

Building a data lake: from batch to real-time using Kafka
source link: https://engineering.thetrainline.com/building-a-data-lake-from-batch-to-real-time-using-kafka-67272041b124
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Building a data lake: from batch to real-time using Kafka
We know having a single place to store and query all available data (a data lake) is a critical requirement in the modern world but approaches to building and maintaining one are different. From the start, at Trainline we had a batch approach to building DL (with daily updates). It had its own issues and benefits but no matter how good and polished it became, the modern requirement from most customers remained to get data as fast as possible — and that’s not easy in batch world.
This is how data flow looks at Trainline, as well as how we have replaced most of batch processing with Kafka.
How does the data flow look?
As a data engineering team at Trainline, we are responsible for receiving and storing data, processing it, sending it to other teams and maintaining a data lake which is accessible by various consumers including BI and Data Science.
AWS architecture in Trainline consists of multiple AWS accounts, for example, production, staging, testing, as well as a specific data account which is dedicated to maintaining the data lake. All data is stored in one account, so it’s easier to maintain access policies and permissions.
Part 1. Vortex
The first service in the data pipeline is an HTTP API (called Vortex) to receive events from other teams. It has two responsibilities:
- Validate a JSON event that is pushed according to JSON schema
- If event is valid to JSON schema, write it to output Kinesis Stream
Vortex uses a separate service called Schema Registry where JSON schemas are stored. For example, if anyone wants to send an event with schema MyEvent and version 1.0.0, it should exist in Schema Registry. To update Schema Registry, we have a git repository to store all schemas and a PR to that repo allows other teams to register their schemas.
The next step is pushing data to the data account. We are using AWS Kinesis streams to do that as it’s easy to set up cross-account permission to read streams from another AWS account.
Part 2. Hermes
The next service in the pipeline is a routing service (called Hermes), it reads Kinesis stream(s) and pushes data to multiple configurable destinations:
- SQS: we can configure to push some events to specific SQS queues so consumer teams can receive data in real time.
- S3: all events are written as raw events (compressed JSON files) in an S3 “acquired” bucket, so we always have an option to backfill or reprocess data that we’ve received at some point.
- Kafka
Part 2.1. Batch Processing
In batch world, the main responsibility of Hermes was to write data to an acquired S3 bucket: this data was picked by daily Airflow runs, transformed and written to a data lake S3 bucket. Now the most exciting path of data is to Kafka, which makes all data available in real-time inside a Kafka cluster (so new data products can be created), as well as pushing data to Data Lake — so both are using the same data source.
Part 3. Kafka
As a small team, to reduce DevOps work, we decided to use AWS-managed Kafka MSK.
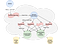
Part 3.1. Whirlwind
Hermes writes all events to an “acquired” Kafka topic. The Kafka stream application that reads this topic is called Whirlwind. It reads all incoming events and applies transformations. The Schema Registry service which stores Vortex JSON schemas, also stores files (called blueprints) which describe transformation done in Whirlwind, as well as mappings between JSON schema and a blueprint.
Usage of these transformations are usually in one of these groups:
- A simple mapping between an incoming JSON event to output a flat structure
- A more complex transformation with custom aggregations to reduce computation cost in downstream jobs, or to reduce output storage size
Part 3.2 Conduit
The output of Whirlwind is a bunch of Kafka topics named, for example, ‘ingested.private.TableName’, and Conduit is a Kafka consumer that reads all these topics by a pattern.
The logic of the app is to read events from all topics, batch them in files locally until the file is more than a configured size in megabytes or is sitting on disk longer than N minutes. When it’s time to load a file, it’s converted from Avro to Parquet format, pushed to S3 location and the last processed offset in that Kafka topic partition is committed. As we have consistent file naming and Kafka offset is committed only after upload is done, we basically have exactly one delivery guarantee: if there is an error, the consumer starts from a previously committed offset so we don’t lose data, but if some files were already written to S3, they will just be overwritten so we don’t have duplicates.
Part 3.3 Conduit Batch
In main Data Lake we have partitions by event_time (which is a part of a JSON event that we receive, and it essentially means the business time of the event) but as we don’t control it, new data could be written to any part of the database in terms of time (for example, someone decides to push historic data to Vortex). So, the issue here is that some consumers of data are interested only in fresh data, so they want to interact with Data Lake in an incremental way (and there is no efficient way to do it in the main Data Lake). The solution we have is a separate version of Data Lake (it stores data for a short period of time (30 days) and is cleaned up by S3 retention policy) where we partition by ingested time instead of event_time. We use Kafka record timestamp, so based on Kafka guarantees of topics with LogAppendTime type, we can say that if data is written to hour X, from Kafka topic partition P, all data in hour X-1 is already in the Data Lake.
Part 4. Athena
The last step in building a data lake is to make that data available in AWS Athena. We’re currently using scheduled Glue crawlers to discover Glue tables and update partitions as it was the easiest way to start with. We are also moving to a manually-maintained Glue catalog, as calling crawlers just to register new partitions is overkill.
Athena database, backed by S3 storage, is the final destination of data (from the data engineers point of view) and it’s used by BI and data science in various reports, jobs and services but also, as all data goes through Kafka cluster and each event has its own topic, it opens up the possibility to write real-time Kafka applications based on that data.
To summarise the benefits of the current pipeline:
- All data is available in Kafka so we can write new real-time applications on top of that. As all data goes through a Kafka cluster (available for data products in real-time) and is written to the data lake, we are sure that it is consistent between real-time products and the data lake.
- It is easy to scale horizontally in Kafka, to handle more events
- As we have S3 to store all acquired events, we can run backfills (in batch fashion), but we can reuse the same code from the Kafka stream application to transform those events.
To learn how Trainline uses its data platform to power real-time data products for its customers, take a look at Jan’s blog here.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK