

用 pyppeteer 制作 PDF文件
source link: https://foofish.net/python-pyppeteer-pdf.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
之前介绍过一些将html转换为PDF文件的库,比如 wkhtmltopdf、WeasyPrint,今天再介绍另一个神器Pyppeteer可将html页面转换为PDF。
Pyppeteer 是什么
介绍 Pyppeteer 之前,有必要先介绍一下 Puppeteer,Puppeteer 是谷歌官方出的一个通过DevTools协议控制headless Chrome的Node库。通过Puppeteer可以直接控制Chrome浏览器模拟大部分用户操作。
所谓Headless Chrome 就是 Chrome 浏览器的无界面形态。
而 Pyppeteer 就是 Puppeteer 的 Python 版本非官方实现,它是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本
Pyppeteer 采用了 Python 的 async 机制,需要Python3.5 及以上版本才支持。
Pyppeteer能做什么
但凡是需要通过Chrome浏览器手动完成的操作都可以通过 Pyppeteer 自动完成,例如:
- 生成页面截图
- 生成PDF文件
- 抓取单页面应用并生成预先呈现的内容
- 从网站抓取你需要的内容
- 自动表单提交,UI测试,键盘输入等
例如将页面生成截图可以直接调用 page.screenshot 方法
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://foofish.net')
await page.screenshot({'path': 'example.png'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
截图功能在海报分享等场景用的多,有看过有赞工程师分享的一篇文章,就有用到Puppeteer来做海报分享,性能比Canvas高。
而将网页转换为PDF的应用场景更多,比如将网站博客、专栏,或者公众号文章批量导出PDF,方便离线阅读,比如我们最近做的一个医疗项目需要将用户填写的资料支持PDF形式批量导出,就是用的Pyppeteer
导出PDF
导出pdf直接调用page.pdf方法就可以, 代码非常简洁
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://foofish.net')
await page.pdf({
"path": "example.pdf", "format": 'A4'})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
接下来我们以公众号文章为例,将html页面制作成一个PDF文件。
公众号链接导出PDF示例
安装 pyppeteer
pip install pyppeteer
任意找一篇公众号的文章链接
url = "https://mp.weixin.qq.com/s/6VBXs19icV0O5hT7cHYwgw"
完成代码:
browser = await launch(
options={'headless': True,
'args': ['--no-sandbox',
'–disable-gpu',
'–disable-dev-shm-usage',
'–disable-setuid-sandbox',
'–no-first-run',
'–no-zygote',
'–single-process'
]}, )
page = await browser.newPage()
url = "https://mp.weixin.qq.com/s/6VBXs19icV0O5hT7cHYwgw"
await page.goto(url)
file_name = "test.pdf"
await page.pdf({"path": file_name, "format": 'A4'})
await browser.close()
第一次运行的时候,会自动下载chromium浏览器,chromium是chrome的开源版本, 需要几分钟才能下载完
[W:pyppeteer.chromium_downloader] start chromium download. Download may take a few minutes. 100%|██████████| 127496521/127496521 [00:20<00:00, 6268578.80it/s] [W:pyppeteer.chromium_downloader] chromium download done. [W:pyppeteer.chromium_downloader] chromium extracted to: C:\Users\lzjun\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458
执行完成后,我们来预览下pdf文件

和原文链接对比,发现文章中的图片丢失了。
通过分析,原来是页面源代码中,img 标签没有src属性,只有个data-src 属性,默认情况下图片是无法正常显示的,图片之所有能在浏览器能正常展示出来,是有个js脚本动态地修改了dom元素为,最后得以展现
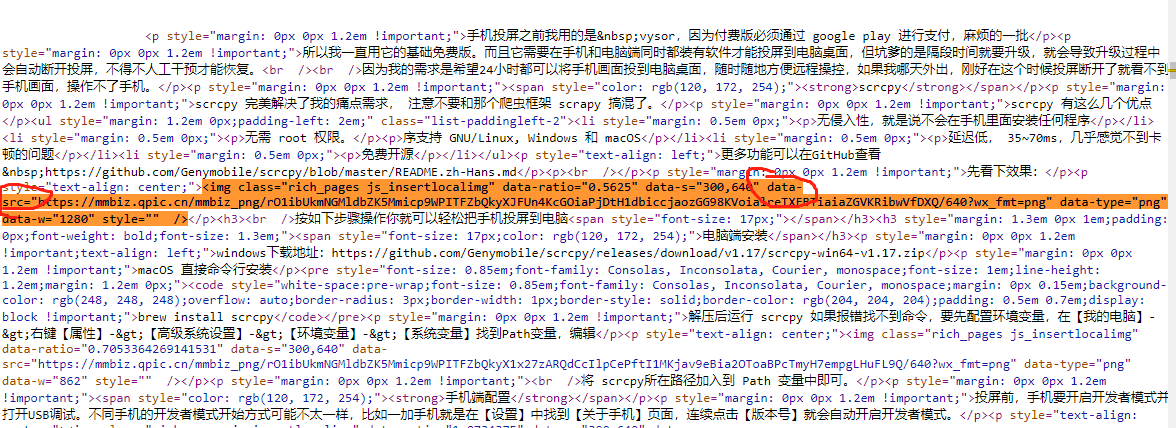
这个网页使用的是一种懒加载的技术展示图片内容,所谓懒加载就是图片不会一次全部下载完,而是当前浏览到什么位置,就加载该处的图片,这样能提高页面的响应速度,同时减轻服务器性能。
所以,我们也可以通过js代码模拟真人浏览网页一样,滚动鼠标,不停地往下滑动,将图片动态加载出来。
最后,完整代码就变成了这样:
async def main():
browser = await launch()
page = await browser.newPage()
url = "https://mp.weixin.qq.com/s/6VBXs19icV0O5hT7cHYwgw"
await page.goto(url)
await page.evaluate('''async () => {
await new
Promise((resolve, reject) => {
var
totalHeight = 0;
var
distance = 100;
var
timer = setInterval(() => {
var
scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight){
clearInterval(timer);
resolve();
}
}, 100);
});
}''')
await page.pdf({
"path": "test.pdf", "format": 'A4'})
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
将js 代码封装成一个字符串当作参数传给 page.evaluate 函数, 该代码就是获不断滚动页面,直到页面底部为止。这样整个页面的图片就全部加载出来了。
效果看起来还不错
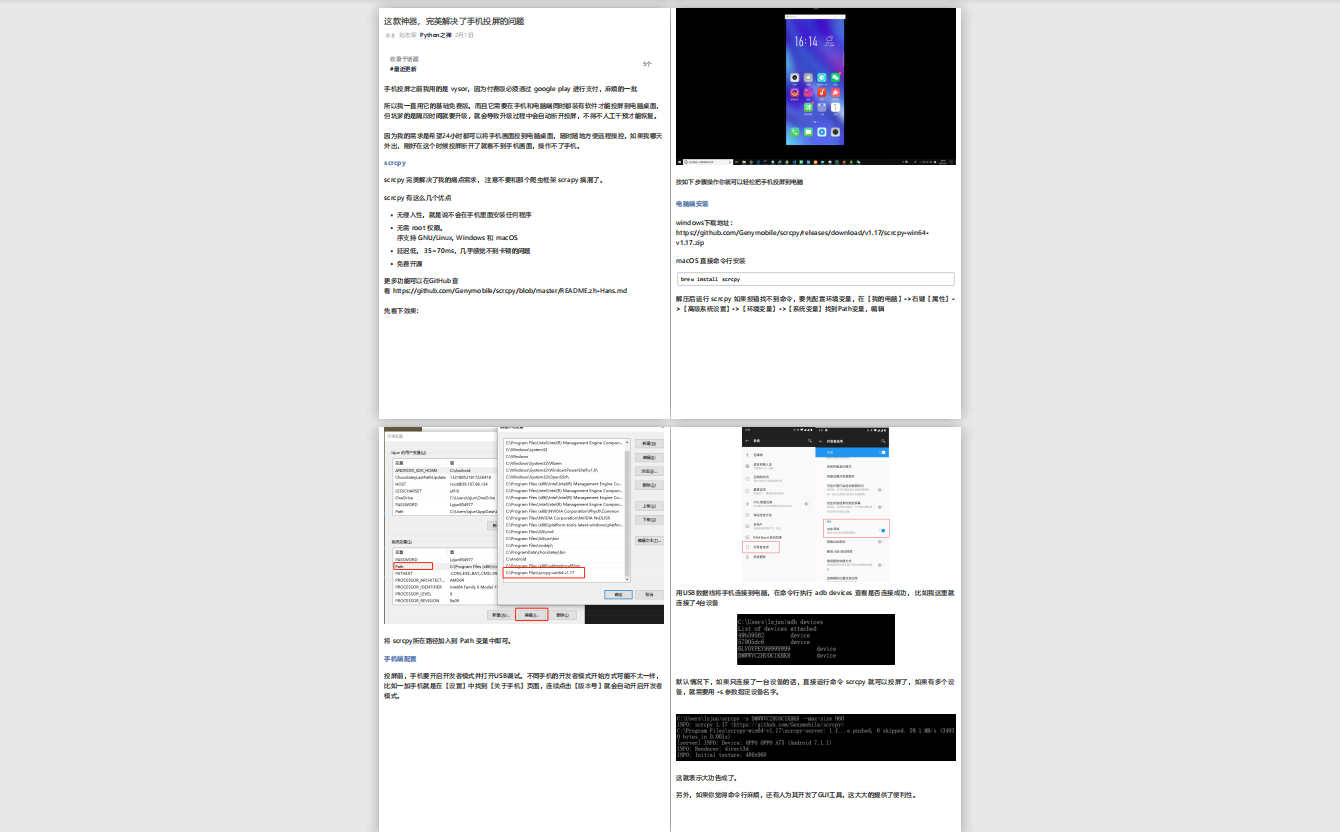
在Pyppeteer实践应用过程中,也遇到不少坑,最后都逐个解决了,这可以单独写一篇文章,如果你在使用过程中遇到任何问题欢迎与我交流
有问题可以扫描二维码和我交流
关注公众号「Python之禅」,回复「1024」免费获取Python资源

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK