
6

Python爬虫-爬取wallhaven壁纸
source link: https://blog.csdn.net/m0_51936098/article/details/114991389
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
刚学习python一个多月的小白,做个爬虫项目操练一下,如有不足,敬请雅正。
可行性分析
wallhaven上面有许多精美的壁纸,一张一张下载有时过于繁琐,本文便向读者展示如何自动化爬取wallhaven上基于关键词(英文)和排行榜的壁纸。
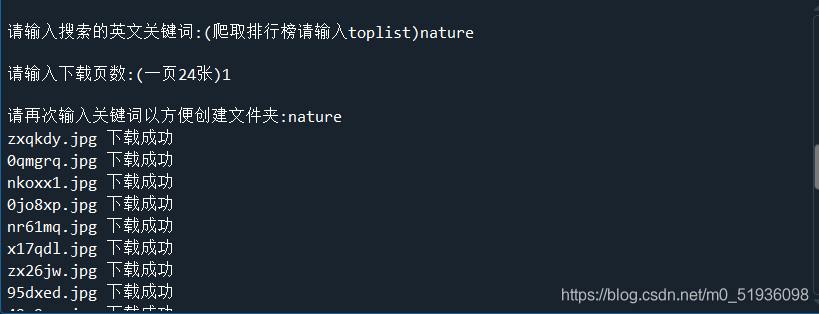
- 输入英文关键词(输入toplist则为爬取排行榜)。
- 输入爬取的壁纸页数(1页24张)。
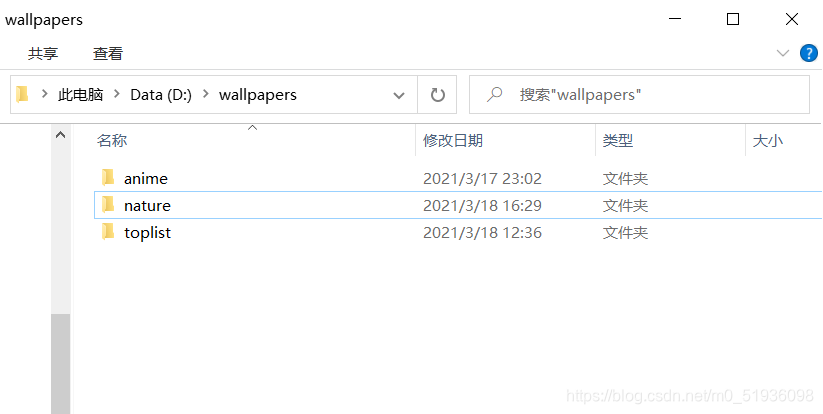
- 输入第一步输入的关键词,程序会在D盘目录下创建一个名为wallpapers的文件夹,然后在wallpapers文件夹中创建以关键词命名的子文件夹。
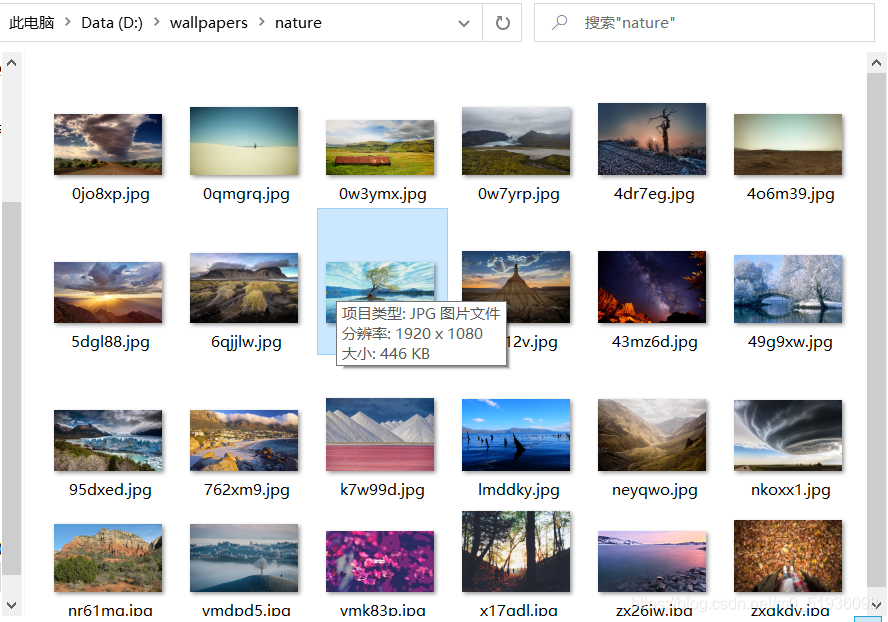
- 耐心等待程序下载壁纸并保存在第三步创建的子文件夹中。
- 输入英文关键词
⟶
\longrightarrow
⟶输入下载页数
⟶
\longrightarrow
⟶再次输入关键词
- 创建文件夹
- 爬取壁纸并存放
1.获取每页(1页24张)壁纸的url
wallhaven是基于ajax协议动态刷新每页的壁纸。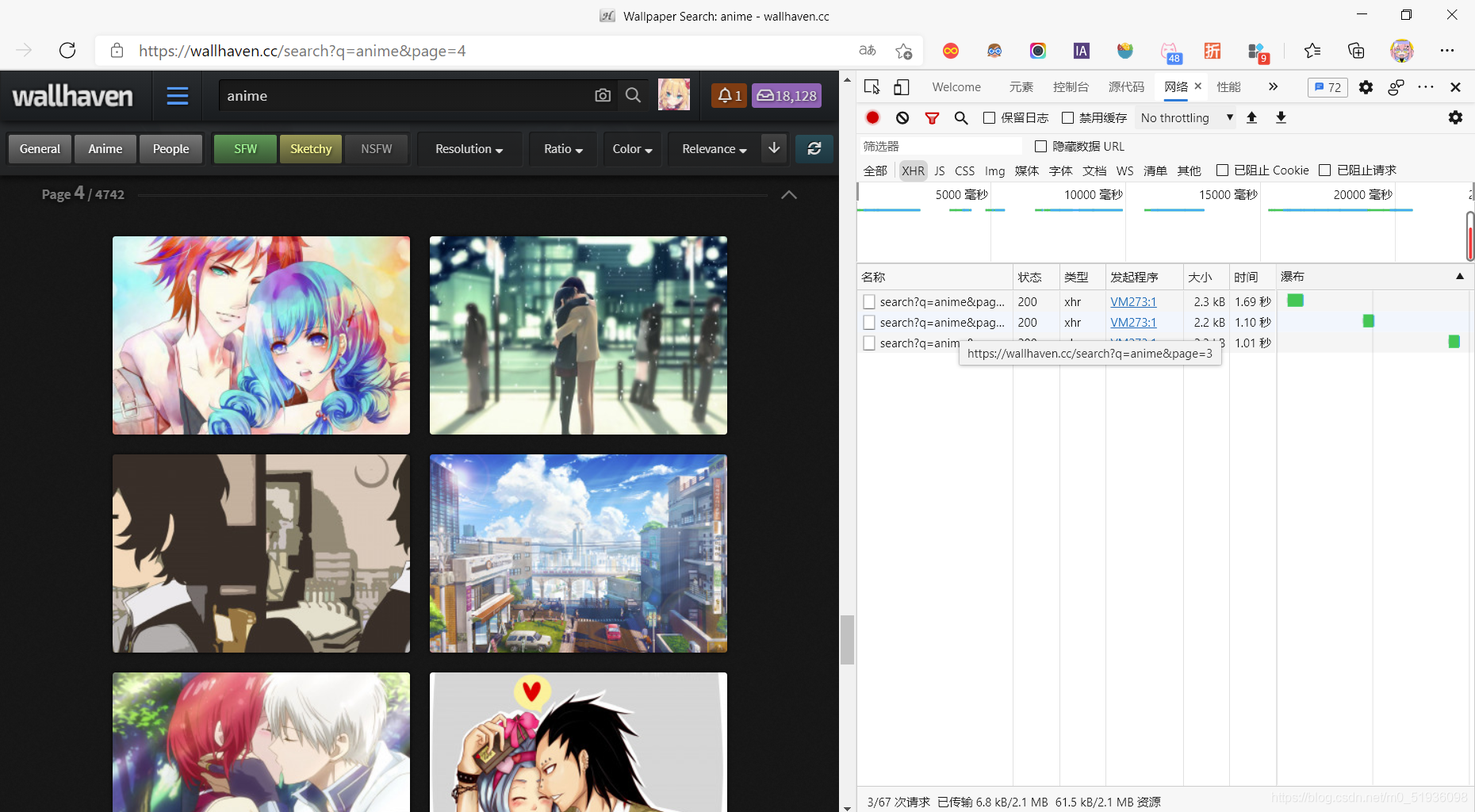
通过观察,分别得出基于关键词和排行榜的url模板:
2.获取每张壁纸缩略图的url
F12打开整页壁纸的网页源代码,并检查图片元素,发现每张壁纸缩略图的url都在**class=“preview”**这个标签里,于是利用正则表达式爬取每张壁纸缩略图的url。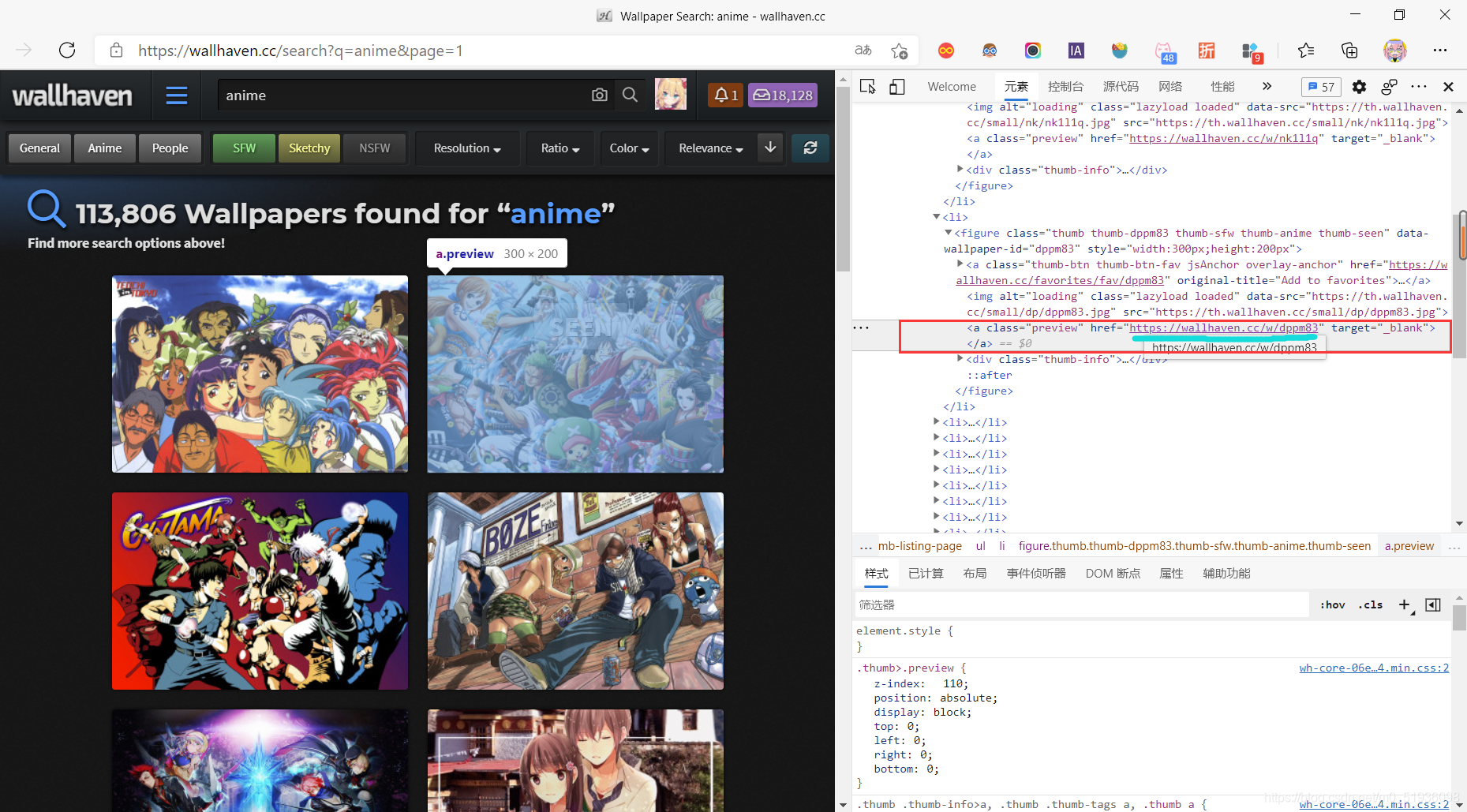
3.获取壁纸原图下载的url
打开壁纸缩略图的url,发现并不能直接下载原图,右键壁纸缩略图打开新标签页得到壁纸原图下载的url,然后通过观察得出每张壁纸原图下载的url与壁纸缩略图url的关联关系。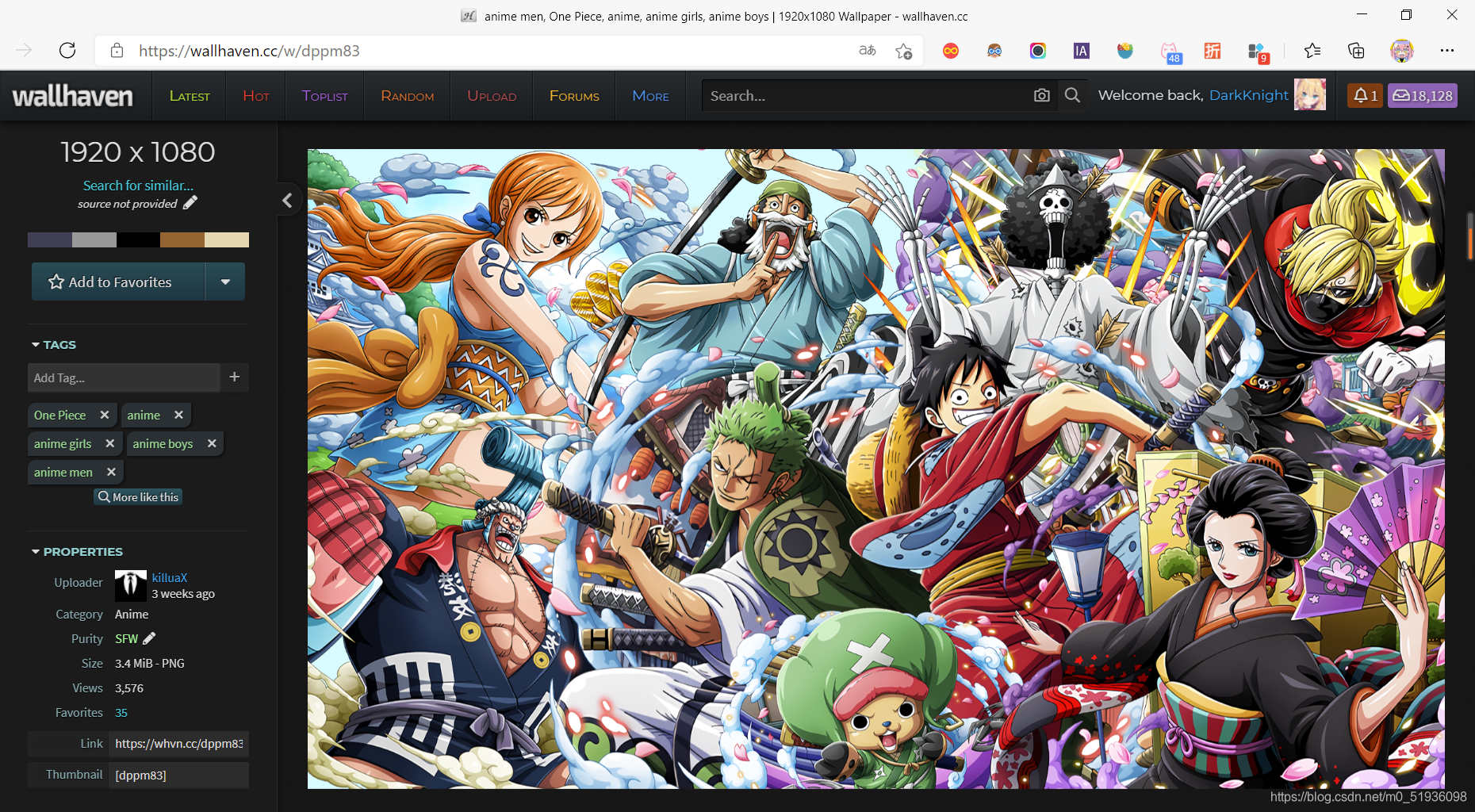

4.下载壁纸并保存在文件夹中
通过壁纸原图下载的url下载壁纸并保存在程序在D盘创建的wallpapers文件夹下以关键词命名的子文件夹。
1.导入第三方库
import requests #爬虫
import re #正则表达式
import os #文件操作
2.获取每页壁纸的url模板
def get_url(base_url):
keyword=input("请输入英文关键词:(爬取排行榜请输入toplist)")
if keyword=='toplist': #获取排行榜的url模板
base_url=base_url+keyword+'?page='
else: #获取基于关键词的url模板
base_url=base_url+'search?q='+keyword+'&page='
return base_url #返回模板
3.获取每页每张壁纸缩略图的url并存放在一个列表中
def get_img_url(base_url):
header={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74'
} #模拟浏览器头部,伪装成用户
img_url_list=[] #创建一个空列表
page_num=input("请输入下载页数:(一页24张)")
for num in range(1,int(page_num)+1): #循环遍历每页
new_url=base_url+str(num) #将模板进行拼接得到每页壁纸完整的url(实质:字符串的拼接)
page_text=requests.get(url=new_url,headers=header).text #获取url源代码
ex='<a class="preview" href="(.*?)"'
img_url_list+=re.findall(ex,page_text,re.S) #利用正则表达式从源代码中截取每张壁纸缩略图的url并全部存放在一个列表中
return img_url_list #返回列表
4.将列表中的壁纸缩略图的url进行字符串的增删获得壁纸原图下载的url,下载后存放在文件夹中
def download_img(img_url_list):
header={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74'
} #模拟浏览器头部,伪装成用户
keyword=input("请再次输入关键词以方便创建文件夹:")
if not os.path.exists('D:/wallpapers'): #在D盘目录下创建一个名为wallpapers的文件夹
os.mkdir('D:/wallpapers')
path='D:/wallpapers/'+keyword
if not os.path.exists(path): #在wallpapers文件夹下创建一个以关键词命名的子文件夹以存放此次下载的所有壁纸
os.mkdir(path)
for i in range(len(img_url_list)): #循环遍历列表,对每张壁纸缩略图的url进行字符串的增删获得壁纸原图下载的url 注:jpg或png结尾
x=img_url_list[i].split('/')[-1] #获取最后一个斜杠后面的字符串
a=x[0]+x[1] #获取字符串的前两位
img_url='https://w.wallhaven.cc/full/'+a+'/wallhaven-'+x+'.jpg' #拼接字符串,先默认jpg结尾
code=requests.get(url=img_url,headers=header).status_code
if code==404: #若网页返回值为404,则为png结尾
img_url='https://w.wallhaven.cc/full/'+a+'/wallhaven-'+x+'.png'
img_data=requests.get(url=img_url,headers=header,timeout=20).content #获取壁纸图片的二进制数据,加入timeout限制请求时间
img_name=img_url.split('-')[-1] #生成图片名字
img_path=path+'/'+img_name #生成图片存储路径
with open(img_path,'wb') as fp: #('w':写入,'b':二进制格式)
fp.write(img_data)
print(img_name,'下载成功') #每张图片下载成功后提示
5.编写主函数并调用
def main(url):
base_url=get_url(url)
img_url_list=get_img_url(base_url)
download_img(img_url_list)
main('https://wallhaven.cc/')
#爬取壁纸时可能会有些慢(受网速影响),需要耐心等待!耐心等待!耐心等待!
喜欢的小伙伴记得点个赞支持一下噢!欢迎大家与我交流!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK