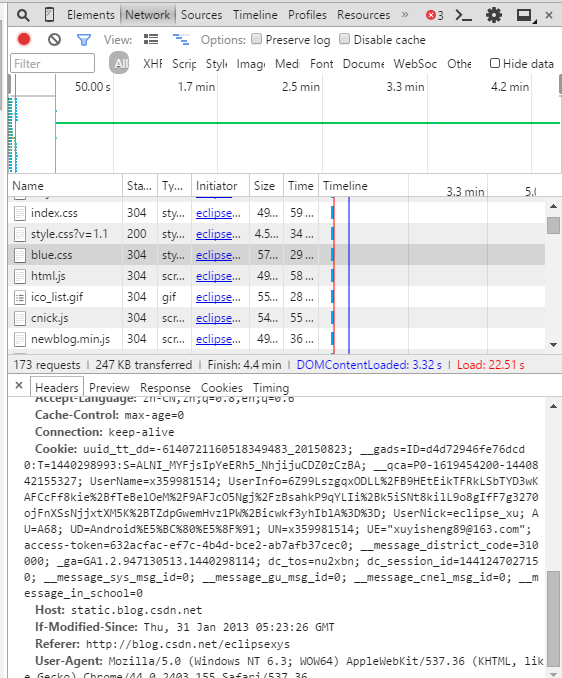
User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36
这就是我们的Http请求头。现在我们修改代码:
import requests
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
html = requests.get('http://blog.csdn.net/eclipsexys', headers = head)
print(html.text.encode('utf-8'))
添加请求头,并设置下编码格式为UTF-8。(Windows下默认为GBK,请先修改coding为UTF-8)
ps: 在Python文件中,如果我们要输入中文,需要指定下文件的字符集:
# coding=utf-8
具体见 https://www.python.org/dev/peps/pep-0263/
我们再运行,现在就可以正常获取源代码了。
Requests正则搜索
直接get出来的内容,都是网页的所有源代码,这肯定不是我们需要的,所以,我们可以通过正则表达式来提取我们所需要的内容。
例如,我们想提取网页中的所有超链接,OK,我们来看如何实现:
首先我们需要引入re模块,re模块是正则表达式的模块,使用与web端的正则一样:
import requests
import re
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'}
html = requests.get('http://www.hujiang.com/', headers=head)
html.encoding = "utf-8"
href = re.findall('<a target="_blank" href="(.*?)"', html.text, re.S)
for each in href:
print each
向网页提交数据
Get与Post
他们的区别如下所示:
- Get是从服务器上获取数据
- Post是向服务器传送数据
- Get通过构造url中的参数来实现功能
- Post将数据放在header提交数据
网页分析工具
Chrome调试功能——Network调试
在Network中找到Post提交的地方,找到Form Data,这就是表单数据。
Post方式提交表单。
import requests
import re
url = 'https://www.crowdfunder.com/browse/deals&template=false'
data = {
'entities_only':'true',
'page':'2'
}
html_post = requests.post(url,data=data)
title = re.findall('"card-title">(.*?)</div>',html_post.text,re.S)
for each in title:
print eachXPath
XPath,就是XML路径语言,我们在寻找一个元素时,如果使用正则表达式,可以这么说,我要找一个长头发、180cm的女人。那么如果要用XPath来表达,就是XX公司XX部门的前台。
在Python中使用XPath,我们需要使用第三方模块lxml,安装如同Requests。
获取HTML的XPath路径
打开Chrome的审核元素,我们找到任何一个元素,点击右键,选择copy XPath即可。
当然,我们也可以手写,它的基本语法如下:
- //定位根节点
- /往下层寻找
- 提取文本内容:/text()
- 提取属性内容: /@xxxx
比如我们选择这个地址:http://www.imooc.com/course/list?c=android&page=2
打开审核元素:
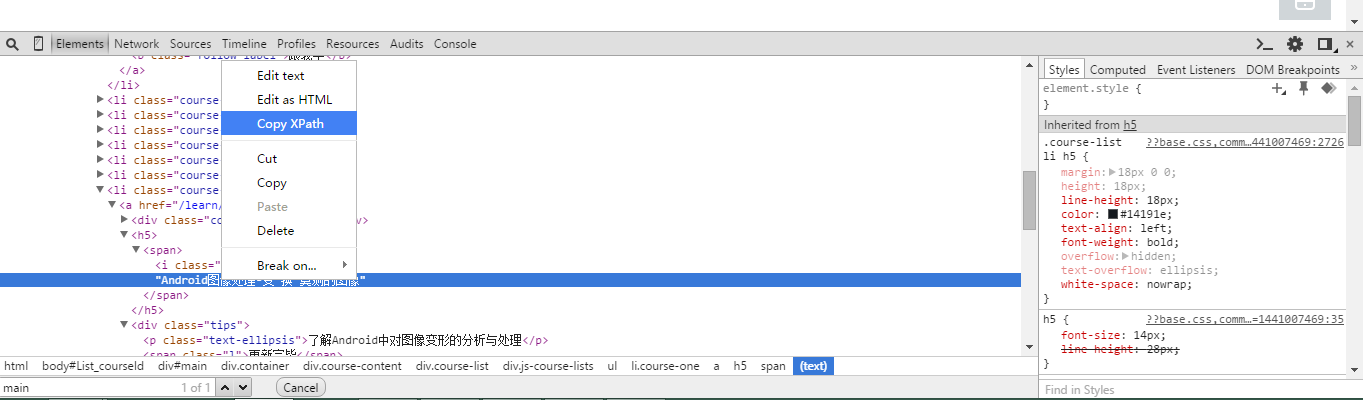
这样我们就非常方便的获得了元素的XPath,同时,我们也可以根据规则来手动修改。
使用XPath基本是如下三个步骤:
- from lxml import etree
- Selector = etree.HTML(HTML Source)
- Selector.xpath(XPath)
我们同样以前面的网址为例,我们抓取所选的那门课程的标题:
# coding=utf-8
import requests
from lxml import etree
html = requests.get("http://www.imooc.com/course/list?c=android&page=2")
html.encoding = 'utf-8'
selector = etree.HTML(html.text)
content = selector.xpath('//*[@id="main"]/div/div/div[3]/div[1]/ul/li[1]/a/h5/span/text()')
for each in content:
print each
这样我们就获取了对应的内容, 搜索方法,其实跟我们通过地址来定位是一样的,中国-上海-浦东新区(内容唯一时,前面可跳过)-张江高科-沪江网-徐宜生
那么如果我们需要爬取所有的课程信息要怎么办呢?我们可以看见生成的XPath中,有一个li[1],它对应的是我们源代码中的那个列表,我们选择1是因为选择具体的一项,如果我们去掉这个1,返回的就是一个列表,就是我们要的所有元素,这里就不详细演示了。
XPath高级使用技巧
相同字符串开头、但属性不同
<div id="test-1">需要的内容1</div>
<div id="test-2">需要的内容2</div>
<div id="test-3">需要的内容3</div>
我们需要提前所有内容,但是他们的属性都不同,我们先看下一个元素的XPath:
//*[@id="test-1"]/text()可见,ID决定了元素,所以要取出这样的元素时,我们需要使用XPath的starts-with(@属性名称, 属性字符相同部分)方法:
//*[starts-with(@id,"test")]/text()只需要将[]中的内容使用starts-with方法进行匹配就OK了。
<div id=“class”>text1
<font color=red>text2</font>
text3
</div>
类似这种嵌套标签的,如果我们使用XPath获取第一级的text,那么只能获取text1和text3,如果要获取text2,我们就需要使用string(.)方法。
data = selector.xpath('//div[@id="class"]')[0]
info = data.xpath('string(.)')
content = info.replace('\n','').replace(' ','')
print content通过string(.),我们可以获取嵌套标签的text,相当于遍历子标签,获取text。
写本篇博客的目的在于后面要进行的一次抽奖活动,大家都知道,我的新书《Android群英传》已经正式上市了,为了报答各位的大力推荐,我准备在CSDN博客准备一次抽奖,这篇博客所讲的,自然是抽奖所需要的预备知识,欢迎大家预热~~~
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK