

Decoding the Covid-19 tweets using NLP and Graph Database
source link: https://towardsdatascience.com/decoding-the-covid-19-tweets-using-nlp-and-graph-database-35e1b406f439
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Decoding the Covid-19 tweets using NLP and Graph Database
Building the Twitter graph to find insights into covid tweets

COVID-19 Vaccination is a new hot topic in social media (Twitter) so why don’t we leverage the Natural Language Processing (NLP) and Graph Database (Neo4j) to find insights into the covid 19 vaccine-related information.
Neo4j Graph database provides excellent tools, libraries to work on connected data and many scientific projects are based on these advanced tools. This article is mainly focused on how to use NLP in Neo4j for text data analysis. Neo4j -NLP helps us to do basic sentiment analysis to understand where people’s opinions are regarding vaccination.
So let's start building from scratch.

Analysis Flow :
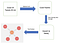
Data source: I have taken the Twitter data set ( corona_tweets_268.csv: 3,190,245 tweets (December 11, 2020, 08:00 AM — December 12, 2020 10:10 AM) related to corona from IEEE Dataport.
Twitter doesn’t allow to store/process entire user posts so once you gather Tweets ID, you have to use tools like Hydrator to extract post information from Tweets ID.
Once you get the Twitter post information in JSONL file, you can then convert to JSON format, export the file to any programming language to do data cleaning, data massage, and then import the file to neo4j. This is one of the tedious tasks.
Note: for sake of simplicity, you can download the twitter.json which contains 5000 tweets from the below GitHub link mentioned in the reference.
Core Tools and Libraries:
We are going to use the Neo4j database where we will store tweets and do further analysis.
Plugins to be installed in neo4j:
APOC pluggin
Graph data science pluggin
Graphaware: Graphaware has lots of libraries that offer NLP capability to Neo4j so we will use these libraries
List of libraries provided by graph aware:
neo4j-framework
neo4j-nlp
neo4j-nlp-stanfordnlpstanford-english-corenlp ( Language Model) This is language model file, need to be downloaded separately
Set up is one of the most difficult parts due to many dependent libraries and versions.
Follow the Installation step strictly in order as mentioned in guidelines to set up Graphaware libraries in neo4j.
Due to a lack of proper documentation, you may be lost in finding the right libraries and version. So here is one document I prepared to help you out in finding libraries and their appropriate versions.
I am using the Bloom tool for visualization which is optional.
At the end of set up your neo4j.conf file should look like this :
# nlp settings
apoc.import.file.enabled=true
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
com.graphaware.runtime.enabled=true
com.graphaware.module.NLP.2=com.graphaware.nlp.module.NLPBootstrapper
dbms.security.procedures.whitelist=ga.nlp.*,gds.*,apoc.*
Text Analysis :
We are going to follow the below step for text analysis:
1: Bulk upload of tweets using APOC.JSON and then create the Tweets node
2: Create the User Node from tweets using regex
3 :Create the HashTag Node from tweets using regex
4: Annotate Tweets using nlp pipeline
5: Query to analyse tweets using sentiment analysis, Named Entitiy Recognition etc.

Step 1: Bulk upload and Twitter Node creation:
// Use Apoc.load json to do bulk uploadCALL apoc.load.json("file:///twitter.json")
YIELD value as t
CREATE (tweet:Tweet {
user_id: t.user_id,
user_name: t.user_name,
user_screen_name: t.user_screen_name,
tweets: t.tweet,
twitter_id: t.twitter_id,
post_created_at: t.post_created_at,
user_description: t.user_description
})
RETURN count(t);
Step 2: Create the Hash Tag Nodes from tweets using regex
// extracting hash
MATCH (t:Tweet)
WHERE t.tweets =~ ".*#.*" //finding pattern #
WITH
t,
apoc.text.regexGroups(t.tweets, "(#\\w+)")[0] as hashtags //regex to extract text contain # character
UNWIND hashtags as hashtag
MERGE (h:Hashtag { name: toUpper(hashtag) }) //create hashtag node
MERGE (h)<-[:hashtag { used: hashtag }]-(t)
RETURN count(h)
Step 3: Create the User Node mentioned in tweets using regex
MATCH (t:Tweet)
WHERE t.tweets =~ ".*@.*" //finding pattern @
WITH
t,
apoc.text.regexGroups(t.tweets, "(@\\w+)")[0] as mentions //regex to extract text contain @ character
UNWIND mentions as mention
MERGE (u:User { name: mention }) //create User node
MERGE (u)<-[:mention]-(t)
RETURN count(u);

Step 4: From here core NLP work starts, so first we will build a pipeline that will annotate text, do Name Entity Recognition and sentiment analysis in a single query.
//pipeline CALL ga.nlp.processor.addPipeline({textProcessor: 'com.graphaware.nlp.processor.stanford.StanfordTextProcessor', name: 'customStopWords', processingSteps: {tokenize: true, ner: true, dependency: false,sentiment:true}, stopWords: '+,result, all, during',
threadNumber: 20})It will create a default pipeline named customStopWords having com.graphaware.nlp.processor.stanford.StanfordTextProcessor as text processor. It has set tokenize, ner, and sentiment features as true.
CALL ga.nlp.processor.getPipelines() // To query about your pipeline

Do not annotate text without iteration. if the text data set is large, you will end up in a deadlock. So use apoc.periodic.iterate to annotate text one by one.
CALL apoc.periodic.iterate(
"MATCH (t:Tweet) return t",
"CALL ga.nlp.annotate({text: t.tweets, id: id(t)})
YIELD result MERGE (t)-[:HAS_ANNOTATED_TEXT]->(result)", {batchSize:1, iterateList:true})
Note: There is the issue of memory consumption, deadlock so read about how to increase the neo4j memory heap size, indexing.


Named Entity Recognition :
MATCH (n:NER_Person) RETURN n LIMIT 25

MATCH (n:NER_Organization) RETURN n LIMIT 25

Now the fun part is querying the data for insights.
You have seen Pfizer is one Pharma company quite mentioned in tweets about its vaccine development. Let’s see what is the sentiment (positive, negative) of posts regarding this entity.
MATCH (:NE_Organization{value: 'Pfizer'})-[]-(s:Sentence:Negative)-[]-(:AnnotatedText)-[]-(tweet:Tweet)
RETURN distinct tweet.tweets;
How about people's opinions about vaccination?
People’s tweets supporting vaccination:
MATCH (n:NER_O)-[]-(s:Sentence:Positive)-[]-(:AnnotatedText)-[]-(tweet:Tweet)
where n.value starts with 'vacc'
RETURN distinct tweet.tweets;

People’s tweets against the vaccination :
MATCH (n:NER_O)-[]-(s:Sentence:Negative)-[]-(:AnnotatedText)-[]-(tweet:Tweet)
where n.value starts with 'vacc'
RETURN distinct tweet.tweets;

Wow, I am having fun exploring the power of the graph to analyse text data. Let’s see more
The organization mentioned for wrong (negative) reasons:
MATCH (n:NER_Organization)-[]-(s:Sentence)-[]-(:AnnotatedText)-[]-(tweet:Tweet)
RETURN distinct n.value,tweet.tweets;

People mentioned for positive sentiment :
MATCH (n:NER_Person)-[]-(s:Sentence:Positive)-[]-(:AnnotatedText)-[]-(tweet:Tweet)
RETURN distinct n.value as name, tweet.tweets as tweets

People, organization talking about the vaccine:

And the list goes on, you can do too many things. It's really fascinating to uncover information using connected data and this is one of many simple use cases to do so.
This is the typical flow for any kind of text analysis, either News articles, feedback, review system, and doing through the graph is really fun.
Drop your feedback, messages in case if you stuck in some setup or configuration.
Cheers!!
Reference :
2: Neo4j: Natural Language Processing (NLP) in Cypher article by David Allen, most of the inspiration got from this article
3: Neo4j NLP
4: Neo4j
5: Graphaware
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK