

Lucene系列(五)索引格式之fdm文件
source link: http://huyan.couplecoders.tech/lucene/%E6%90%9C%E7%B4%A2%EF%BC%8C%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6/2020/12/27/lucene%E7%B3%BB%E5%88%97(%E4%BA%94)%E7%B4%A2%E5%BC%95%E6%A0%BC%E5%BC%8F%E4%B9%8Bfd%EF%BD%8D%E6%96%87%E4%BB%B6/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Lucene系列(五)索引格式之fdm文件 - 呼延十的博客 | HuYan Blog
本文使用 Lucene 代码版本:8.7.0
首先学习一下 lucene 的索引文件结构。本文介绍 Field 相关信息的存储文件格式。
当你在写入 field 信息时,如果像下面这样,指定了 Stored. 也就是希望 lucene 能够保存你的原始 Field 信息,那么就会生成三个文件 .fdt .fdm .fdx.

- .fdt 文件保存了原始的 field 信息
- .fdx 文件保存了一些帮助读取 fdt 的索引信息
- .fdm 文件保存了一些基本的元数据,也包括一些辅助读取 fdx 文件的信息。
本文首先介绍 fdm 的文件格式,及学习一下其在 Lucene8.7.0 中的写入相关代码。
.fdm 文件整体结构
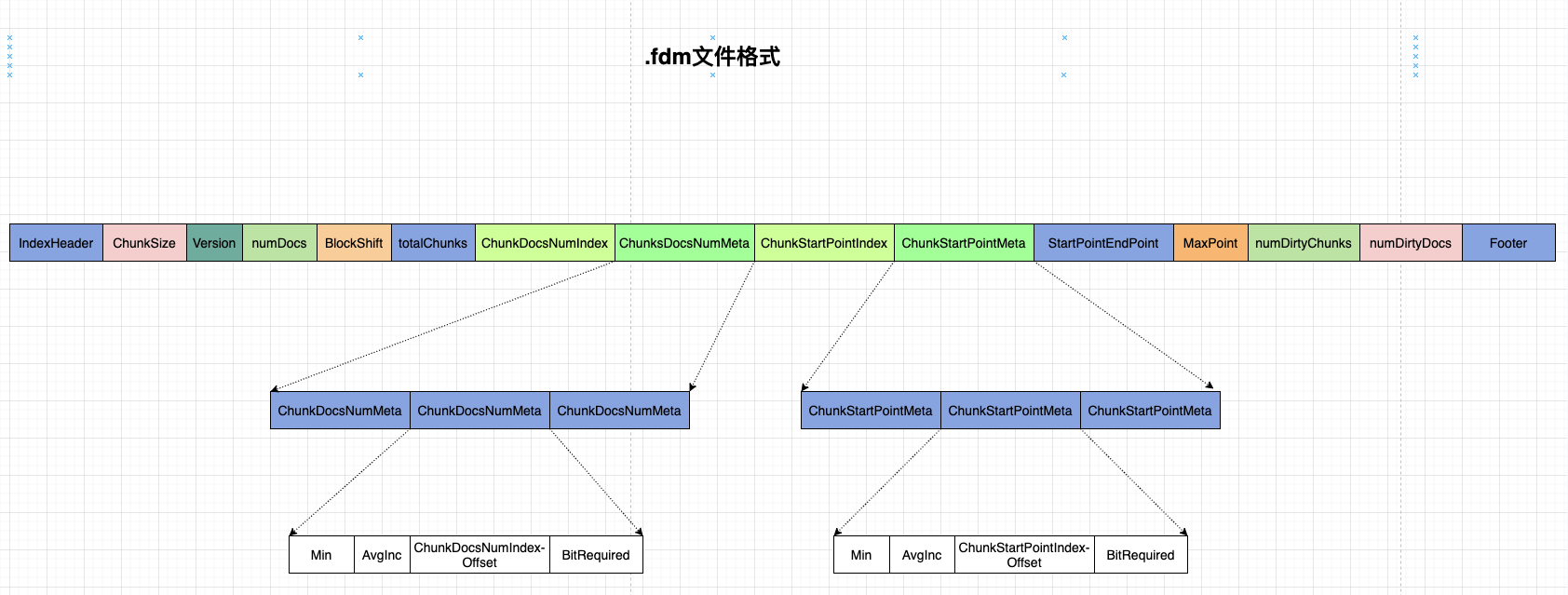
- IndexHeader 索引文件头 lucene 对于索引文件,会写一个文件头,来标识一些基本的数据。
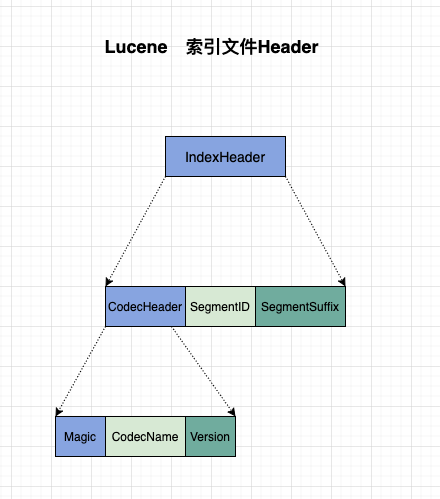
- CodecHeader: 一个编码的 Header.
- SegmentID: 当前 Segment 的 ID, 随机生成的 16 位字符串
- SegmentSuffix: 当前 Segment 的后缀
- Magic: 一个魔法数字,永远是:0x3fd76c17.
- CodecName: 当前编码的名字,比如对于当前的 fdm 文件时:”Lucene85FieldsIndexMeta”
-
Version: 一个内部的版本号,不是 lucene 版本号哦。
- ChunSize 每个 Chunk 中的 doc 数量
- Version 版本号
- NumDocs: doc 数量的总数
- BlockShift: 控制 chunk 信息写入时的分块,2 ^ blockShift 为一块。
- totalChunks: 总共有多少个 chunk
- ChunkDocsNumIndex: 存储每个 chunk 中 doc 数量的内容,在 fdx 文件中的起始偏移位置
- ChunksDocsNumMeta: fdx 文件中存储 Chunk 中 doc 数量,用到的一些元数据
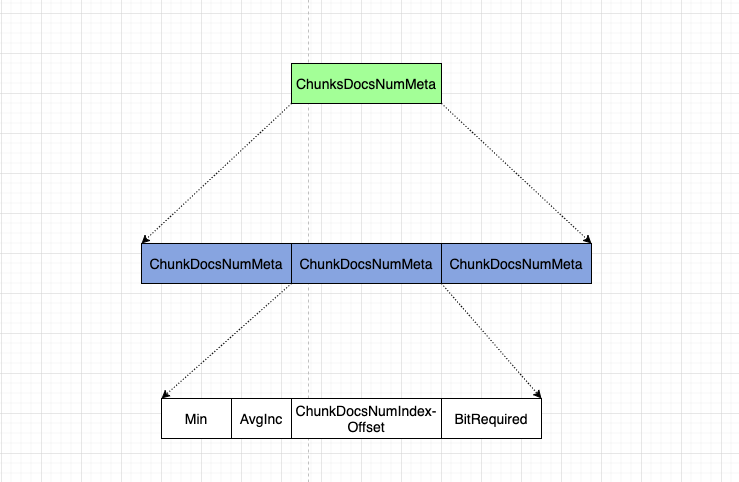
在 fdx 文件中,存储每个 chunk 中的 doc 数量时,使用了DirectMonotonicWriter类来进行存储,这个类用来存储单调递增数组,能够进行一些压缩。具体的别的文章中详细说~
为了完成压缩的功能,需要一些数字进行辅助,就是下面这几位咯。
- Min : 通过编码计算的最小值
- AvgInc: 通过编码计算的平均斜率
- ChunDocsNumIndex: 从开始写入到现在,fdx 文件的偏移量
- BitRequired: 所有要写入的数字,最大需要多少位才能存储
- ChunkStartIndex: 存储
每个 chunk 数据起始位置数据的起始位置 - ChunkStartPointMeta: 存储每个 chunk 数据起始位置的一些元数据
在储存每个 chunk 的数据在 fdx 文件中的起始位置的相关数据时,和上面的 chunk 内 doc 数量一样,做了一些压缩~
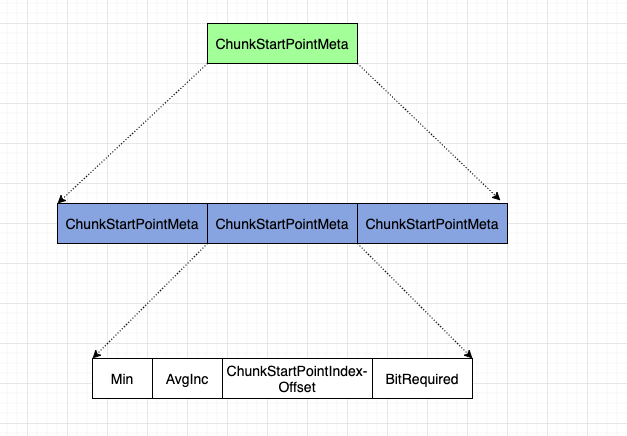
- Min : 通过编码计算的最小值
- AvgInc: 通过编码计算的平均斜率
- ChunDocsNumIndex: 从开始写入到现在,fdx 文件的偏移量
- BitRequired: 所有要写入的数字,最大需要多少位才能存储
- StartPointEndPoint: 存储
每个 chunk 数据起始位置的数据的结束位置。 - MaxPoint: fdx 的最大写入位置
- numDirtyChunks: 脏的 chunk 的数量,当 chunk 并没有到达数量,而是强行进行 finish, 那么相关的 chunk 和 doc 就是 dirty 的。这两个变量记录了一下相关的数量。
- numDirtyDocs: 脏的 doc 的数量
- footer: 索引文件的脚部
知其然知其所以然
每个字段,每段数据,是为什么存储,其实我不太知道。目前看的代码还不是很多。
但是我们应该知道,所以我罗列在这里,不知道的后来补上~
DirectMonotonicWriter中详细解释
AvgInc
通过编码计算的平均斜率
DirectMonotonicWriter
ChunDocsNumIndex
从开始写入到现在,fdx 文件的偏移量
DirectMonotonicWriter
BitRequired
所有要写入的数字,最大需要多少位才能存储
DirectMonotonicWriter
ChunkStartIndex
存储每个 chunk 数据起始位置的位置
方便读取 fdx 文件
ChunkStartPointMeta
存储每个 chunk 数据起始位置的一些元数据
同上
StartPointEndPoint
存储每个 chunk 数据起始位置的数据的结束位置
同上
MaxPoint
fdx 的最大写入位置
同上
numDirtyChunks
脏的 chunk 的数量
不确定
numDirtyDocs
脏的 doc 的数量
不确定
footer
索引文件的脚部
用来表示文件结束,同时里面含有 CRC32 来 check 文件数据是否正确。
相关代码分析
在 8.7.0 版本,对 Field 相关信息的存储在org.apache.lucene.codecs.compressing.CompressingStoredFieldsWriter类中。
首先,在类构造函数中,进行了 fdm 文件的初始化,之后写入了 IndexHeader. 以及chunkSize及Version.
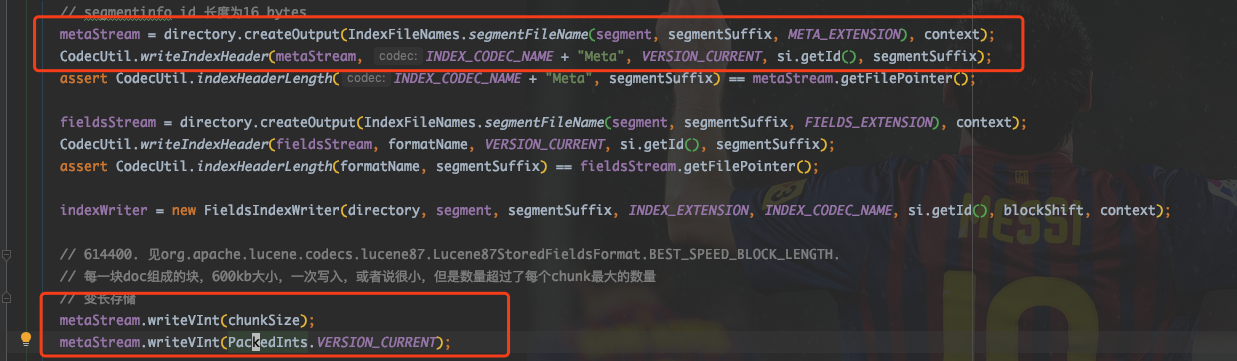 .
.
之后在程序不断的添加 Document 过程中,不再写入 fdm 文件,在所有 Document 全部写入之后,会调用
org.apache.lucene.codecs.compressing.CompressingStoredFieldsWriter#finish 方法,在该方法中,写入了部分数据。
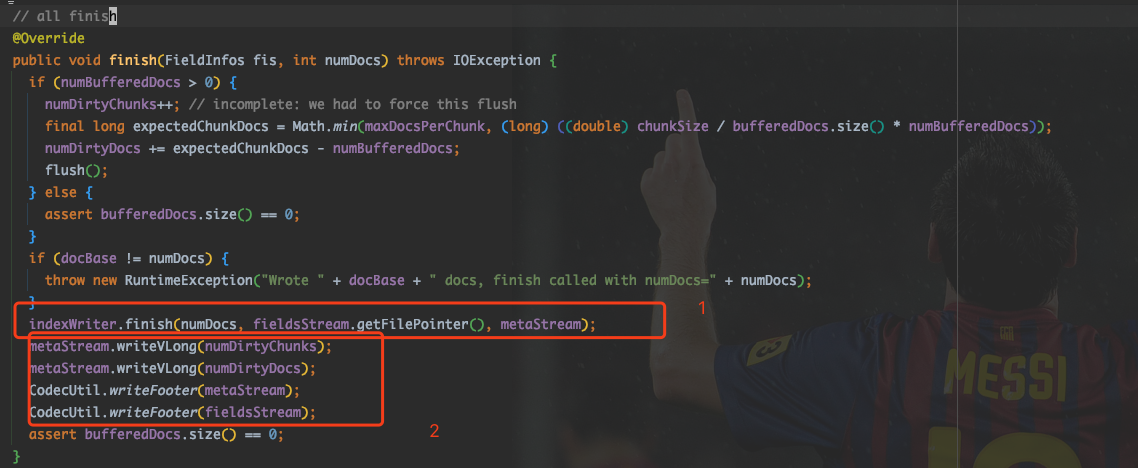
如上图所示,在 1 处写入了 fdm 配合 fdx 文件的一些元数据。
在 2 处写入了numDirtyChunks,numDirtyDocs 及 Footer.
在 1 处,配合 fdx 文件写入了些什么呢?
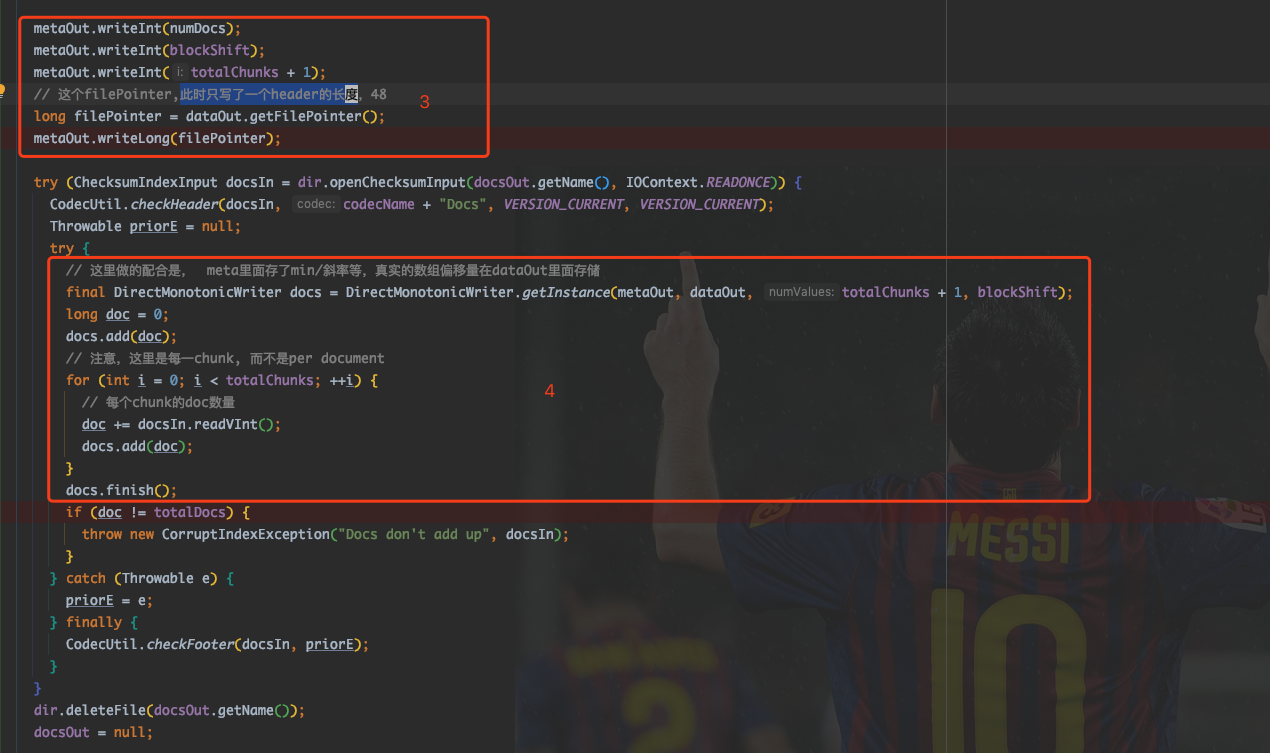
在 3 处,写入了numDocs, blockShift, totalChunks, filePoint等信息。这些都是顺序的,和前方的整体格式图一一对应。
比较麻烦的是,在上图中 4 处,在 fdx 文件存储所有 chunk 中 doc 数量时,应用了DirectMonotonicWriter 类来进行存储,该类的具体实现可以阅读延伸阅读中的文章。DirectMonotonicWriter 源码分析
该类大致做了什么呢?
- 所有 chunk 的 doc 数量。
- 所有 chunk 具体信息存储的 point.
这两个数组都是单调递增的,因此DirectMonotonicWriter类就是专门用来存储单调递增数组的。
根据单调递增这个因素,对传入的 int 数组进行了压缩,压缩中用到了几个参数,在之后复原数据时需要。那就是Min,AvgInc,Offset,BitRequired. 这里使用了 fdm 文件来存储这几个参数而已。
DirectMonotonicWriter类的原理解析。具体文章还没写哈哈哈。
https://www.amazingkoala.com.cn/Lucene/suoyinwenjian/2020/1013/169.html
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:[email protected]
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK