

Performance of sys.partitions
source link: https://sqlperformance.com/2021/01/sql-performance/sys-partitions
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Performance of sys.partitions
This question was posted to #sqlhelp by Jake Manske, and it was brought to my attention by Erik Darling.
I don't recall ever having a performance issue with sys.partitions. My initial thought (echoed by Joey D'Antoni) was that a filter on the data_compression column should avoid the redundant scan, and reduce query runtime by about half. However, this predicate doesn't get pushed down, and the reason why takes a bit of unpacking.
Why is sys.partitions slow?
If you look at the definition for sys.partitions, it is basically what Jake described – a UNION ALL of all the columnstore and rowstore partitions, with THREE explicit references to sys.sysrowsets (abbreviated source here):
CREATE VIEW sys.partitions AS
WITH partitions_columnstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 1 -- Consider only columnstore base indexes
),
partitions_rowstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 0 -- Ignore columnstore base indexes and orphaned rows.
)
SELECT ...cols...
from partitions_rowstore p OUTER APPLY OpenRowset(TABLE ALUCOUNT, p.partition_id, 0, 0, p.object_id) ct
union all
SELECT ...cols...
FROM partitions_columnstore as P1
LEFT JOIN
(SELECT ...cols...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
------- *** ^^^^^^^^^^^^^^ ***
) ...This view seems cobbled together, probably due to backward compatibility concerns. It could surely be rewritten to be more efficient, particularly to only reference the sys.sysrowsets and TABLE ALUCOUNT objects once. But there's not much you or I can do about that right now.
The column cmprlevel comes from sys.sysrowsets (an alias prefix on the column reference would have been helpful). You would hope that a predicate against a column there would logically happen before any OUTER APPLY and could prevent one of the scans, but that's not what happens. Running the following simple query:
SELECT * FROM sys.partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Yields the following plan when there are columnstore indexes in the databases (click to enlarge):
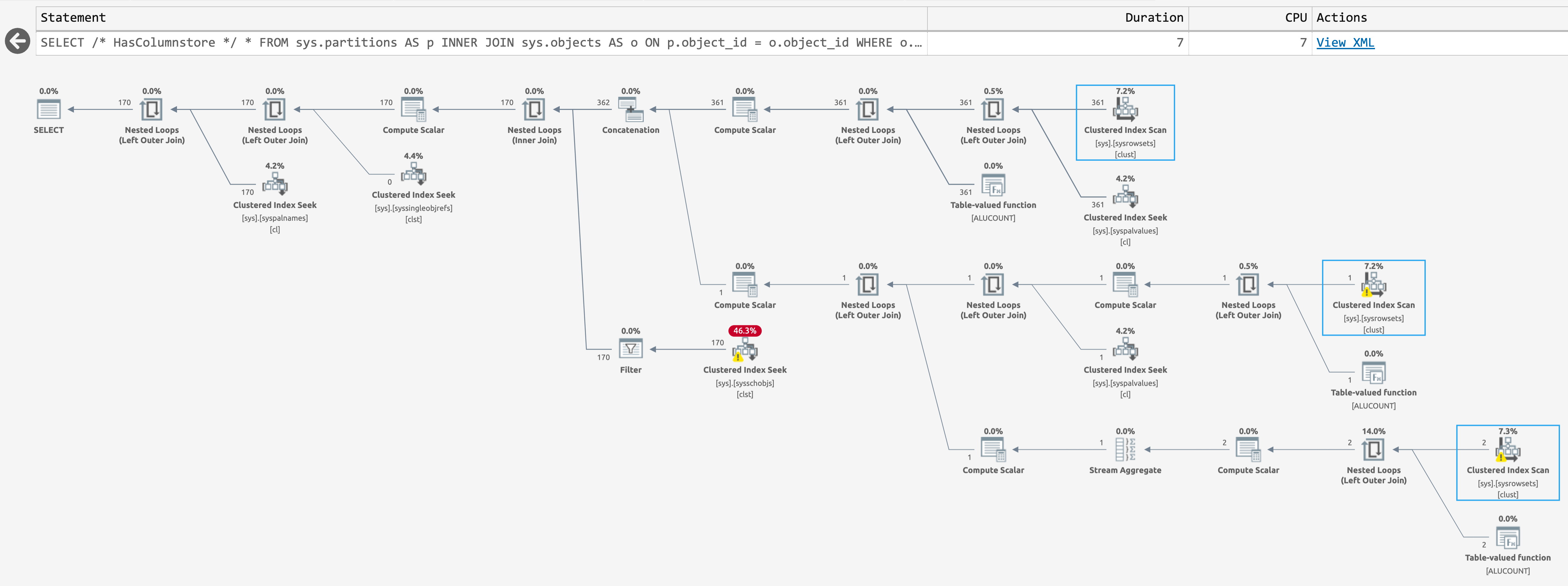{kind=link}
Plan for sys.partitions, with columnstore indexes present
And the following plan when there are not (click to enlarge):
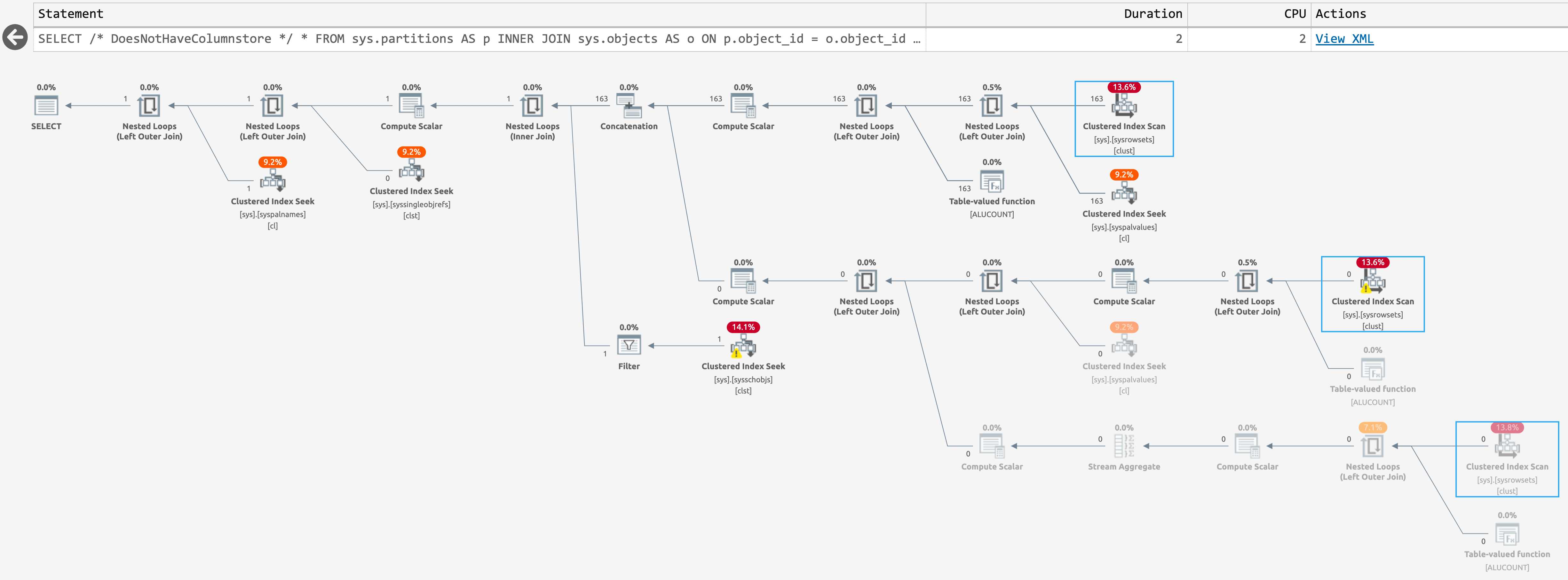{kind=link}
Plan for sys.partitions, with no columnstore indexes present
These are the same estimated plan, but SentryOne Plan Explorer is able to highlight when an operation is skipped at runtime. This happens for the third scan in the latter case, but I don't know that there's any way to reduce that runtime scan count further; the second scan happens even when the query returns zero rows.
In Jake's case, he has a lot of objects, so performing this scan even twice is noticeable, painful, and one time too many. And quite honestly I don't know if TABLE ALUCOUNT, an internal and undocumented loopback call, has to also scan some of these bigger objects multiple times.
Looking back at the source, I wondered if there was any other predicate that could be passed to the view that could coerce the plan shape, but I really don't think there's anything that could have an impact.
Will another view work?
We could, however, try a different view altogether. I looked for other views that contained references to both sys.sysrowsets and ALUCOUNT, and there are multiple that show up in the list, but only two are promising: sys.internal_partitions and sys.system_internals_partitions.
sys.internal_partitions
I tried sys.internal_partitions first:
SELECT * FROM sys.internal_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
But the plan was not much better (click to enlarge):
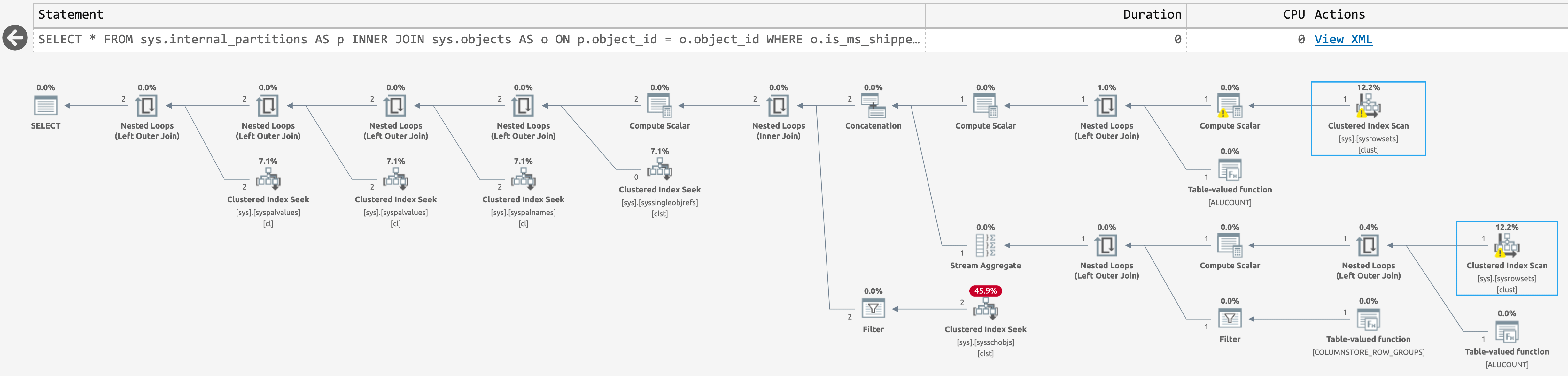{kind=link}
Plan for sys.internal_partitions
There are only two scans against sys.sysrowsets this time, but the scans are irrelevant anyway because the query doesn't come close to producing the rows we're interested in. We only see rows for columnstore-related objects (as the documentation states).
sys.system_internals_partitions
Let's try sys.system_internals_partitions. I'm little wary about this, because it's unsupported (see the warning here), but bear with me a moment:
SELECT * FROM sys.system_internals_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
In the database with columnstore indexes, there's a scan against sys.sysschobjs, but now only one scan against sys.sysrowsets (click to enlarge):
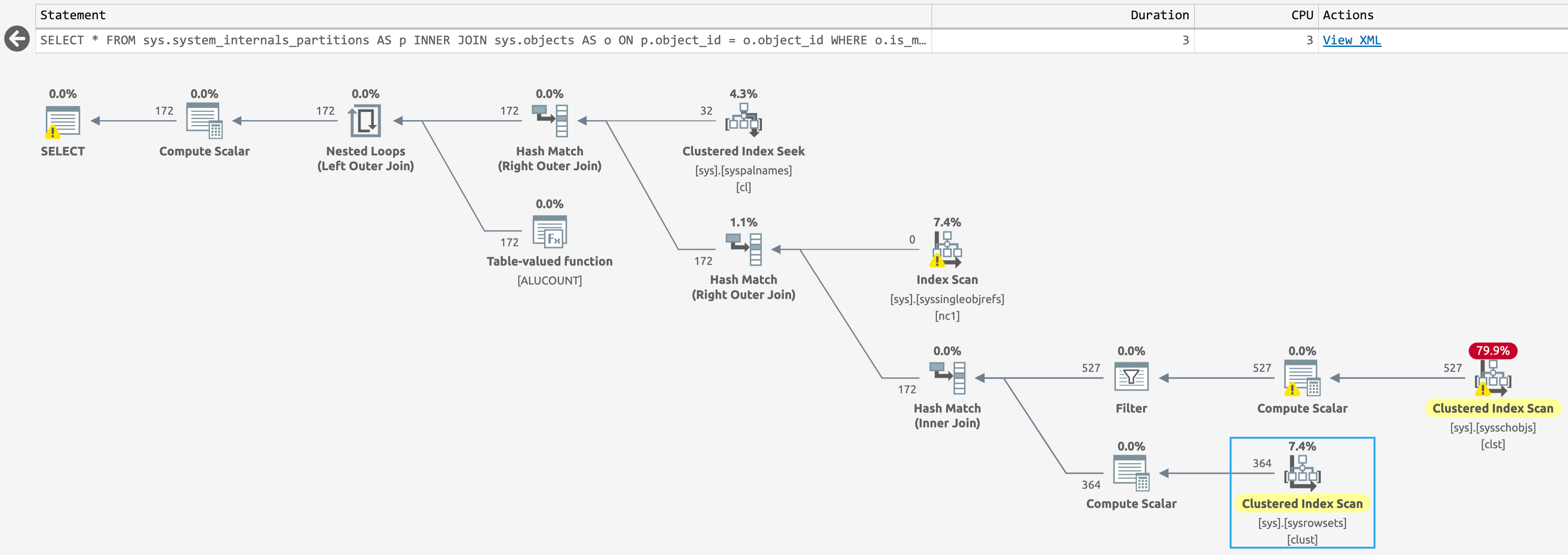{kind=link}
Plan for sys.system_internals_partitions, with columnstore indexes present
If we run the same query in the database with no columnstore indexes, the plan is even simpler, with a seek against sys.sysschobjs (click to enlarge):
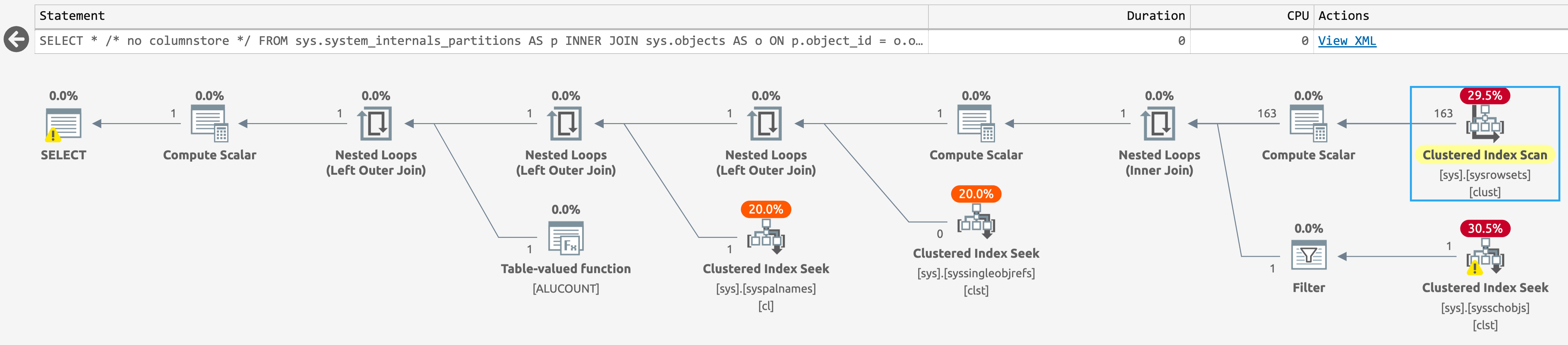{kind=link}
Plan for sys.system_internals_partitions, with no columnstore indexes present
However, this isn't quite what we're after, or at least not quite what Jake was after, because it includes artifacts from columnstore indexes, as well. If we add these filters, the actual output now matches our earlier, much more expensive query:
SELECT *
FROM sys.system_internals_partitions AS p
INNER JOIN sys.objects AS o ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0
AND p.is_columnstore = 0
AND p.is_orphaned = 0;As a bonus, the scan against sys.sysschobjs has become a seek even in the database with columnstore objects. Most of us won't notice that difference, but if you're in a scenario like Jake's, you just might (click to enlarge):
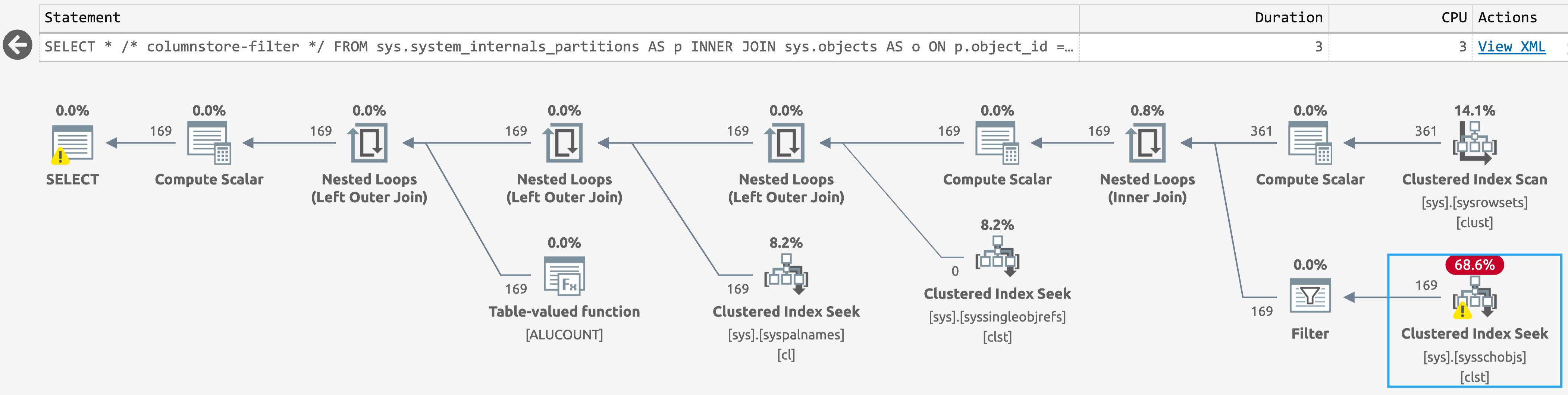{kind=link}
Simpler plan for sys.system_internals_partitions, with additional filters
sys.system_internals_partitions exposes a different set of columns than sys.partitions (some are completely different, others have new names) so, if you are consuming the output downstream, you'll have to adjust for those. You'll also want to validate that it returns all of the information you want across rowstore, memory-optimized, and columnstore indexes, and don't forget about those pesky heaps. And, finally, be ready for leaving out the s in internals many, many times.
Conclusion
As I mentioned above, this system view is not officially supported, so its functionality may change at any time; it could also be moved under the Dedicated Administrator Connection (DAC), or removed from the product altogether. Feel free to use this approach if sys.partitions is not working well for you but, please, make sure you have a backup plan. And make sure it is documented as something you regression test when you start testing future versions of SQL Server, or after you upgrade, just in case.
Recommend
-
56
WhenAndroid Nougat released, it had us talking about all kinds of new features . We got a newly updated user interface for...
-
50
Redshift unload is the fastest way to export the data from Redshift cluster. In BigData world, generally people use the data in S3 for DataLake. So its important that we need to make sure the data in S3 should be partition...
-
63
README.md Partition Kit I am currenty unemployed and have received no responses to any of my applications, I would like to continue making li...
-
28
MySQL Group Replication allows you to create an highly-available replication group of servers with minimum effort. It provides automated mechanisms to detect and respond to failures in the members of the group. The respons...
-
13
Partial network partitions and obstacles to innovation Imagine a big network with a bunch of hosts on it. Maybe you break them up by logical groupings, like racks, or groups of racks. You give each group separate address space,...
-
7
Co-locating Spark Partitions with HBase Regions Nov 7, 2016 | HBase scans can be accelerated if they start and stop on a single region server. IO costs can be reduced further if the scan is execut...
-
19
Adding, extending, and removing Linux disks and partitions in 2019 Managing disks and partitions in Linux has changed quite a bit over time. Unfortunately, as Jonathan Frappier points o...
-
9
For some reason I cannot join partitions in to one single partition P ...
-
8
[C++20] Module partitions和符号交叉引用(声明和实现分离)C++20 开始支持 Module 了。在以前C++为了解决循环依赖问题,经常会把类或者函数声明写前面,实现写后面。然后中...
-
8
NAKIVO Blog > VMware Administration and Backup >
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK