

谈谈推荐系统中的用户行为序列建模
source link: https://zhuanlan.zhihu.com/p/138136777
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

上一篇[《从谷歌到阿里,谈谈工业界多目标预估的两种范式》发布后,获得了很多赞,也让我这个知乎小透明涨了一些粉,非常开心。
鱼罐头啊:从谷歌到阿里,谈谈工业界推荐系统多目标预估的两种范式zhuanlan.zhihu.com
深度学习模型可以看做是在搭“乐高”,底层使用的那些模块(Attention/RNN/CNN/Transformer等)就是积木。当面临一个具体的问题时,找到合适的积木,搭建好适合某个问题的乐高就显得十分重要。
在推荐系统中,用户行为序列建模是一个非常重要的话题。近些年来,在深度召回(Deepmatch)、深度排序(精排和重排)等领域发表的工作,一个很重要的方向就是优化用户行为序列建模的方式。
本文大概会包含两部分内容:一、大致谈谈我理解的,推荐系统中的用户行为序列建模,为什么要进行用户行为序列建模;二、谈谈做用户行为序列建模时,算法底层积木有哪些,大概怎么用。
心有沟壑,遇事不慌,在做用户行为序列建模时,深入理解这些积木的作用,信手沾来以致巧妙创新是坠好的,但如果真的不知道咋搞,暴力尝试也不失为一个好选择...
话不多说,进入正题。
推荐系统、召回、排序和用户行为序列建模
目前工业界的推荐系统依旧沿用着Google 16年发表的 《Deep Neural Networks for YouTube Recommendations》框架。
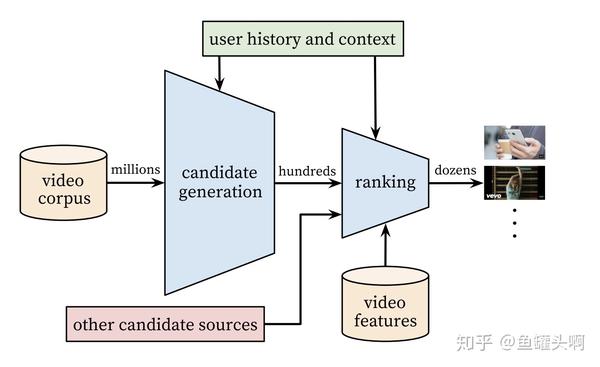
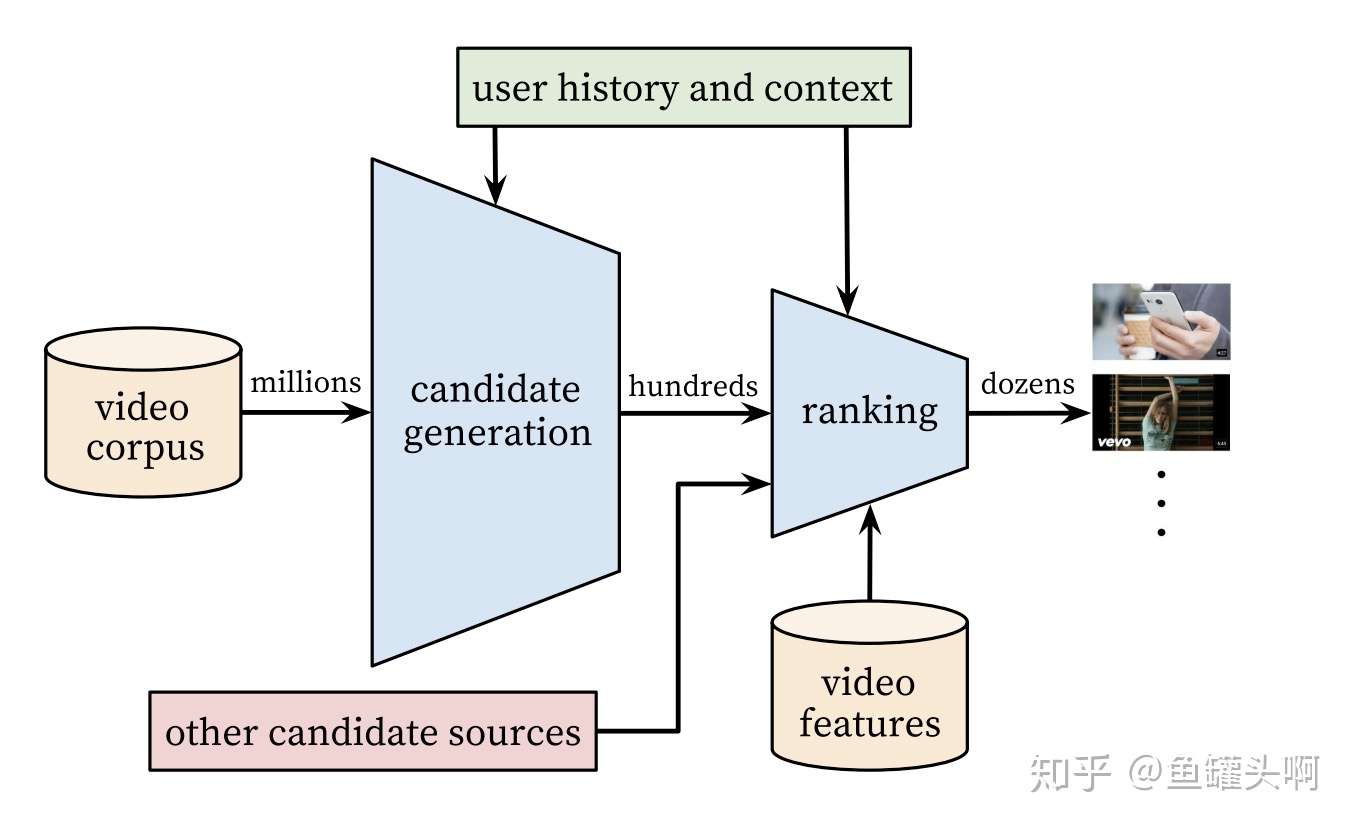
大概是这样一个pipeline:
- Matching:一般包括召回和粗排两个部分。召回部分负责从全库召回/检索物料(商品、内容、广告等),一般要求各路召回覆盖各个角度,因此数量级依旧很巨大(一般在万量级);粗排部分负责将各路召回的内容进行统一的排序,取出top的内容送入到排序模块中。为什么不直接送到排序模块中呢?排序模型一般比较复杂,而一般推荐对rt有着比较高的要求,因此排不了所有的物料。粗排一般使用一些不那么复杂的模型,例如gbdt,lr,fm等,近期也有一些工作使用知识蒸馏的方法做粗排,感觉也很有意思,有机会实践的话也可以来分享下~
- Ranking:一般包括精排和重排等部分。精排部分主要涉及到的技术为点击率预估(CTR预估),使用point-wise的方法对<user,item,context>三元组打出一个分,然后进行排序。一般推荐系统的商业目标都比较复杂,拆解到推荐系统也不仅仅包含一个目标,因此也会涉及到多目标预估的问题;精排模型一般都是point-wise的,排序出的top内容可能都是近似的,直接展现效果和观感都有一定损失,而重排模型负责对整个推荐列表进行优化;若推荐列表中涉及到多种不通过的物料,还涉及到物料之间的混排。
除此之外,一般推荐系统也包含一个规则模块,支持打散、白/黑名单、调权等业务逻辑。
介绍完推荐系统,再介绍下深度召回(Deepmatch)和排序的异同,以及为什么用户行为序列建模很重要。
通常来讲,Deepmatch的问题定义是:预测用户下一个会点击的物料。而排序处理的问题是:预测用户对某个商品的点击率。两者都可以利用的信息为:用户的静态profile(包括统计特征)、用户的行为序列(包括上下文信息)、内容的静态特征(包括统计特征)。
两者的主要差别为:Deepmatch中没有目标物料(target item)的概念,而排序中可以使用目标物料,同时也可以基于目标物料做一些交叉特征。
直观的思考是,如果不使用用户行为序列建模,只使用用户静态的profile和内容静态特征做推荐可以吗?无疑是可以的,实际上,一些小流量的推荐场景,缺少用户历史的行为信息,基本上就是利用这些信息进行推荐。但是一旦用户行为足够,基本上大家都会围绕用户行为序列做一些事情。
想了下大概有以下几种理由。第一,推荐系统本质上也是一种"信息的利用",提升它有两种方式,一种是引入新的信息,一种是更有效的利用已有的信息,引入用户行为序列特征无疑属于引入新的信息。第二,推荐系统中的用户兴趣变化非常剧烈,比如电商推荐中,用户一会看看服饰,一会看看电子产品,若只使用静态特征进行推荐,每次推荐的内容是一样的,这无疑是不能满足用户需求。
因此用户行为序列的建模十分重要,且越实时越好。
浅谈用户行为序列建模
大致来讲,用户行为序列建模包含以下几种方式:
- pooling-based architecture范式,特点是将用户历史行为看做一个无序集合,方法有sum/max pooling,和各种attention等
- sequential-modeling architecture范式,将用户行为看做一个具有时间属性的序列,方法是有RNN/LSTN/GRU等
- 一种抽取/聚类出用户多峰兴趣,方法有Capsule等
- 另外根据业务场景的特殊,也会涉及到一些其他的方法
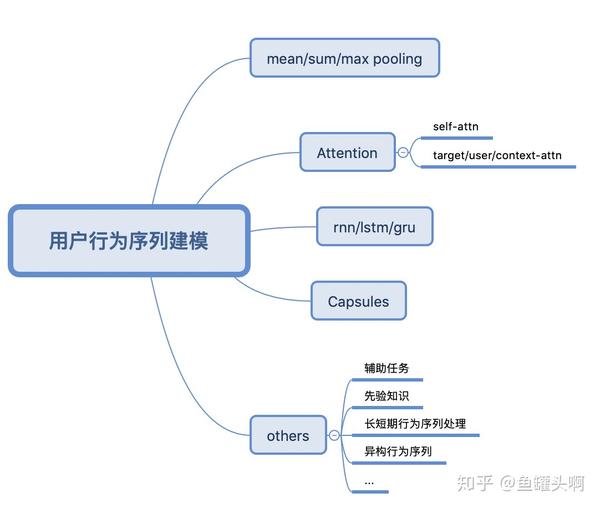
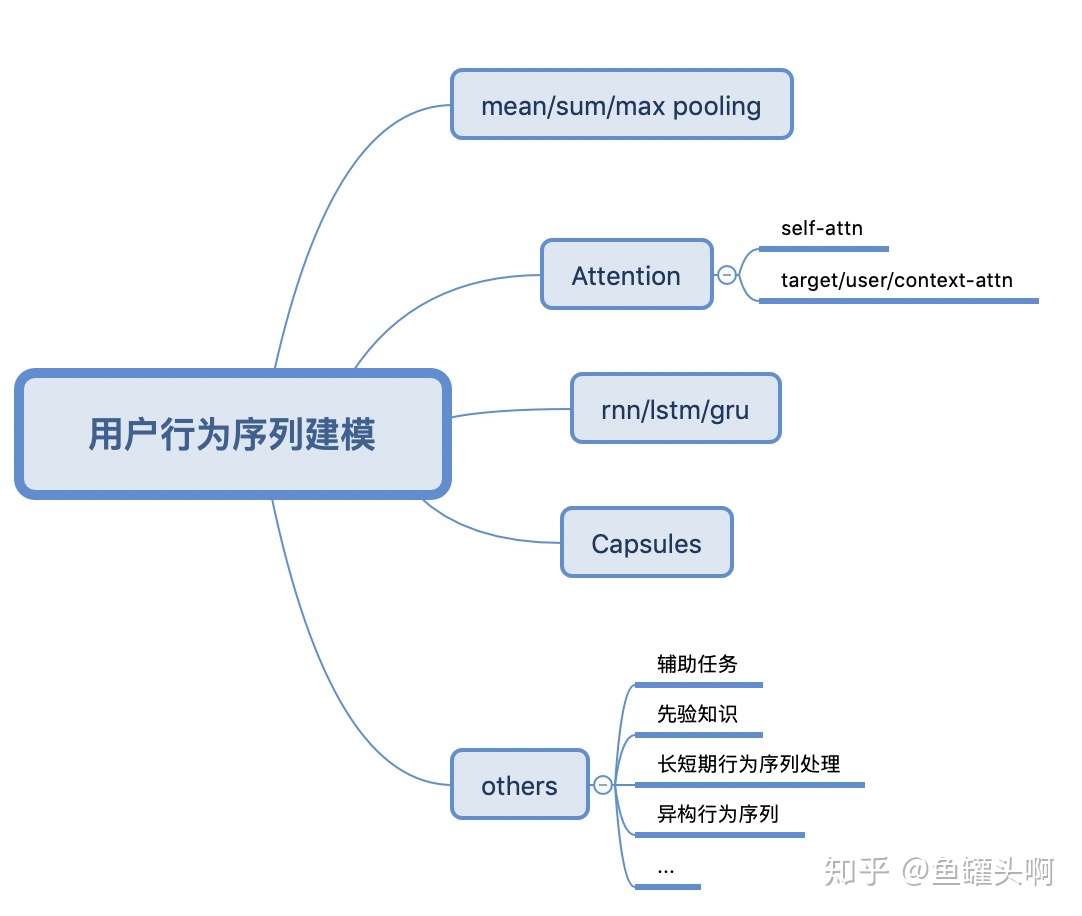
有趣的是,不同的方法之间可以进行组合/叠加,是不是越来越像在搭积木了呢^^。
下面分别进行介绍。
各种pooling方法
又要提到Google那篇《Deep Neural Networks for YouTube Recommendations》了。这篇文章提出的Deepmatch和Deep ranking model结构中,将用户观看过的视频序列取到embedding后,做了一个mean pooling作为用户历史兴趣的表达。
这种方式比较简单,但是简洁好用。通常情况下可以作为一个baseline。
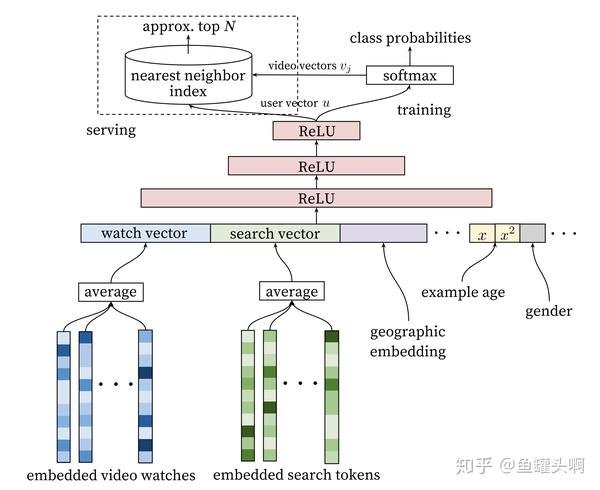
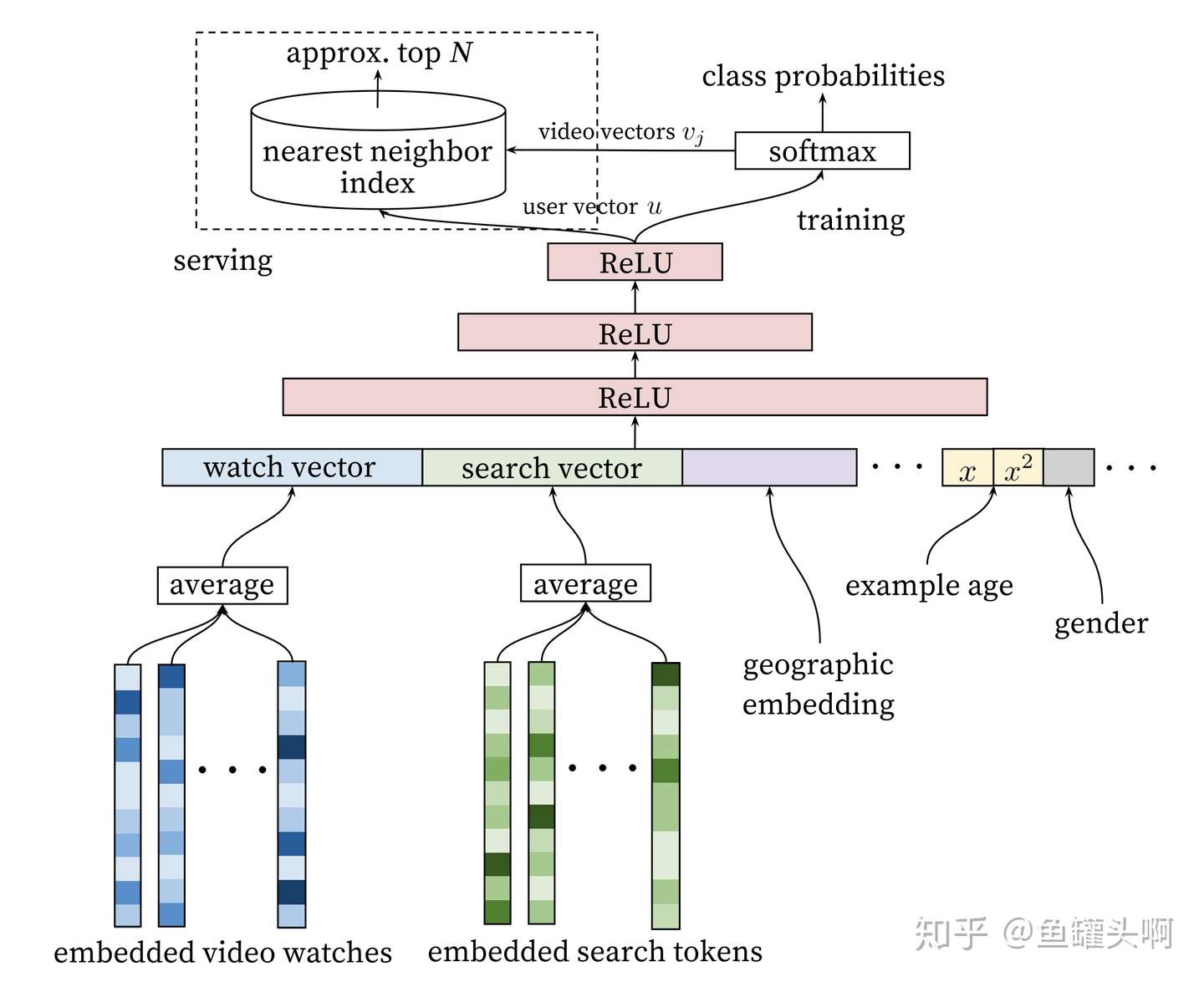
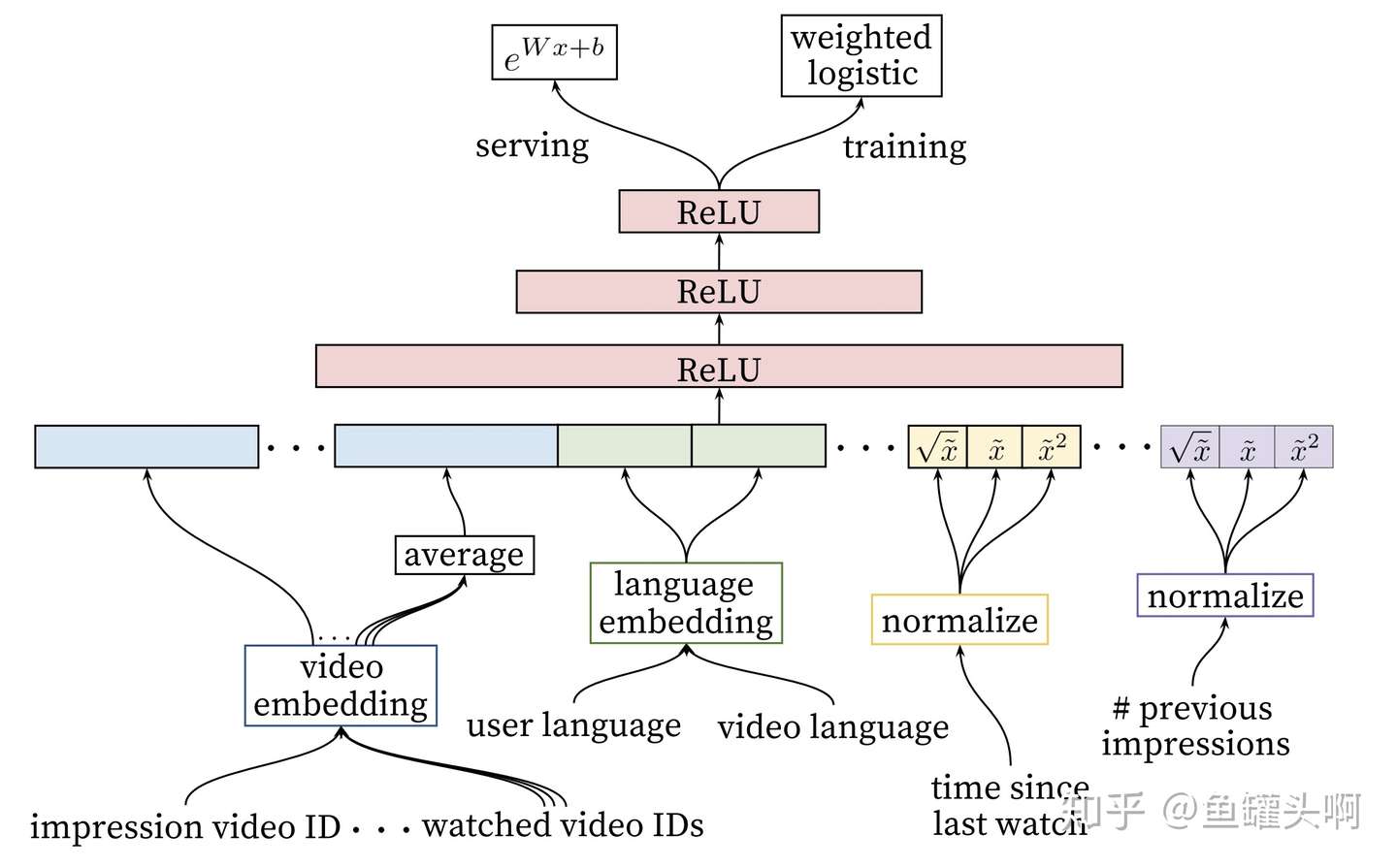
target/user/context attention方法
上述将用户行为序列中的各个item取embeddding,然后做pooling的方法,本质上将用户点击过的各个item当做同等重要。
实际上,用户点过的item对任务的贡献度是不同的。举个例子,在排序任务中,预测user点击某个target item的概率,user历史上点过的和target item同一类目的item明显会起到更加重要的作用。
事实上,围绕这一点设计一种类目hit特征,一般都十分有效。
有没有更加优雅的方法呢?阿里妈妈17年提出了DIN模型第一次将attention思想引入ctr预估模型。将target item和行为序列中的item做一个attention,得到一个weight,然后进行加权求和后,再和user profile features、candidate items、context features concat后,加入几层mlp。
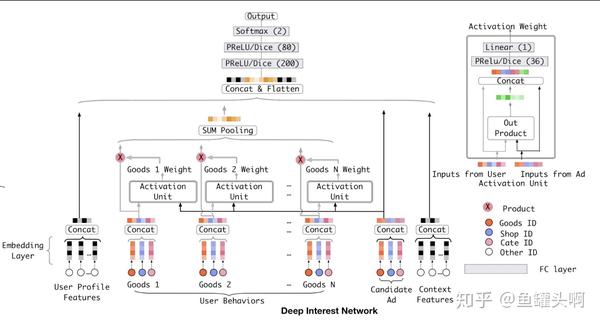
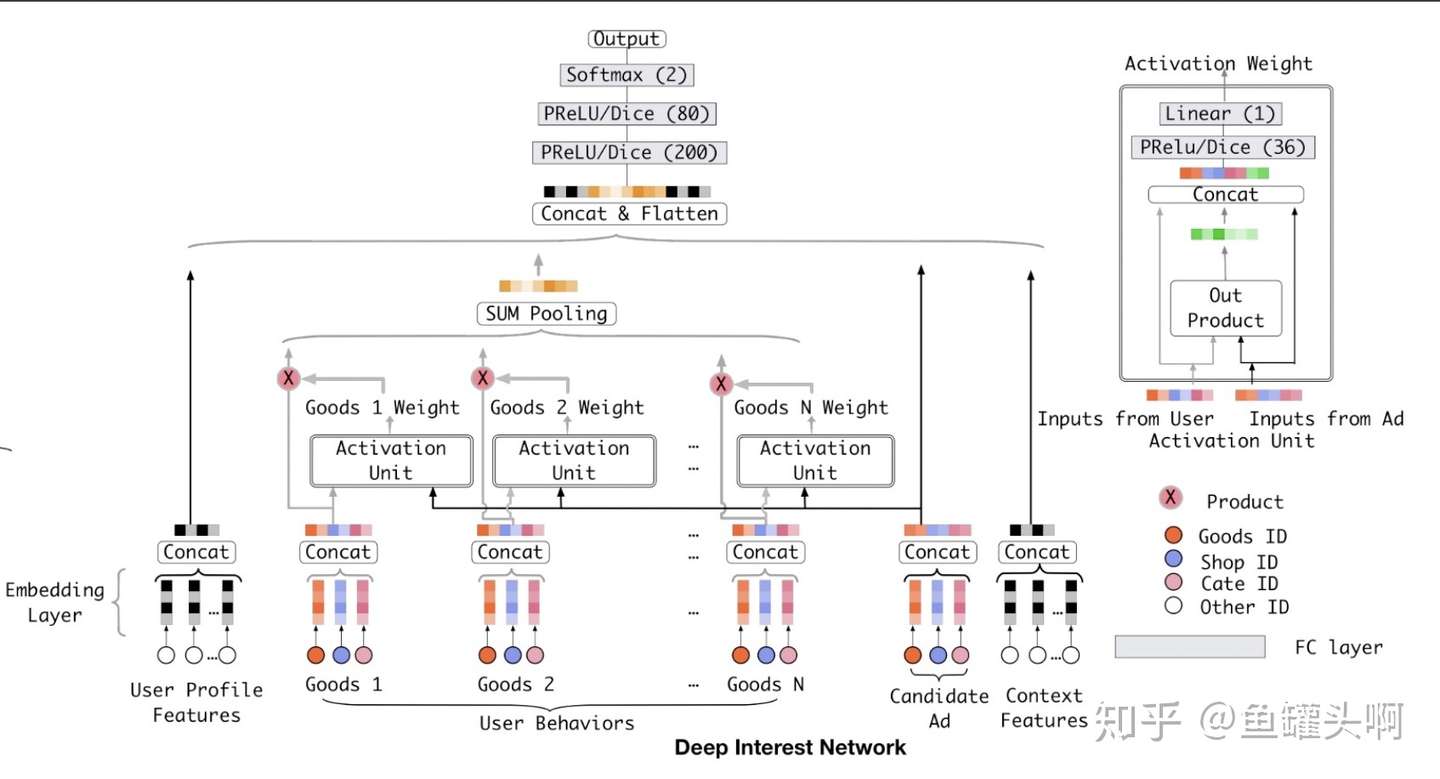
DIN是CTR预估领域非常重要的一篇文章,但其涉及到target item和行为序列item的attention,而召回中是没有target item的。那么能否也改造下Google提出的Deepmatch方法,让它也用上attention呢?
其实,target attention的思想稍微引申下,就可以变成user attention、context attention等。例如,将user profile得到的embedding,和用户序列中的item做一个attention,就是user attention。将行为序列item对应的context特征(行为序列位置、停留时长等)embedding化后和其他side info做一个attention,就是context attention。
上面提到的各种信息可以自由组合做attention,以及attention的方式也可以变一变,Bagdanau attention/Luong attention等都可以试一试,很符合我们搭积木的宗旨嘛。
transformer大名鼎鼎,已经有好多很好的文章介绍,写其内部细节,这里并不打算当搬运工。如果有同学没有看过的话,除了原文外,首推Jay Alammar的这一篇《The Illustrated Transformer》,非常清楚。
另外,为什么不把self attention放在上一节一起讲,而是单独拆出来,是因为虽然同样叫做attention,在用户行为序列建模,两者的作用是不一样的。
在target/user/context attention中的作用是,引入target/user/context信息对行为序列中的item做一个加权求和。而self attention的可以并行的建模长序列依赖,作用是去除用户行为序列中的噪声。


使用transformer/multi-head attnention/self attention建模用户行为序列的工作现在也有很多,推荐《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》,这篇文章有个小福利是附带了很多调参技巧。
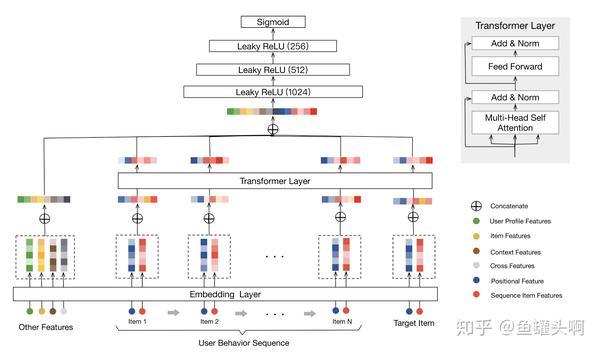
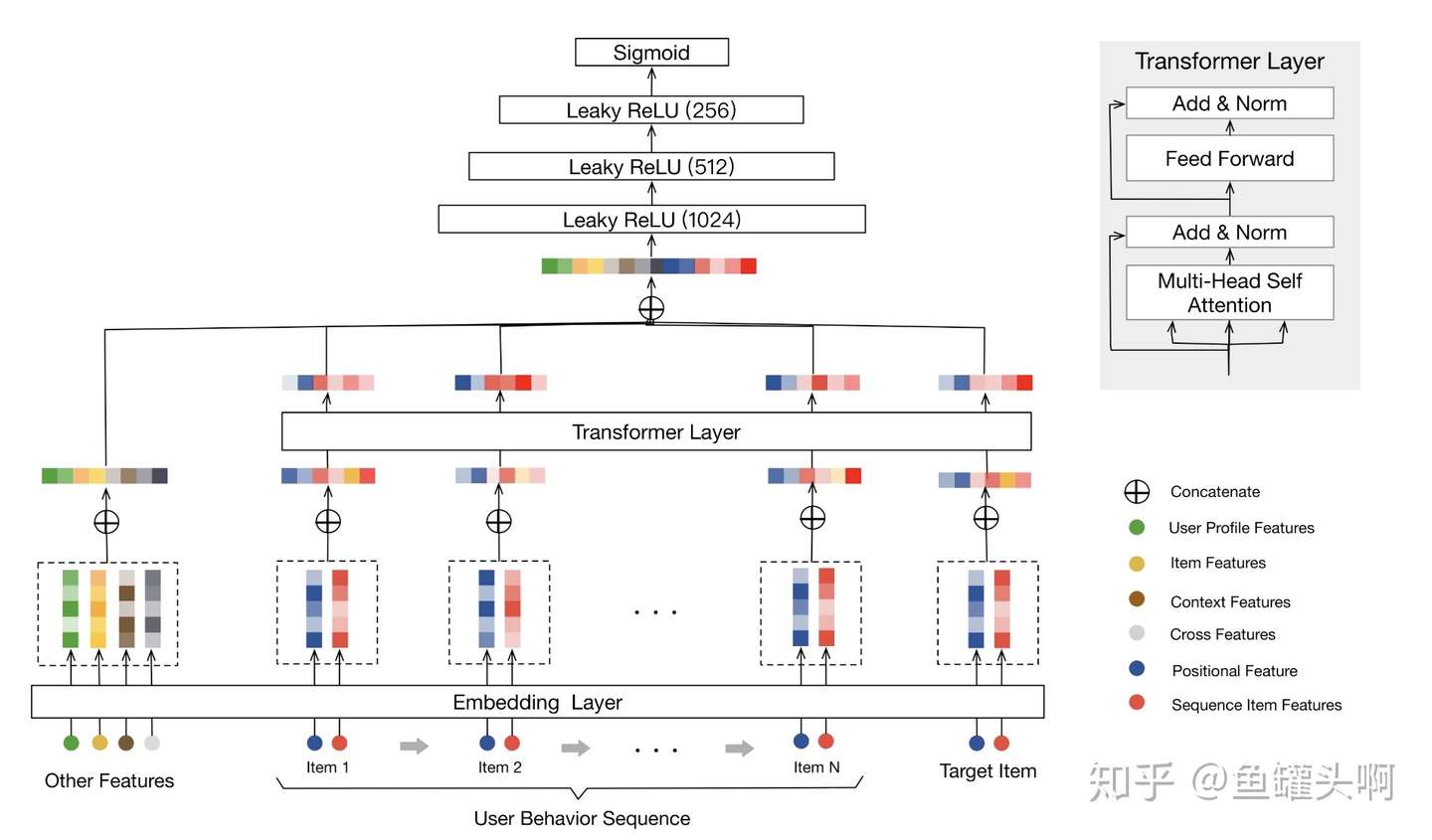
另外,美团近些天放出了《Transformer 在美团搜索排序中的实践》,里面贴出了美团在应用transformer时用的方法、碰到的困难、获得提升的方式。非常推荐(我想起了我用transformer没效果的那阵子...)。
插句话,这大概就是做推荐系统真实的样子了。各路paper只会告诉你他们做出了很好的效果,各种SOTA。但是到你自己用过的时候,往往是没效果,不排除业务/数据/调参差异会导致效果不同,也有很大部分是这些paper在扯淡,根本不能上线。
这个时候不要怀疑人生,因为人生的确就是这样荒诞...多知道一些积木,套路换一换说不定就有效果了^^。
RNN/LSTM/GRU方法
下面介绍RNN/LSTM/GRU类方法,这类方法将用户行为看做一个序列,套用NLP领域常用的RNN/LSTM/GRU方法来进行建模。
可以参考的论文有GRU4REC,将seesion中点击item的行为看做一个序列,使用GRU进行刻画。知乎上有作者的亲自解读,这里不再重复。
白婷:推荐中的序列化建模:Session-based neural recommendationzhuanlan.zhihu.com
另外一篇使用RNN类方法建模用户行为序列的文章是《Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks》,出品于阿里搜索。比较有意思的是这篇paper提出了一种Property Gated LSTM方法。
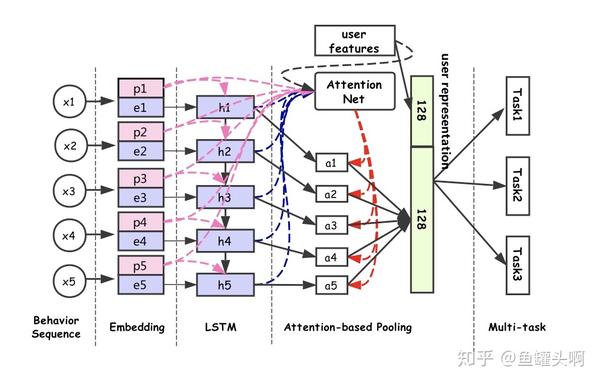
其通过多任务学习的方式学到一个较为通用的用户表征。具体来说,模型将用户行为序列中的每个行为xi分成商品信息item_i(item id、shop id、brand id)和行为属性property_i(场景、时间等上下文),经过embedding层得到embedding后,经过一个Property Gated LSTM层后,得到每个行为节点的隐状态,使用attention网络对隐状态进行加权,然后和user profile feature concat后作为输出。
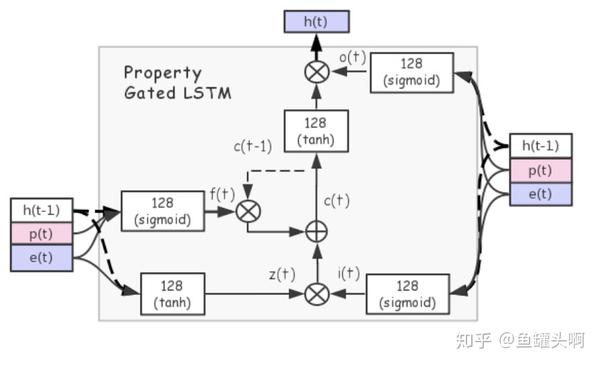
Property Gated LSTM相对普通LSTM有什么改动呢?对于输入门、遗忘门和输出门,将商品信息和上下文信息都作为输入,但是对于cell状态的更新,只使用商品信息而不使用上下文信息。也就是作者认为,用户行为的上下文信息不应该加入到cell状态的更新中,而只用于门的更新。
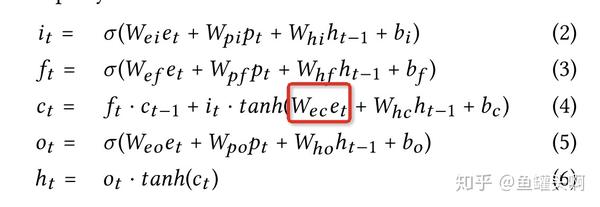
用户多兴趣表达
在前面的方法中,基本上都遵循着这样的范式:将用户行为序列经过pooling/attention/rnn的处理,聚合成一个用户行为序列的embedding,然后加入其它的特征embedding concat后,再经过几层的mlp后作为接sigmode(排序任务)或者softmax/sampled softmax(召回任务)。
事实上,用户行为序列里,通常包含着用户的多峰兴趣。每个用户的历史行为长度不一样,用户的兴趣数量也不同,能不能将用户行为抽取/聚合成多个中兴趣,并且表示为不同的embeding呢?
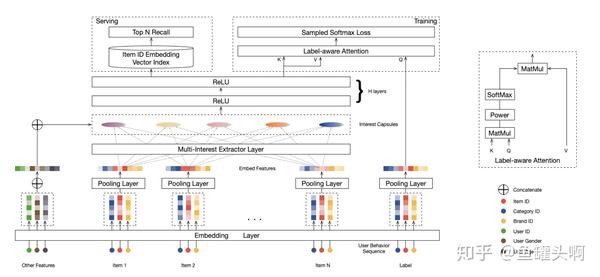
阿里首猜推荐团队在2019年提出的MIND方法,巧妙的使用胶囊网络中的动态路由算法,将底层的用户行为序列作为”vector in",上层“vector out”的胶囊作为用户多峰兴趣。

动态路由具体算法见上图。路由系数 的计算需要使用到上层胶囊的输出
,而
的计算反过来又需要
,因此这里通过迭代的方式,首先初始化路由系数
,一步步迭代得到
,最终得到上层胶囊的输出
。
关于胶囊网络的背景知识,可以看下苏剑林的三篇博客,揭开迷雾,来一顿美味的Capsule盛宴,再来一顿贺岁宴:从K-Means到Capsule,三味Capsule:矩阵Capsule与EM路由。知乎上也有比较多的讨论,大家有兴趣可以看一下。
这里稍微提一下,MIND中比较有意思的一些点,是不管用什么方式抽取多兴趣都可以借鉴的。第一是MIND中的兴趣数量是自适应的,作者设置了K个兴趣上限,然根据用户行为数量 来调整实际抽取出的兴趣数量。
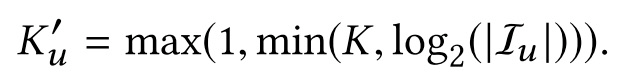
第二点,是作者使用了Label-aware Attention Layer,训练时,将用户下一个点击的item作为query,而不同的用户兴趣作为key和value,做一个attention,并且可以通过超参p来对attention分布进行控制。而在线上,每个用户兴趣向量分开进行召回。
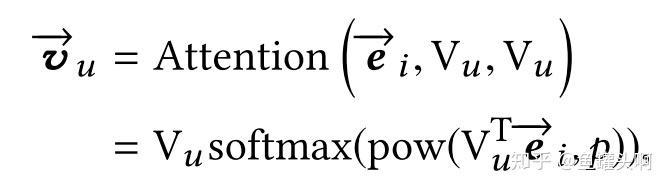
辅助损失函数
在DIN的基础上,2018年阿里妈妈发表了DIEN,它将网络分为兴趣提取层和兴趣演化层。其用户行为特征在得到embedding后,首先经过一个兴趣提取层(GRU),得到兴趣表达 ,然后将兴趣表达经过一个兴趣演化层,具体操作为将兴趣表达
和target item进行一个attention操作后,将attention score代入到第二层GRU的更新门中,控制门的更新,以最后一个hidden state作为用户兴趣表达。
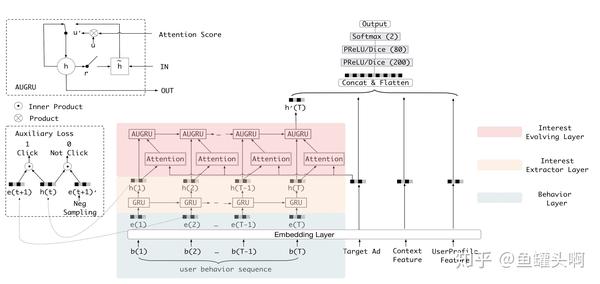
其实,大家可以看到,DIEN中同样涉及到了GRU和attention操作,甚至使用了两层的gru,为什么拿到辅助损失函数这一块来讲呢?因为用RNN/GRU/LSTM建模用户行为序列的论文还挺好找的,辅助损失函数的相对少一些..
在兴趣提取模块,作者在每个time stap引入了辅助loss来刻画每个兴趣的隐状态 ,要求
,其中
是
对应的embedding,
是i+1时刻随机采样未发生行为对应的embedding。f(x)可以是一个全连接函数,然后加入到辅助函数中进行优化。
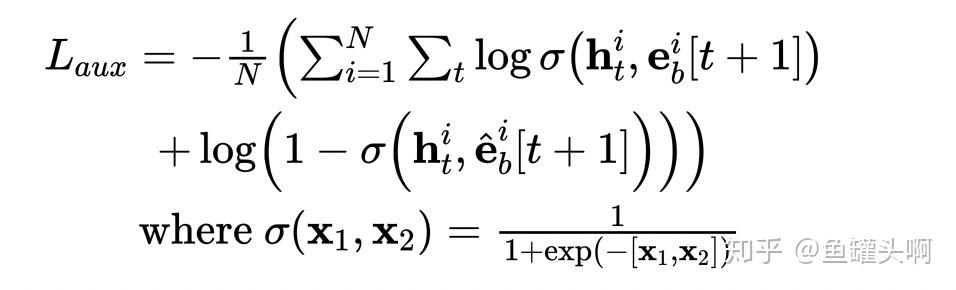
至于为什么要加辅助函数,以及辅助函数为什么有效。作者的表述为若没有辅助loss,GRU的各个隐变量完全受限于最终的点击label,加入辅助loss,能够更好的约束GRU每个隐状态表示好其本身的兴趣。
其他
上文提到了用户行为序列建模中常用到的一些积木,像attention、gru/lstm基本上已经成为标配,暴力尝试组合就常常会有效果,我将之称为通用的积木。
但另一方面,我们在做推荐系统时,面临不同业务场景,不同优化的阶段,常常面临不同的问题,这时候也有一些有趣的解法。
例如,在电商推荐中,我们看用户行为序列的case时,发现用户的兴趣常常可以按照session来进行切割,DSIN这篇论文发现了这一点,将用户行为序列按照30分钟的间隔进行切割。
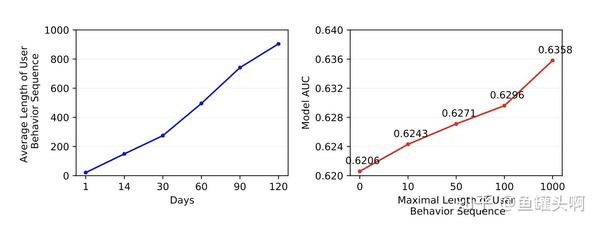
例如,阿里妈妈定向广告团队发现仅仅提升用户序列的长度,就可以带来可观的auc提升,为了建模超长行为序列,提出MIMN,设计了UIC(User Interest Center)模块,将用户兴趣表达模块单独进行拆分而不是每次请求进行计算。
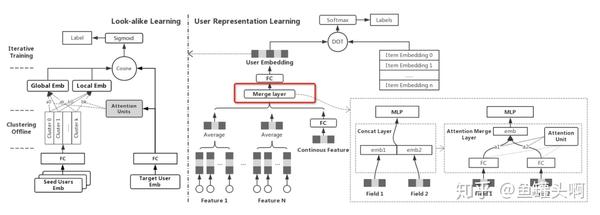
例如,微信看一看召回中,存在多种异构行为序列的信息可以利用(比如可以用腾讯新闻、电商购物行为等等)。作者得到特征域的用户行为序列表达后,使用attention的方法替换concat的方法,动态调整不同领域的融合权重。
写在最后
呼...又是一篇长文,贴图贴公式还是蛮累的。
本文尝试将用户行为建模中的常见的“积木”进行区分,形成一个大致的框架,便于自由组建“乐高”。但限于水平有限,表达能力有限,错漏之处难免,请大家交流指正。
觉得写得好的话,也希望点个赞点个关注^^
想尝试下阿里工作机会的话,可以私信勾搭^^
Recommend
-
61
关于序列建模,是时候抛弃RNN和LSTM了
-
34
在过去几年中,虽然循环神经网络曾经一枝独秀,但现在自回归 Wavenet 或 Transformer 等模型在各种序列建模任务中正取代 RNN。机器之心在 GitHub 项目中曾介绍用于序列建模的 RNN 与 CNN,也介绍过不使用这两种网络的 Transforme...
-
17
文章作者:汪剑 出门问问 算法工程师 编辑整理:Hoh Xil 内容来源:作者原创分享 文章出品:DataFunTalk 注:欢迎...
-
12
浏览器指纹及用户行为智能推荐简介 2021年1月17日 87次浏览 我们在浏览抖音等,抖音会根据你的浏览行为,计算出你个人喜好,然后智能推荐给你喜好的信息。我们在网站上浏览了某个商品,了解了相关的商品信息,但并没有下单购...
-
19
P5 | NLP模型一统推荐系统? 谈新型推荐系统建模范式 AINLP...
-
5
Jiayue Cai's Blog Last updated on 2020-06-08… 本篇整理自
-
3
作者 | 郑智献行为序列模型相对于传统机器学习的主要优势在于不依赖行为画像特征,无需强专家经验挖掘高效特征来提升模型性能,缩短了特征工程的周期,能快速响应黑产攻击。黑产通过刷接口、群控、真人众包等作弊手段在关注、点赞、评论等核心场景进行攻击。...
-
1
行为序列模型相对于传统机器学习的主要优势在于不依赖行为画像特征,无需强专家经验挖掘高效特征来提升模型性能,缩短了特征工程的周期,能快速响应黑产攻击。 黑产通过刷接口、群控、真人众包等作弊手段在关注、点赞、评论等核心场景进行攻击。不同作弊方式...
-
6
谈谈阻碍数据建模的五大借口 作者:晓晓 2022-11-23 16:36:34 大数据 随着大数据和数据湖的发展,数据建模似乎濒临灭亡。数据湖的开发者...
-
8
谈谈数据仓库中的数据建模优秀实践 作者:晓晓 2023-10-08 16:26:23 开发和生成数据库中使用的数据概念表示的过程称为数据建模。数据仓库上下文中的数据建模是创建将存储在数据仓库中的数据的逻辑表示的过程。
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK