

Java基础SE(二) 集合
source link: https://zhouj000.github.io/2021/02/26/java-base-collections/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

List是Java中最常用的集合类(容器),List本身是一个接口,其继承了Collection接口,并表示有序的队列。常用的List实现有ArrayList、LinkedList、Vector
ArrayList底层是用数组实现的,可以认为ArrayList是一个可改变大小的数组。随着越来越多的元素被添加到ArrayList中,其规模是动态增加的。ArrayList还实现了RandomAccess接口,获得了快速随机访问存储元素的功能
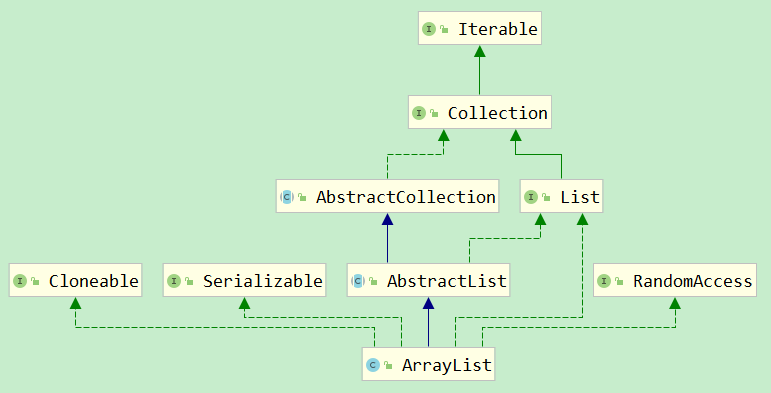
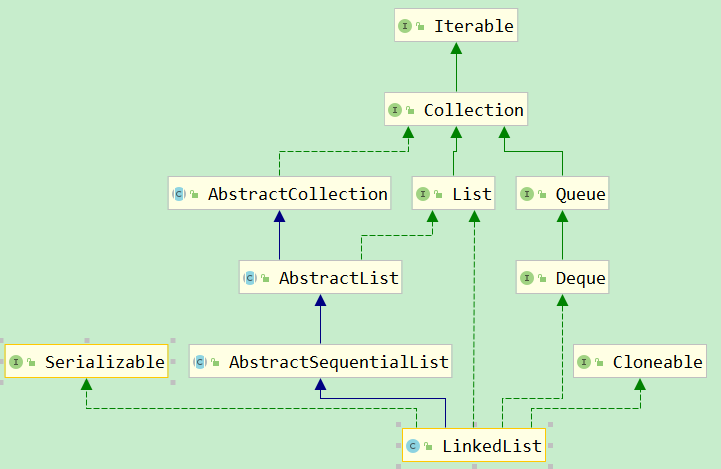
LinkedList底层是通过双向链表实现的。所以LinkedList和ArrayList之前的区别主要就是数组和链表的区别。数组中查询和赋值比较快,因为可以直接通过数组下标访问指定位置(寻址快);链表中删除和增加比较快(数组的动态扩容会比较慢,然而随着JDK发展,已经差不多了),因为可以直接通过修改链表的指针(引用)进行元素的增删。LinkedList还实现了Queue(Deque)接口,是一个双向队列,所以他还提供了offer()、peek()、poll()等方法
Vector和ArrayList一样,都是通过数组实现的,但是Vector是线程安全的,其中的很多方法都通过同步(synchronized)处理来保证线程安全,因此相对而言性能会差一点。它们的扩容大小也不同,默认ArrayList是增长原来的50%,Vector则增长原来的100%
ArrayList扩容:
// add时候传入最小扩容长度为size + 1,空列表时为10
private void ensureExplicitCapacity(int minCapacity) {
// 版本号++
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 内部用数组维护
transient Object[] elementData;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 默认增加一半,即原值的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 拷贝到新列表,底层还是用的System.arraycopy本地方法
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
LinkedList由于是双向链表结构,因此不需要扩容,只需要分别设置前节点,后节点即可
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}
对于Vector,基本上是个同步的ArrayList,不过扩容因子是增加1倍,即原值的2倍
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
ArrayList删除:
public E remove(int index) {
rangeCheck(index);
// transient 修改版本号
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
// 拷贝后面的到前面
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 最后一位置为null,然后size-1
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
Set是类似于List,又相较有点特殊的集合,里面存放的值是不重复的、大部分是无序的(按照哈希值来存的所以取数据也是按照哈希值获取)
HashSet内部维护了一个HashMap,将值传入其key,以传入值的hash值来保证唯一性。因此传入HashSet的对象需要实现hashcode和equals方法。putVal方法会使用对象的hashCode来判断对象加入的位置,即如果对象的hashCode值是不同的,那么就可以认为对象是不可能相等的。如果对象的hashCode相等,那么还会继续使用equals进行比较,如果为false那么依然认为新加入的对象没有重复,将以链状方式进行保存,否则即认为元素相同无法插入
public boolean add(E e) {
// HashMap# return putVal(hash(key), key, value, false, true);
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
LinkedHashSet继承自HashSet,不同点在于其创建调用父类HashSet的特殊构造方法时创建LinkedHashMap作为存储介质,因此它是稳定的,元素顺序是可以保证的,其他与HashSet一致。插入、删除操作相较HashSet会略慢,因为要维护链表,但相对有了链表的存在,遍历速度会更快
TreeSet其内部存储介质为NavigableMap,构造方法中创建TreeMap(继承自NavigableMap),是红黑树结构,每一个元素都是树中的一个节点,插入的元素都会进行排序,这保证了元素是有序的。它是SortedSet,其元素必须实现Comparable或继承Comparator,也具备了元素搜索功能。TreeSet判断元素重复并不是通过hashCode和equals,而是通过compare的结果来判断的。TreeSet支持两种排序方式:自然排序、定制排序。由于TreeSet需要额外的红黑树算法来维护集合元素的次序,因此性能不如HashSet
public boolean add(E e) {
// TreeMap#put
return m.put(e, PRESENT)==null;
}
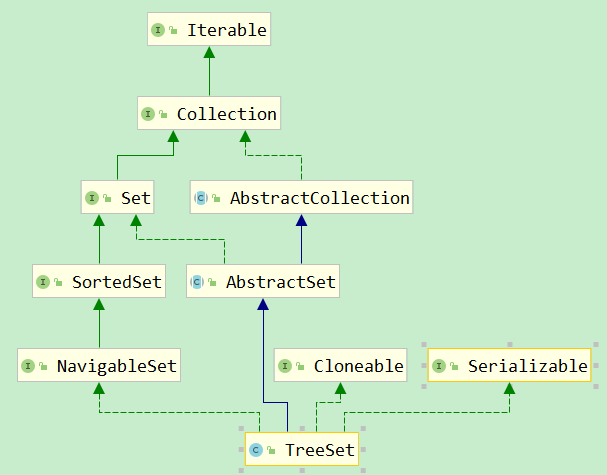
以上Set都是线程不安全的,通常可以通过Collections工具类的synchronizedSet、synchronizedSortedSet、synchronizedNavigableSet方法来包装Set集合
由于Set是基于Map来实现的,因此详细在Map中讨论
Map里存放key与value的映射信息,元素是成对存在的,就像一个字典一样,通过目录key查询内容value。它体现了一组关系或分组
HashMap内部存储的是Node对象,存储结构是数组,由key的hash值决定存储的槽位,同槽位value按照链或红黑树(8)存储
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
transient Node<K,V>[] table;
// 哈希算法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
当元素容量大于threshold(默认0.75)或第一次新增时,就会进行扩容resize方法,确认容量(范围内2倍增长)后创建新的Node数组,遍历老数组后放入新数组(重新hash)
h是hashcode,h
>>>16是用来取出h的高16(>>>是无符号右移) 由于和(length-1)运算,length 绝大多数情况小于2的16次方。所以始终是hashcode 的低16位(甚至更低)参与运算。要是高16位也参与运算,会让得到的下标更加散列
为了让高16也参与运算,h = key.hashCode()) 与 (h>>>16) 进行异或运算
如果使用 & 和 | 运算都会使得结果偏向0或者1,并不是均匀的概念,所以用 ^ 进行计算
java8还新增了compute、merge、forEach等方法,可以使用runnable方法对KV进行操作
HashMap高并发问题
HashMap在ReSize时,会进行两个步骤:1)扩容:创建一个新的Entry空数组,长度是原数组的2倍;2)ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。在高并发时,循环处理链条的next可能会形成循环链表,因此当get操作时会发生死循环
同样,在多线程下put操作时,执行addEntry(hash, key, value, i),如果有产生哈希碰撞,导致两个线程得到同样的bucketIndex去存储,就可能会出现覆盖的情况,导致元素丢失
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 原数组有元素,则是扩容,而非初始化
if (oldCap > 0) {
// 超过最大值不再扩充
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 旧阈值大于0
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
// 负载因子0.75 * 数组长度16 = 12,新阈值为12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果新阈值为0,根据负载因子设置新阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 旧数组有数据,复制到新数组
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 有元素的节点
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 数组
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 红黑树
else if (e instanceof TreeNode)
// 将原本的二叉树结构拆分组成新的红黑树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 链表
else { // preserve order
// jdk1.8中,旧链表迁移新链表,链表元素相对位置没有变化,实际是对对象的内存地址进行操作
// jdk1.7中,旧链表迁移新链表,如果在新表的数组索引位置相同,则链表元素会倒置
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
/**
hash值与旧的长度做与运算,判断元素在数组中的位置是否需要移动
数组的长度为 2^N,即高位为1,其余为0,计算 e.hash & oldCap 只需看oldCap最高位1所对应的hash位
因为 newCap 进行了双倍扩容,即将 oldCap 左移一位,那么 oldCap-1 相当于 newCap-1 右移一位,右移后高位补0,与运算只能得到0
如果 (e.hash & oldCap) == 0,hash值需要与运算的那一位为0,那么 oldCap - 1 与 newCap - 1 的高位都是0,其余位又是相同的
表明旧元素与新元素计算出的位置相同
同理,当其 == 1 时,oldCap-1 高位为0,newCap-1 高位为1,其余位相同,计算出的新元素的位置比旧元素位置多了 2^N
即得出【新元素的下标 = 旧下标 + oldCap】
**/
// 如果为0,元素位置在扩容后数组中的位置没有发生改变
if ((e.hash & oldCap) == 0) {
if (loTail == null)
// 首位
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 不为0,元素位置在扩容后数组中的位置发生了改变,新的下标位置是 原下标位置 + 原数组长度
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 存入新数组
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
LinkedHashMap继承自HashMap,其Entry继承自HashMap.Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
显然Linked就说明了这些元素以链表形式存在,而非HashMap的数组。并且LinkedHashMap本身记录了head和tail。总体和HashMap类似,其中对数组的操作变为了对链表的操作(before、after)。并且链表的结构确定了存储的顺序与插入顺序一致,即有稳定性,相反也意味着不会和HashMap一样有元素的hash值的排序
Hashtable是HashMap的安全版本,即synchronized修饰方法,牺牲性能保证线程安全性
TreeMap会保证插入元素存储的顺序性,内部维护这root节点和Comparator比较器,确保构建的树是有序的。TreeMap维护的树是一颗红黑树(更高效的二叉搜索树),因此保证了当前节点的左子树都小于自己,而右子树都大于自己,这样就可以通过Comparator比较来确定向左还是向右查找,且是按key有序的。但是这也为新增/修改元素增加了复杂度,因为可能需要重新构建红黑树:
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
// ...
}
public V put(K key, V value) {
Entry<K,V> t = root;
// 第一次就直接构建根节点
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
// 找到插入元素的父节点
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
} else {
if (key == null)
throw new NullPointerException();
// 使用key自己的Comparable方法
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 修改红黑树,左旋或右旋保证弱平衡且符合红黑规则
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
Queue
java的Queue常用子接口有AbstractQueue(非阻塞队列),BlockingQueue(阻塞队列), Deque(双端队列)
其中add(e)与offer(e)类似,区别是前者插入队尾失败会抛出异常。element()与peek()类似,会获取队首元素,区别也是前者失败会抛出异常。remove()与poll()也类似,会移除并获取队首元素,区别同上,失败时前者抛出异常,后者返回null
LinkedList在前面讲过,它其实除了做链表使用,还可以当做堆栈、队列、双端队列进行操作
PriorityQueue里有Comparator比较器,是一个基于优先堆的一个无界队列,不允许null和无法比较的对象存入。这个队列是非安全的,因此还有PriorityBlockingQueue解决多线程安全问题。PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示,即任意一个非叶子节点的权值都不大于其左右子节点的权值,因此可以通过数组来作为PriorityQueue的底层实现,且位置满足以下规则:
leftNo = parentNo * 2 + 1
rightNo = parentNo * 2 + 2
parentNo = (nodeNo - 1) / 2
这也意味着如果改变元素,可能会破坏小顶堆的性质,因此需要进行必要的调整:
transient Object[] queue;
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1); // 扩容
size = i + 1;
if (i == 0) // 如果这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e); // 调整
return true;
}
下面看下比较器的调整:
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
// 从指定位置k开始,将x逐层与当前点的parent进行比较并交换,直到满足 x >= queue[parent]为止
while (k > 0) {
// parentNo = (nodeNo-1)/2
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
删除操作也会改变队列的结构,因此也需要进行必要的调整:
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0]; // 0下表即最小值,即队首
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x); // 调整
return result;
}
也是看比较器的调整:
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1;
// 从k开始,将x逐层向下与当前点孩子中较小的那个交换,直到x小于或等于孩子中的任何一个为止
while (k < half) {
// 首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1; // leftNo = parentNo * 2 + 1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
/ 然后用c取代原来的值
queue[k] = c;
k = child;
}
queue[k] = x;
}
除了基本的Queue操作,BlockingQueue有阻塞方法和阻塞超时方法,分别是插入put(e)、offer(e, time, unit),移除tak()、poll(time, unit),实现主要用于生产者消费者队列。都是线程安全的,使用ReentrantLock锁的方式保证
ArrayBlockingQueue是一个由数组结构组成的有界阻塞队列,内部为循环数组。是一个典型的有界缓存区,一旦创建就不能增加容量。试图向已满队列中放入元素会导致操作阻塞;试图从空队列中提取元素将同样阻塞。使用独占锁lock用来对出入队操作加锁,默认是非公平锁,支持公平策略,打开后构造的队列允许按照FIFO顺序访问线程。但会降低吞吐量。notEmpty,notFull条件变量用于入队出队时take和put的阻塞
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
看一下put方法,全局独占锁粒度很大,类似于方法上加synchronized
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length) // 循环队列
putIndex = 0;
count++;
notEmpty.signal();
}
LinkedBlockingQueue是基于Node链表的任意容量范围的队列。链表队列的吞吐量通常要高于基于数组的队列,但通常性能要低。如果指定容量,则可以防止队列过度扩展,未指定容量则等于Integer.MAX_VALUE。队列内部维护了head节点和last节点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue具有两个非公平独占锁ReentrantLock,分别用来控制元素入队和出队加锁,可以由一个线程入队和一个线程出队,是一个生产者-消费者模型
/** Current number of elements */
private final AtomicInteger count = new AtomicInteger();
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
Stack
Stack继承Vector,是一个基于数组的安全栈,很简单
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
// 数组倒着取即可
removeElementAt(len - 1);
return obj;
}
其他安全容器
对于List容器,除了Vector外,还提供了2类安全队列,分别是CopyOnWriteArrayList和Collections.synchronizedList,它们都是可存null、稳定、无序的线程安全队列。
CopyOnWriteArrayList内部基于数组存储,读写分离,最终一致,修改代价会越来越昂贵
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
在添加、删除元素时会加锁,并且拷贝一个新的数组作为自身的array,写数组的拷贝,读操作无锁的,线程安全,另外与ArrayList差不多。因此适合读多写少的场景,不适合写多和需要实时读的场景
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
Collections.synchronizedList使用的是装饰器模式,每个操作都加上了synchronized保证线程安全
CopyOnWriteArraySet与Collections.synchronizedSet是Set容器的安全版本,与上面的一样。其中CopyOnWriteArraySet内部使用CopyOnWriteArrayList作为存储容器
ConcurrentHashMap是一个基于Node数组的,不可存null,稳定无序的、安全的Map容器。采用了CAS +synchronized的方案保证线程安全。和HashMap一样,从1.7的Segment(继承ReentrantLock)数组 +HashEntry并采用分段锁的方案优化为1.8的这样,提升了查询遍历链表效率
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 获取hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果tab为空,初始化node数组
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// f为空,说明第一次在这个位置插入元素,用CAS插入Node节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果f的哈希为-1,说明当前f是ForwardingNode节点,表示有其它线程正在扩容,则一起进行扩容操作
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 把新的Node节点按链表或红黑树的方式插入到合适的位置
else {
V oldVal = null;
// 加锁
synchronized (f) {
// 插入前再次判断,防止被其他线程修改
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
// 遍历链表,找到对应的节点则修改值,否则在队尾加入节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果f是TreeBin,说明是红黑树节点,在树上操作
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 链条中节点数大于8,则将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 最后进行扩容判断
addCount(1L, binCount);
return null;
}
Collections.synchronizedMap和之前的一样,只是个装饰器模式包了一个Map
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,不允许使用null,有序稳定。ConcurrentLinkedQueue中有两个volatile类型的Node节点分别用来存储列表的首尾节点,Node节点链接为一个单向无界链表。ConcurrentLinkedQueue使用CAS非阻塞算法解决线程安全问题,而没有使用锁,因此并发情况下size()并不准确。为了保证head、tail这2个Node操作的可见性和原子性是使用了volatile + CAS
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p is last node
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}
fail-fast与fail-safe
fail-fast会在以下两种情况抛出ConcurrentModifcationException:
1、单线程环境:集合被创建后,在遍历它时修改了解构(例外:remove()方法会让expectModCount与modCount相等而不会抛出异常)
2、多线程环境:但一个线程在遍历该集合,而另一个线程进行了修改
fail-safe任何对集合的修改都在一个复制的集合上进行修改,因此不会抛出异常,但有两点需要注意:
1、需要复制集合,产生大量对象,开销大
2、无法保证读取的是目前原始数据结构中的数组
样例:CopyOnWriteArrayList、ConcurrentHashMap
Arrays.copyOf 与 System.arraycopy
// src:要复制的数组 srcPos:要复制的数组中的起始位置
// dest:副本数组 destPos:副本数组中的起始位置
// length:要复制的数组元素的数量
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
由上面Arrays.copyOf方法最终还是调用了System.arraycopy本地方法,方法返回的副本都是一个新数组,其长度选择参数值与原数组长度中的最小值
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK