
8

生产问题(3) 应用开发过程中的海恩法则
source link: https://blog.duval.top/2021/02/09/%E7%94%9F%E4%BA%A7%E9%97%AE%E9%A2%98-3-%E5%BA%94%E7%94%A8%E5%BC%80%E5%8F%91%E8%BF%87%E7%A8%8B%E4%B8%AD%E7%9A%84%E6%B5%B7%E6%81%A9%E6%B3%95%E5%88%99/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
生产问题(3) 应用开发过程中的海恩法则
海恩法则,是航空界关于飞行安全的法则。海恩法则指出: 每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。
最近在生产上遇到一个应用案例,正好完美体现了海恩法则的价值!
北京时间晚上十点半美股开盘后,某板块的数据却没有更新。所有的相关人员都没有提前收到告警,直到事故发生后,开发才紧急介入恢复。开发接入后,先紧急重启服务无法恢复;于是紧急切换到热备服务,才恢复成功。
该事故持续了超过30分钟,导致所有用户无法查看该板块数据,也无法提交订单。该事故影响非常恶劣,其定级考虑为灾难级别事故。
每个严重事故背后都是多次轻微事故,我们来按照时间顺序,理清楚背后发生的事情:
网络抖动:下午六点许,机房A与机房B之间的网络发生了一次轻微抖动,导致机房A内的数据处理服务P与机房B的数据源S之间的 TCP 连接发生假死断开;
业务缺陷:机房A内部的数据处理服务P存在缺陷,并没有实现心跳检查并自动重连的功能;
运维缺陷:数据处理服务P内部监控模块检测到连接异常,并发出告警。但告警地址没有添加机器白名单,告警信息被503错误拦截;
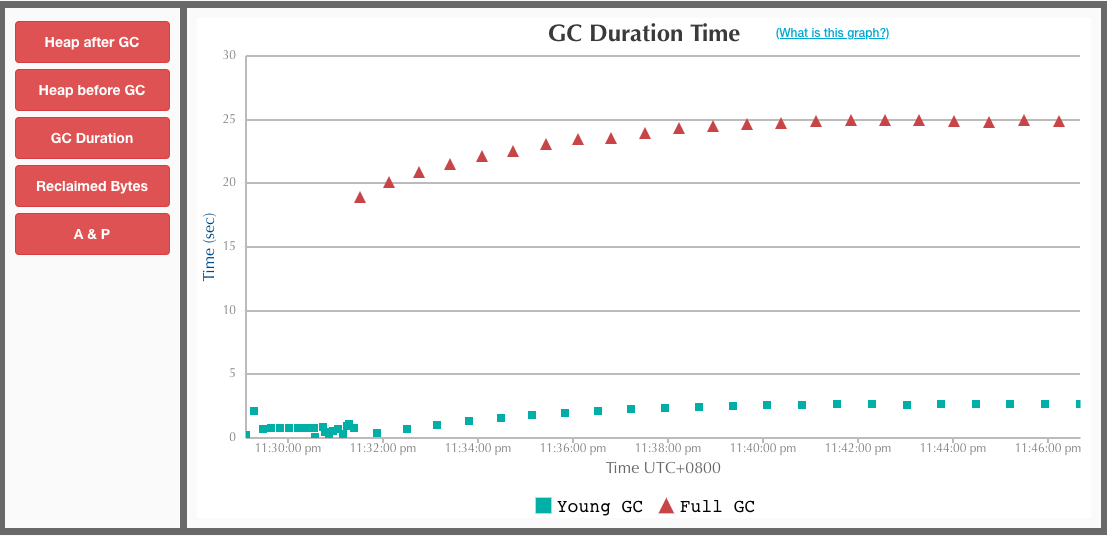
业务缺陷:数据处理服务P启动后预热数据量过大,盘中上游推送数据量也非常大。这导致 JVM 压力非常巨大,大量对象迅速进入老年代,服务无法在盘中重启成功。盘中重启后的GC情况如下图所示,可以看到 JVM(CMS,12G堆,新生代5G,8:1) 在重启两分钟后迅速崩溃掉:
- 服务健壮性:业务逻辑要强制实现心跳检测、失活重连这种基本功能;
- 监控告警:核心服务需要完备的监控和告警,并且对各机房的监控告警要充分测试,确保紧急时候能够得到响应;
- 备点服务方案:核心服务不能允许只有一套,必须有备点服务,用于紧急情况下的切换;
- 高可用快速切换:尽量确保服务在故障情况下能够自动切换到备用服务,如果无法实现自动切换,需要确保有快速手动切换的方案。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK