

淘宝前端在搭建服务上的探索
source link: https://zhuanlan.zhihu.com/p/137470317
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
淘宝前端在搭建服务上的探索
搭建在互联网技术领域算是一个非常宽泛的概念,从早期大部分人都有接触过的 wordpress 个人网站搭建,到一些文章类 CMS 系统的图文编排搭建,再到更复杂的 UI 搭建,特别是 React/Vue 出现后,从框架层面也提供了很多包括视图结构化(vdom),视图和数据关联(数据绑定)等等能力,把原本非常复杂的搭建画布进行了简化。
在淘宝,2008年的时候就已经有了第一个搭建系统 TMS(Template Management System),当时的设计也非常大地影响了接下来十几年的搭建体系设计。
这些设计包括了:
- 前端操作和运营操作分离
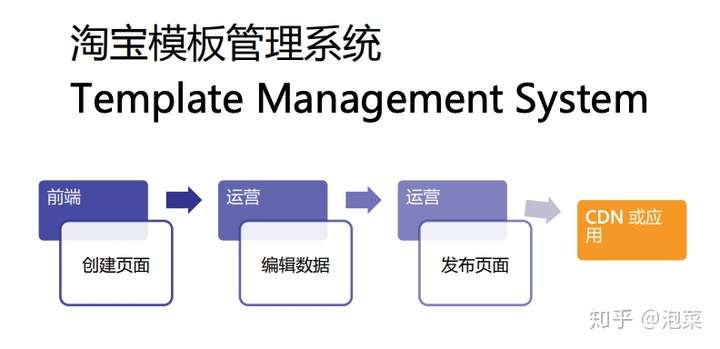
- 基于模板的数据挖坑
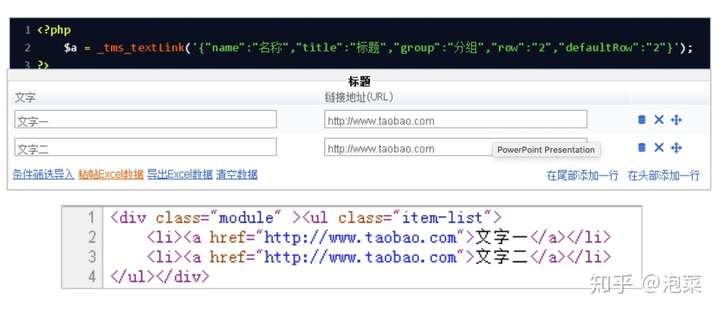
- 页面渲染的抽象
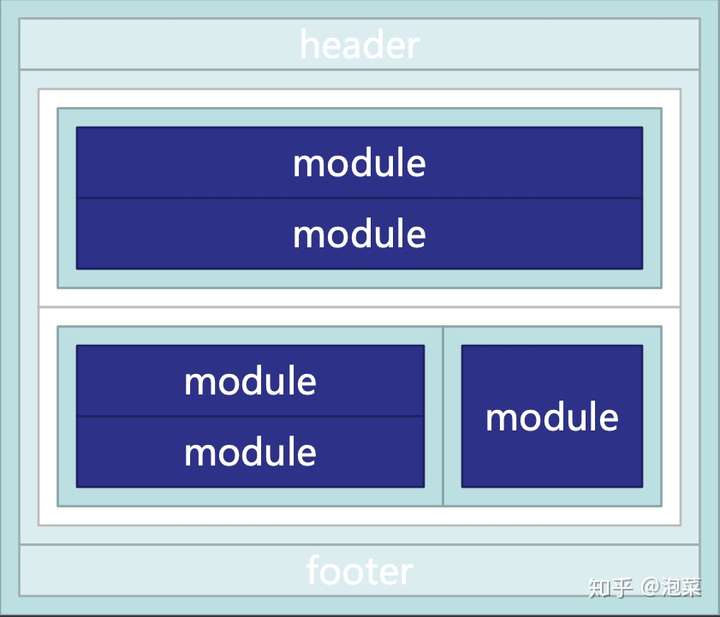
从上面的页面抽象看,还是有非常多 PC 时代的影子,随着公司的战略调整,无线化、个性化的发展,搭建系统也随着一起拥抱变化,衍生出了各个面向不同场景、诉求的搭建应用,背后必然也意味着非常多的重复建设。在2019年,随着淘宝、天猫技术部的合并,最终在阿里前端委员会的支持下,启动了搭建技术方向,从减少重复建设,提升业务互通的角度,进行搭建应用/服务分层的抽象,天马也作为经济体搭建域的统一服务,然后各个 BU、业务都可以基于统一的服务和规范,建设贴合自己业务的搭建系统。
天马在上个财年完成了十几个 BU 的接入和搭建支持,整体产出了上万个模块,发布了上百万张页面,覆盖了3万+阿里运营及几十万的商家。
搭建的名词与概念
搭建是一个多角色复合参与的流程,这是搭建和其他技术方向差异比较大的地方。所以设计搭建的时候,需要先明确重点用户是谁,需要围绕什么角色来设计流程。
为了帮助大家能够更好地理解后面的内容,首先把一些名词做一下对齐:
- 模块:非技术同学搭建页面依赖的最小单位
- 页面搭建:从模块到页面的组合过程
- 数据投放:数据的变化频率远高于页面,所以单独提取出数据投放的概念
- 终端:目标运行环境
搭建的设计
无论在几年前的 PC 时代,还是现在的无线时代,业务的运作是离不开纷繁复杂的页面制作的,比如淘宝,从早期不同的行业类目,到现在的不同的导购营销方式,背后都是需要制作大量的页面支撑。
整个页面制作过程,经过抽象。主要是包含几个步骤:
这些步骤应该是可以由运营独立完成,不需要研发同学介入的。重点讲下设置、搭建、投放三个步骤。
- 设置页面:页面标题、keywords、description 之类的可能会影响到 html 文档直接变化的设置
- 搭建页面:页面结构的调整,添加模块、删除模块、交互模块位置等等
- 投放数据:针对单个、多个模块进行数据设置
这些能力背后就是对页面、模块、数据的抽象方式,决定了一个搭建的物料应该如何设计。
当然这些流程只是一个顺序,不代表这些操作必须人工进行,即使是自动化生产和搭建页面,背后系统的流程也是类似的。
搭建核心物料—模块
模块是天马定义的页面搭建最小单位,页面由模块组成,模块可以和数据进行关联。
天马的搭建模块有几个核心的设计原则:
- 面向标准数据研发
在前面介绍 TMS 的时候,有介绍 TMS 是如何设计页面渲染的,除了上下模块搭建之外,还提供了横向的模块搭建能力,当时也叫做栅格模块。
但天马对这部分进行了简化,只支持了从上到下积木式搭建的能力,也就是一维扁平的模块结构。
积木式搭建对应到页面就是如下图:
为什么对这部分进行简化呢?
- 对运营友好:从运营同学作为搭建主要用户的角度来思考,以及无线化场景下,手机屏幕的特征,一维存储的模块列表是比较友好的。这个设计也对搭建服务本身带来了很大的简化,整个页面结构就是一维数组,每次操作都可以转变成一次简单的数组操作。当然,一维的存储不代表一维的展示,开发者依然可以在展示的时候,通过一些父子关系,来把一维的存储结构转变为树状结构。目前我们是判断把复杂度给开发者,简单的操作给到非技术同学,还是一个比较合适的方式。
- 方便建立多端对应关系:因为无线化,公司在无线上的投入比桌面端大很多(主要是消费者侧),那么如果能搭建无线页面,然后桌面端自动生成,或者反一下,对搭建用户来说可以省掉很多时间。特别是当下极端一些的场景,用户搭建一个无线端页面,需要同时额外生成 pc、weex、小程序的版本。一维存储的模块结构可以较好地建立不同终端页面模块的对应关系。
- 方便建立服务端与模块的关系:因为算法的普及,页面的个性化不局限于某个商品模块内部,而是不同人群访问同个页面,整个页面的顺序都有可能因为个性化而调整。那么对于后端算法来说,就需要感知到页面结构,并和后端的算法模型进行关联。一维的结构对于这部分还是非常友好的
最早在12年的时候,天猫就已经有了跨终端的概念。如前面的概念定义,这里不严格定义来区分终端、容器等等,先用比较简单的概念,称为终端,也就是目标的运行环境。终端包括桌面版 chrome、移动端 safari、tv盒子的 UC 浏览器、手机淘宝的 webview/weex 容器、支付宝小程序容器甚至到服务端的 ssr 渲染引擎等等。
为什么不用响应式?响应式只是跨终端的一种解决方案,响应式解决不了代码运行在服务端的问题,并且响应式本身也过于注重效率,而不是去面对本质上的差异。
http://weixin.qq.com/r/IHXv4C-EshHNhz6DnyAE (二维码自动识别)
比如图里的导航模块,无线端是一个 tab ,而在桌面端是一个随屏滚动且悬浮的模块,这是一个交互差异的案例,而实际上,更多还有内容、业务逻辑上的差异,所以不必拘泥于响应式,该写两套逻辑就写。
当然,跨终端是模块的能力,如果我的模块就是只面向一个端服务,就可以只写一个端。
实际的情况会更复杂一些,目前淘系选择了 Rax 作为统一 DSL,基于上面的搭建设计,加上 Rax 本身一次开发多端运行的能力,就可以实现我只需要写一份无线端 web 的代码,分别转出 weex、小程序的版本,这样我的模块投放到 webview 里就是 web 模式,投放到小程序里就是原生小程序,投放到 weex 就可以以 weex 形式渲染。所以一个模块发布后,会同时同步到 CDN 和 npm 上,CDN 版本给到纯浏览器和服务端使用,tnpm 部分给到小程序和源码页面等其他有页面级构建能力的场景使用。
面向标准数据研发
这个原则比较容易让人困扰,但实际上,大家在日常研发中,或多或少都在做着相关的事情,比如如何校验一个表单,如何和后端一起定义一个新的数据接口,以及现在比较流行的 TypeScript 也是在定义数据格式。我们把这个原则分成两个部分:
- 面向数据研发
- 数据标准化
数据格式就是一个符合 JSON schema 规范的 schema.json 数据描述,来描述模块接受哪些入参,也就是模块面向什么数据研发。这些入参内部,也做了更多的约定,比如如何让模块能够换肤(和中后台换肤的机制有比较大的差异),如何能够让模块能够接受一些配置,以及如何给模块传递核心渲染需要的数据。
而标准化的数据格式通过先定义数据模型,然后模块尽可能去引用已有的数据模型,解决开发者都是写同一个商品模块,字段却不同的问题。否则对于后端来说,得做一套非常复杂的系统来把同样的商品数据塞到不同的模块里,同时还要适配各个模块不同的字段定义。通常后端同学也不会愿意做这个事情。
这些设计背后也就是我们期望开发者研发模块时尽量脱离业务场景,尽量少的与特定的后端接口交互,把模块写的更像一个纯做渲染的组件,这样模块的流通能力才能得到保障。
下面是一个 schema.json 的案例:
{
"type": "object",
"properties": {
"$attr": {
"type": "object",
"properties": {
"hidden": {
"type": "boolean"
}
}
},
"$theme": {
"type": "object",
"properties": {
"themeColor": {
"type": "string"
}
}
},
"items": {
"type": "array",
"items": {
"type": "object",
"properties": {
“itemId”: {
"type": "string"
}
}
}
}
}
}而那些和业务场景相关的逻辑,就放到页面级处理,不同的页面可以共享一套页面初始化逻辑。
数据标准化
继续展开讲面向标准数据研发,因为搭建本身的特殊性,以及模块对应的数据不会只是简单的进行表单投放,特别是在千人千面、个性化普及的今天,大部分模块背后,不仅仅是静态数据,而是一些动态数据服务,这些接口可能会来自于公司大大小小各种不同的系统。对于模块开发者而言,我定义的数据描述应该面向哪个接口?同样都是商品接口,A应用和B应用接口返回的字段,一个是下划线风格,一个是驼峰怎么办。
数据标准化解决的就是这个问题,我们应该面向一个标准的数据进行研发。这个标准数据就是基于目前最底层的这些系统,商品库、用户库等等,统一命名规范后的结果。大家都遵守这个规范来给模块传递数据就可以了。
但实际情况比这个还要复杂,比如有一个模块,有一行文字描述,部分场景下显示的是商品标题,部分场景下显示的是商家写的宣传文案,UI 本身是有二义性的。这个时候,我们在数据描述里就会定义一个叫 title 的字段,具体这个 title 对应实际是 itemTitle 还是 itemDescription,就要看实际的场景。
最后也就是说一个面向搭建域的数据接口,给到前端渲染前,实际可能会经过两次标准化,一次领域模型的标准化,确保字段是没有二义性的,然后再是一次VO的标准化,再基于视图的需求,映射到可能有二义性的模块展示上。
通常我们会要求后端同学来做好领域模型的标准化,然后前端在 FaaS 或者维护一个类似网关的应用进行视图模型的标准化。当然也可以前端直接从数据源直接映射到 UI 模型,只是抽象的层次不同。
如何编写一个模块
前面有提到,我们还是比较推荐模块只是做渲染,尽量少的和特定的场景绑定。那么简化一下模块开发,就是:
- 定义我需要什么格式的数据
- 准备好一份 mock 数据
- 写一段逻辑,输入 mock 数据,返回渲染结果
听起来很像是一个传统函数的定义了。
以下是一个 rax 模块的范例:
import { createElement } from 'rax';
import View from 'rax-view';
import Text from 'rax-text';
export default function Mod(props) {
let defaultTheme = {
themeColor: '#fff'
};
let defaultAttr = {
hidden: false
};
let {
items = [],
$theme: {themeColor} = defaultTheme,
$attr: {hidden} = defaultAttr,
} = props.data;
return (
<View className="mod" style={{
backgroundColor: themeColor
}}>
{
hidden !== 'true' ? <Text>欢迎使用天马模块!</Text> : null
}
<View className="keys">
{
items.map(element => {
return (<Text>{element.key}</Text>);
})
}
</View>
</View>
);
}当然,一定会有部分模块,更复杂,比如有点赞、关注等不只是一次渲染能解决的事情,这部分一方面是可以组件化的,写模块的开发者并不需要关心到这部分逻辑,还是只需要传递一些用户信息给到组件就行。另一角度考虑,如果一个点赞接口就有N份实现,对于后端服务设计来说是不是也有问题,是不是推进统一会更好?
模块研发链路的设计
模块的研发链路其实和正常开发一个 npm 包差别不大,基于很多约定,我们提供了一些便捷的脚手架,以及有支持插件化的构建器,可以提供给各种不同但有限的 DSL 模块进行构建操作。
同时由于开发者有 ISV、外包、内部员工,可视化研发还是非常重要的环节,尽量把哪些和开发一个 npm 模块有差异的点,都通过可视化研发的方式抹平。我们也提供了包括本地模块管理、调试、预览、schema 编辑器等能力,以及代码扫描、资源存储等发布流程的保障。
如何运行模块
因为服务端也是模块的目标运行环境,目前在服务端运行模块的方式主要有比较老派的纯模板渲染方式(需要开发者单独写一个模板文件用于生成 html),以及现在逐渐普及的 SSR 方案。前者足够简单且有确定性,后者面向未来但是需要有足够多稳定性的保障。
前面也有提到的,为了让模块研发足够简单且保证流通性,页面级需要承担更多包括数据请求、页面容器初始化等操作。
数据请求逻辑是页面逻辑中非常核心的部分,现在会有一些数据驱动 UI 展示的概念,特别是接口合并、分页分屏、容灾打底这些非常重要的功能。分页分屏决定了首屏需要展示哪些内容,请求哪些数据,然后接口合并负责减少请求数,加速首屏展示,然后容灾打底确保最后一定是可以有内容展示给用户,即使有各种网络、服务的问题。
而页面容器渲染,主要还是包括滚动容器的初始化,多维模块列表的渲染。比如把一维的模块列表渲染成多tab的父子关系,以及最后需要单独初始化一个个模块。
搭建的核心设计—依赖去重
上面的大部分内容和中后台搭建还是比较类似,只是各自有一些约定。接下来就是天马的设计中比较有差异的地方了。中后台搭建通常都只需要在 npm 包组件的基础上,加上一个 schema 描述,就可以用于在搭建系统中生成对应的表单配置了,npm 组件会在发布的时候构建到页面 bundle 中。而是消费者端的不行,目前每个模块需要单独进行构建,为什么这么做?
- 某次活动,大概用到了100+的模块,搭建出了1000+的页面。然后有个功能需要在短时间内对特定几个模块进行版本升级操作。如果每个页面都需要构建才能生效,短时间内进行大量构建的可操作性是比较低的,特别是复杂的 webpack 构建耗时还是非常长的。
- 在个性化、千人前面普及后,页面的展示是由数据来驱动的,如果用传统的构建方案,无法准确做到首屏只加载首屏模块,因为首屏本身包含哪个模块不是由 bundle 决定,而是由数据决定的。
数据驱动展现
因为搭建的最小单位是模块,且业务上有大量动态性的要求,比如某一天10点需要升级1000个页面的其中5个模块的版本,把这1000个页面进行重新构建发布操作性较低,所以组装模块的过程是通过线上渲染服务计算 assets combo uri 实现的,只要在操作后台点击一下模块升级,这1000个页面会自动更新模块版本而不需要重新走一次构建逻辑。这也意味着每个模块需要单独打包,给出一个已经可以在浏览器上运行的 web 版本。
但是由于每个模块单独打包,如果啥都不做,会造成依赖重复加载的问题。那么就需要把模块的依赖 dependecies 都 external 掉(也支持主动选择部分打包),为了确保不重复加载依赖模块造成页面大小不可控,引入了 seed 描述依赖的机制。
{
"modules": {
"@ali/pmod-ark-butian-test/index": {
"requires": [
"@ali/rax-pkg-rax/index",
"@ali/rax-pkg-rax-view/index",
"@ali/rax-pkg-rax-text/index"
]
}
},
"packages": {
"@ali/rax-pkg-rax": {
"path": "//g.alicdn.com/rax-pkg/rax/1.0.15/",
},
"@ali/rax-pkg-rax-view": {
"path": "//g.alicdn.com/rax-pkg/rax-view/1.0.1/",
},
"@ali/rax-pkg-rax-text": {
"path": "//g.alicdn.com/rax-pkg/rax-text/1.0.2/",
},
"@ali/pmod-module-test": {
"path": "//g.alicdn.com/pmod/module-test/0.0.9/",
}
}
}光有一个描述肯定不够,核心还需要确定一个策略,模块依赖同个 npm 包的不同版本,应该如何选择。npm 安装的方式是兼容版本取最大,不兼容或者指定版本的时候安装多份的策略。web 上的策略也是类似的,只是内部的研发更可控,所以把这个策略做了更多的简化(以x,y,z版本为例):
- x 位大版本可以共存(也可以选择不共存)
- y,z位版本变化都是向前兼容的,会自动取兼容下的最新,即使指定了版本。
从 web 和用户侧的角度考虑,加载大量同组件的不同版本只会造成页面体积的膨胀,带来带宽、流量的浪费,以及用户侧较差的体验。
本质上,就是把原本 webpack 帮开发者做的内部依赖管理,抽象提取出来,在页面级统一进行管理。
seed 机制与 webpack
seed.json 依赖关系的问题
1. 私有实现带来的理解和构建成本
天马目前的 seed 配置核心问题在于这是一个非常私有的实现,所有组件要进入天马体系并且有去重能力,就得重新构建以此生成 seed。
这个问题在新业务接入天马的时候会比较明显,因为页面级去重能力是基于 seed 配置来的,而 seed 的原始来源是组件内部的 seed.json,也就是说你要先把组件内的 package.json dependencies 转成 seed.json,然后这个组件才能被收集依赖。这也是为什么需要把组件在天马上注册一次,注册的过程也就是生成对应 seed 的过程。目前这个过程是手动引入组件然后提交一份到天马。后续天马模块中心会提供自动注册的能力。
那为什么没有直接根据 package.json 来进行注册的方式呢,毕竟 seed 也是由 package.json dependencies 生成的。
主要原因有两个:
- package.json 里声明的依赖并不一定会用到,还需要读取真实的 import 引用情况
- package.json 里声明的依赖并不一定都是公共依赖,内部依赖就直接打包掉了,不然不公共的依赖放到 seed 里,seed 本身的体系会非常大
- 公共组件需要发布一份到 cdn,并转成 Web 上可运行的 CMD/UMD/AMD 等等,本身也需要一个构建过程。
2. 对复杂 loader 的依赖
由于 seed 文件的存在并且包含比较多的关系描述,需要一个相对复杂的 loader 来解析这个描述,尝试过基于 SystemJs 进行扩展,但是动态性上还是无法和原本自研的 loader 相提并论。有兴趣的同学也可以看下 KISSY 3 的 loader 实现。
webpack Module Federation 可能的问题
1. HTML 的组织
基于 seed json 格式, wormhole 集成了通过 seed.json 生成 HTML 的能力。开发者可以不需要关注 HTML 如何生成,因为 loader 的保障,顺序也没有那么重要。
在 Module Federation 的使用情况下,HTML 还是依赖页面级构建,如果需要在类似搭建场景下动态拼装 HTML,要不就加载所有的 remoteEntry 文件,要不就是得自己提出一个依赖关系出来给到服务端生成。
当然,也可以直接用 SSR,这样的话,就需要另外一个配置来打包一个 SSR 版本的代码,毕竟服务端按需意义没有那么大,并且,SSR 大概率也只能覆盖页面的部分内容,剩下的还是要面临如何组织 HTML 的资源引用的问题。
2. 冗余的代码
因为 Module Federation 把依赖都通过代码的方式打包到了 remoteEntry 文件里,那么必然会存在很多重复定义的代码。比如 webpack _require 下的一堆函数,remoteEntry 加载多了,这个问题会相对严重一些。
不过对比目前天马依赖处理体系来说,feloader 本身因为历史原因+支持了KMD/CMD/AMD等多种模块格式,也有点尺寸过大,所以也有类似的问题。
3. CDN combo
通过 seed.json 描述的依赖关系,是可以快速解析到一个 combo 格式上的,通过一个请求把依赖的脚本合并取到。而目前 Module Federation 每个 remoteEntry 都是独立处理,虽然对比 SystemJs 或者其他 webpack 分包插件,有能力处理深度依赖(依赖的依赖不重复加载),但是缺乏一个合并能力,可能会出现串行加载依赖的情况,不过这个问题扩展下 trunk loader,合并依赖组件 promise 函数的处理,不是很难解决。
搭建的核心设计—渲染服务
上面将的更多还是围绕搭建的物料,天马还提供了通用的 Node.js 在线渲染引擎,用于提供统一的渲染服务,只要通过天马搭建的产物,都可以被渲染服务消费,并渲染出最后的结果给到用户访问。
模板渲染本身没有特别的点,主要说一些不同的。
多终端的缓存
面向阿里大流量的场景,我们设计了一套多终端的缓存方案:
模块是支持跨终端的,那页面也肯定是跨终端的。而这背后是需要统一的终端识别架构来支撑的。目前搭建产物的页面都是托管在一套缓存+源站架构下的,不同的端会有一份对应的缓存副本,避免每次访问都需要重新渲染。
基于这样一套架构,我们也可以实现运营只需要投放一个地址或者二维码,在不同的端就有不同的展现方式。
高性能保障
在支持跨终端的同时,渲染引擎也承担着类似 webpack HtmlWebpackPlugin 的职责,搭建系统发布出来的结果是一个包含页面结构、依赖关系的描述。渲染引擎通过这个描述渲染出 HTML、weex bundle 等。当然这个过程会有一些耗时,主要是在以下两个部分:
- 拉取模块的资源文件,文件需要从 OSS 远程拉取
- 计算整个页面最终的依赖关系
因为渲染服务是在线的,算是基于 CDN 缓存架构的实时渲染(每隔一段时间自动更新回源),如果与 webpack 一样构建速度缓慢的话,还是非常糟糕的事情。所以在这里也做了很多包括依赖关系计算的缓存、文件的缓存等等。然后再通过 CDN 缓存的能力,提升整体的访问速度。
同时为了提升用户访问体验,渲染引擎的部署范围是大于搭建服务的,特别是在国际化场景下,渲染引擎已经部署到了亚欧美,并且为这些国家专门做了 OSS 文件同步优化。
seed体系与 webpack 的长期融合方案
天马独有的这套 seed 依赖关系机制,因为没有像 webpack 那样把依赖关系隐藏起来,还是有一定的学习成本的,并且也容易造成一些问题(当然 webpack 也有他自己的复杂和学习成本 )。
所以那些页面量不大,且没有淘系这样相对比较变态的更新诉求下,因为模块本身也是一个标准的 npm 包,天马也支持了离线构建的方式,这个方案就更贴近 react 源码app的开发,可以做更多的构建时的优化,同时产物也脱离了 seed 体系,渲染过程得到了简化。
长期来说,随着 webpack 本身的发展,最终还是期望能够逐渐合并到社区方案上,在页面构建和动态化能力之间达到一个科学的平衡。
而对于淘系自己来说,动态化始终是一个重要的能力,我自己的设想是,如果今天我们可以不用打包模块,直接把源文件发布到 CDN,把 CDN 当做目录,直接在浏览器上跑一个类似 webpack 的能力,就可以在保留动态性的同时,也不会带来额外的复杂度(复杂度都在方案本身了,对开发者来说,就不需要了解太多)。
为什么这只是一个展望呢,要这么做,还是需要面临一些问题:
- 浏览器的性能是否足够做这样的编译,特别是目前在 webpack 本身编译就是一件耗时的事情,把这部分时间扔给用户侧还是有点可怕的。
- 远程文件系统在网络上的时间消耗,虽然可以设计很多缓存机制,但是首次依然是个问题,并且绕开浏览器本身的缓存机制,做一套文件缓存还是会有很多问题,特别是在无线端 app webview 内,空间是非常有限的。
- 包管理的复杂度,当前的 seed 机制已经做了类似的事情,目前倒不会带来太多包管理方式上的变化。
面向未来考虑,对于开发者来说,写的代码能够更自然且简单的运行,理解成本和维护成本都会降低很多,无论是完善的开发者配套工具,还是友好的模块化设计,都是为了提升开发者体验。
但是人能做的事情始终有限,目前天马也在和 imgcook 和 iceluna 做更多的合作,,结合可视化、智能化代码生成代码,开发者可以更加专注于维护一个机制或者工程,来系统性提升用户体验,丰富业务玩法,而不是投入到无止尽的页面制作上。
天马作为一个搭建服务,还是和阿里的业务绑定的比较多,上面讲的内容也只是天马的一部分,还有很多内容目前还不适合对外。未来也希望能够有更多的渠道,如开源、上云的方式,把天马的服务以及背后的思考分享出来,也欢迎对搭建有兴趣或者有想法的同学来做更多交流。
有意向参与一起建设天马的,以下是联系渠道,我们也有面向搭建方向的交流群。
- 简历邮箱:[email protected]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK