

Lucene系列(17)工具类之bkd树的源码实现
source link: http://huyan.couplecoders.tech/%E6%90%9C%E7%B4%A2/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/bkd%E6%A0%91/2021/04/01/lucene%E7%B3%BB%E5%88%97(17)%E5%B7%A5%E5%85%B7%E7%B1%BB%E4%B9%8Bbkd%E6%A0%91%E7%9A%84%E6%BA%90%E7%A0%81%E5%AE%9E%E7%8E%B0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
源码分析文章比较难以组织,推荐大家直接看大量注释的源码: 传送门
上一篇文章讲了bkd树的基本原理,这次看一下Lucene对BKD树的实现.
bkd树在lucene中的实现,都在org.apache.lucene.util.bkd中,其中又包含了下面几个类.
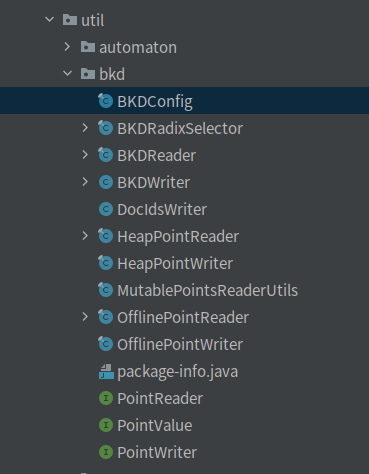
为了看懂这块代码,让我们先来介绍下三个接口.
org.apache.lucene.util.bkd.PointValue
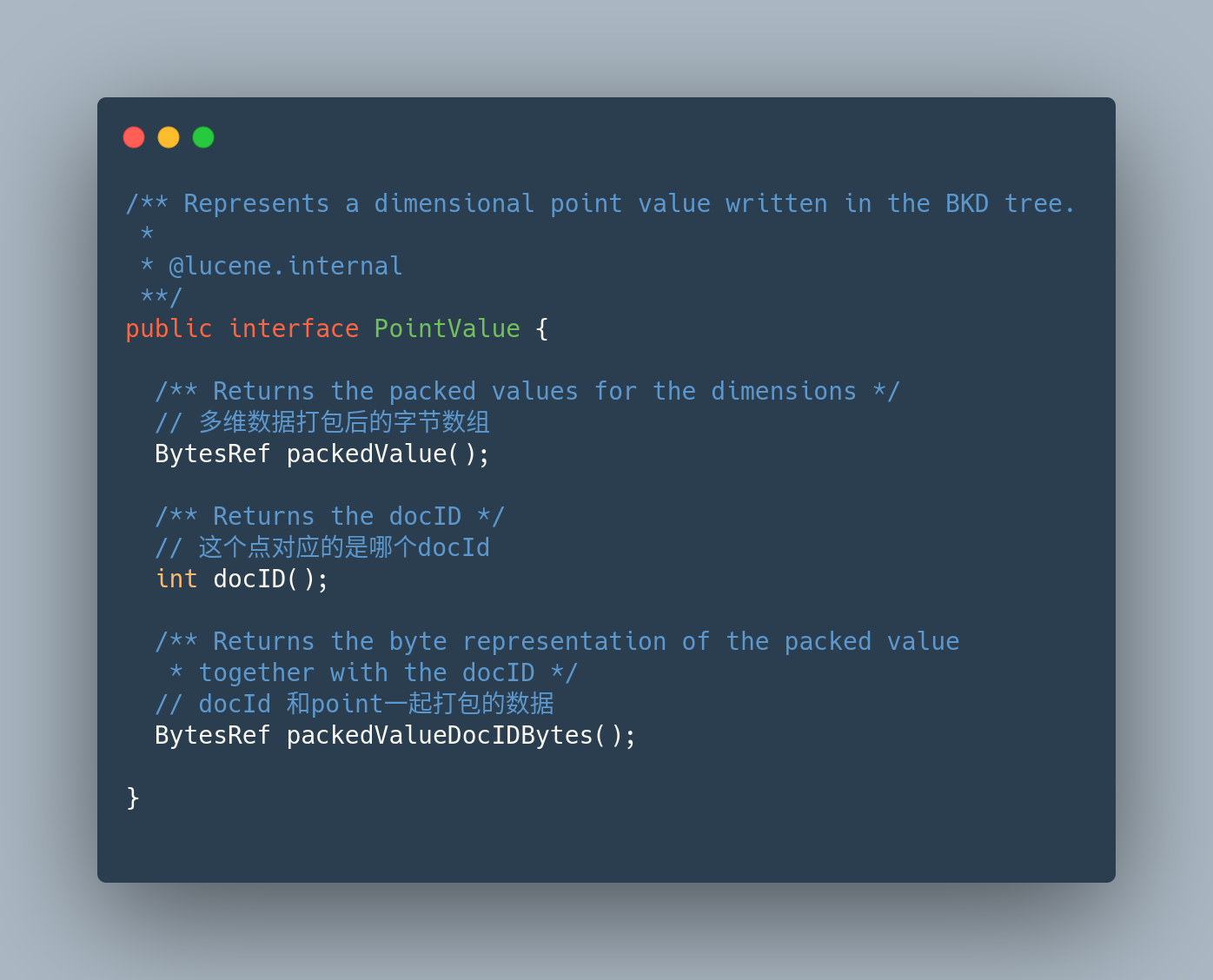
这个接口,用来描述一个多维的点. 并且提供了数据的获取方式:
- 点的数据的字节数组
- 这个点对应的docId
- 这个点和docId打包在一起的数据
org.apache.lucene.util.bkd.PointWriter
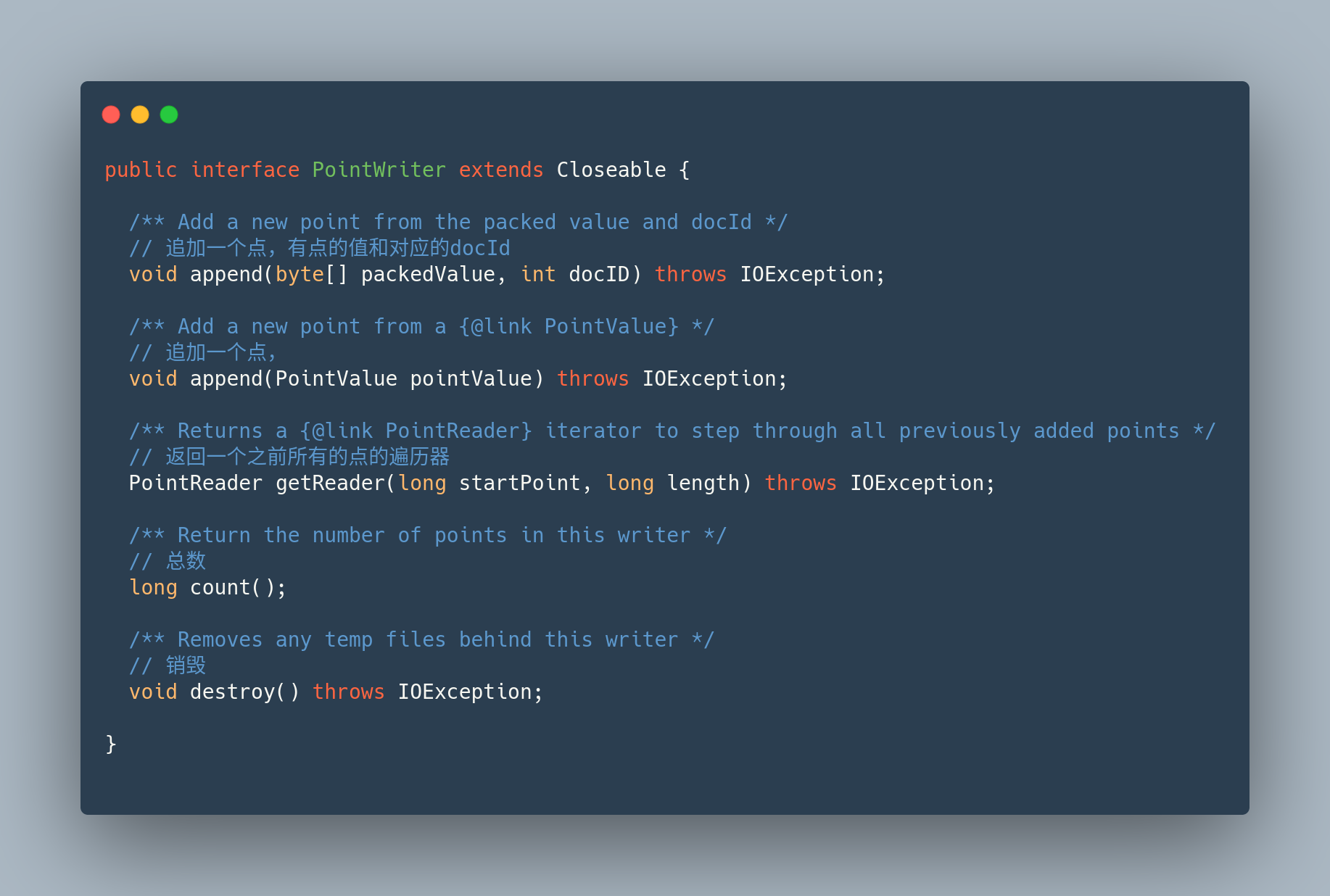
这个接口,是点的写入的抽象接口,可以通过他的实现类,向(内存/磁盘)等存储介质写入多个点.
- append: 追加一个点,存储点的值和对应的docId
- count: 写入的point的总数
- getReader: 提供一个读取之前的所有的point的遍历器.
org.apache.lucene.util.bkd.PointReader
public interface PointReader extends Closeable {
/** Returns false once iteration is done, else true. */
// 是否还有下一个值呢???
boolean next() throws IOException;
/** Sets the packed value in the provided ByteRef */
// 把打包好的值,放进到给定的容器里, 反正就是迭代器呗,能知道下一个还有没有,拿到当前的值
PointValue pointValue();
}
这个接口,提供了点的读取抽象接口,他的实现类可以从(内存/磁盘)上读取一系列的点.
- next: 是否还有下一个
- pointValue: 读取下一个点的数据
bkd树写入
BKD树的写入过程,是在BKDWriter中实现的. 为了文章的简洁,这里就不一一介绍成员变量,构造方法等等给了。直接按照写入流程开始学习。
首先,我们都知道使用BKD树的目的是什么,那就是对给定的数据,首先构建一棵树,来支持快速的查询,之后再说支持树的更新的事情。
既然是添加数据,构建一棵树,那么就从add方法开始看起把。
add方法
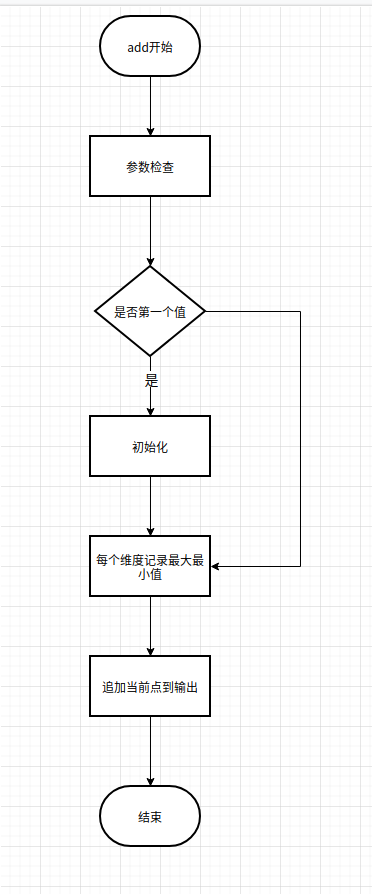
public void add(byte[] packedValue, int docID) throws IOException {
// 数据check
if (packedValue.length != config.packedBytesLength) {
throw new IllegalArgumentException("packedValue should be length=" + config.packedBytesLength + " (got: " + packedValue.length + ")");
}
if (pointCount >= totalPointCount) {
throw new IllegalStateException("totalPointCount=" + totalPointCount + " was passed when we were created, but we just hit " + (pointCount + 1) + " values");
}
// 初始化
if (pointCount == 0) {
initPointWriter();
System.arraycopy(packedValue, 0, minPackedValue, 0, config.packedIndexBytesLength);
System.arraycopy(packedValue, 0, maxPackedValue, 0, config.packedIndexBytesLength);
} else {
// 每个维度进行写入
for (int dim = 0; dim < config.numIndexDims; dim++) {
int offset = dim * config.bytesPerDim;
// 进行最大最小值的写入
if (FutureArrays.compareUnsigned(packedValue, offset, offset + config.bytesPerDim, minPackedValue, offset, offset + config.bytesPerDim) < 0) {
System.arraycopy(packedValue, offset, minPackedValue, offset, config.bytesPerDim);
} else if (FutureArrays.compareUnsigned(packedValue, offset, offset + config.bytesPerDim, maxPackedValue, offset, offset + config.bytesPerDim) > 0) {
System.arraycopy(packedValue, offset, maxPackedValue, offset, config.bytesPerDim);
}
}
}
// 追加当前点
pointWriter.append(packedValue, docID);
pointCount++;
// 记录docId
docsSeen.set(docID);
}
可以看出来,add方法其实比较简单,甚至可以单纯的理解为只是对PointWriter进行了append操作而已。
这里的PointWriter,也就是之前介绍的点的写入接口,有两种实现方式,基于内存的和基于磁盘的. 当要写入的point数量大于内存中允许的最大点数量时,采用磁盘写入,否则采用内存写入.
内存中允许的最大点数量
这里采用了内存大小的限制方式,给定最大的16M内存,之后除以每个点的大小,就可以得到内存中最大存储的点的数量了.
finish方法
在不断的添加之后, 终于完成了所有的add,此时就需要进行finish来进行实际的写入了. (add方法只是缓冲,没有实际的构造树)
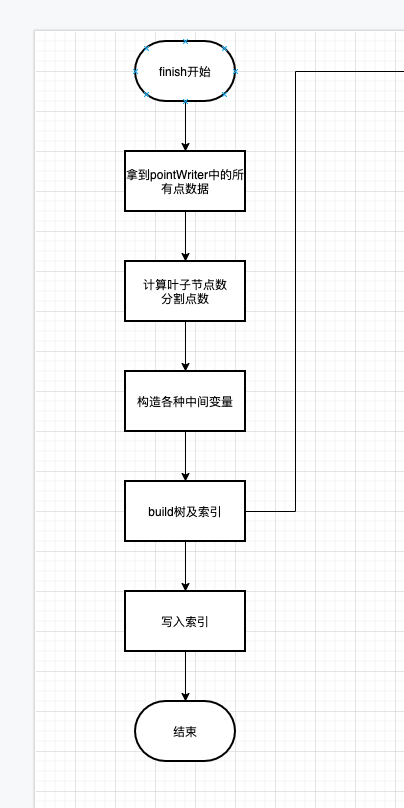
代码比较长,就不贴了.
核心是做了两件事,对应两个方法
- 构建整颗BKD树,对应了
build方法. - 将这颗BKD树的索引写入到文件中.对应
writeIndex方法.
build方法
既然涉及到树,那么想必大家都是知道,构建的过程肯定是个递归的方法了. 流程如下:
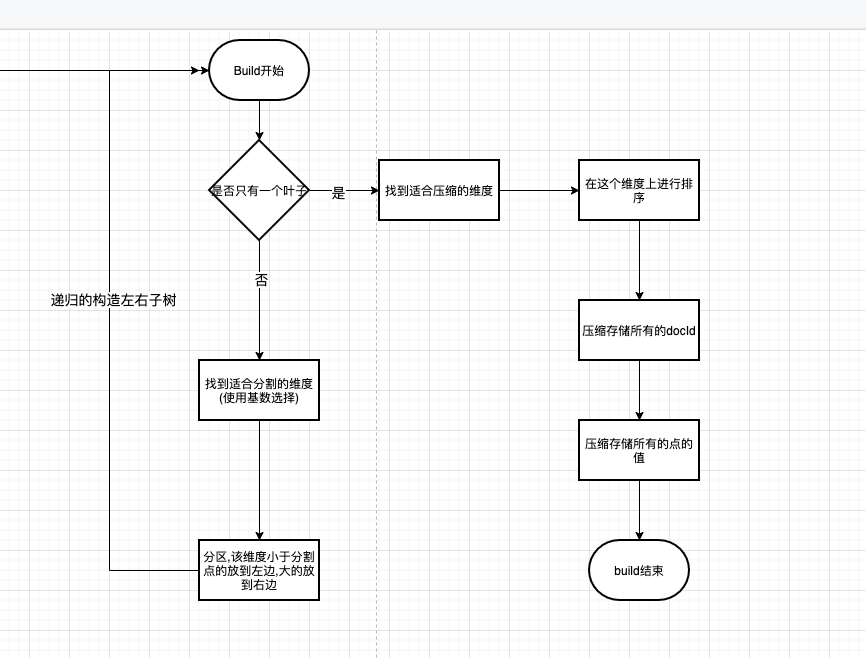
核心的路径为:
- 如果只有一个叶子节点,就将
点的值/docId写入到磁盘. - 挑选分割的维度,进行均匀一些
- 根据该维度,对所有的点进行分区,大的小的各自一边
- 对左右递归的进行这个操作.
writeIndex方法
这个方法其实和bkd树实现无关,它将这棵树的一些元数据, 文件偏移位置等索引内容, 写入到了meta文件和index文件两个文件中.
这部分内容会在kdd/kdi/kdm等文件格式中详细介绍.
在bkd代码中,称上面的先add,然后finish的方法为慢的方法,它主要用来合并已有的分片.
代码中还提供了当我们从IndexWriter的缓冲区,直接创建一个新的分片时,应该使用的方法,即org.apache.lucene.util.bkd.BKDWriter#writeField. 它和上面的方法的区别是, 由于是完全新的切片, 我们可以在写入磁盘之前进行重排序,因此会比上面的性能好一些.
由于基本上是性能差异, 而这片文章主要想讲lucene如何实现一个BKD树,暂时就不深究性能了.
简单总结一下对一堆多维数据点,构建BKD树的过程.
- 一个叶子节点包含n个数据点,如果数量小于n,就放到一个叶子上,进行存储,写入文件(写入实际的值及docId),同时记录文件的偏移位置.
- 对多个叶子, 首先挑选一个用来进行这次分割的维度.
- 在这个维度上,对所有的叶子进行切割. 小的去左子树,大的去右子树.
- 对左右子树进行递归构建.
- 构建完成,将元数据及文件偏移位置(索引)写入文件.
说实话, 对于BKD树的实现,我目前没有做到100%完全了然于心, 但是经过一番努力,仍旧差点意思,因此只能放到之后了.
希望随着看的越来越多,对于BKD的理解能够更加透彻,回头来润色这篇文章.
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:[email protected]
更多学习笔记见个人博客或关注微信公众号 <呼延十 >——>呼延十
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK