

The Night of the Ethical Algorithm | Gödel's Lost Letter and P=NP
source link: https://rjlipton.wordpress.com/2020/11/02/the-night-of-the-ethical-algorithm/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

The Night of the Ethical Algorithm
Algorithms for the Election
Michael Kearns and Aaron Roth are the authors of the book Ethical Algorithms and the The Science of Socially Aware Algorithm Design. It has earned strong reviews including this one in Nature—impressive.
Michael is a long-time friend who is a leader in machine learning, artificial intelligence, and much more. He also overlapped with Ken at Oxford while visiting Les Valiant there in the mid-1980s. He is at the University of Pennsylvania in computer science along with his co-author Roth. Cynthia Dwork and Roth wrote an earlier book on the related issue of Differential Privacy.
Today we will talk about making algorithms ethical.
Tuesday is the 2020 US national election for President, for Congress, and for state and local offices. Every four years we have a national election, and we cannot imagine a better motivation for making sure that algorithms are ethical.
The word “algorithm” appears 157 times in their book. Two words used hand-in-hand with it are “data” (132 times) and “model” (103 times), both spread through all of the book’s 232 pages. Models of electorates, trained on data from past elections, inform the algorithms used by news agencies to make election-night projections. These carry more responsibilities than election-eve forecasts. There have been infamous mistakes, most notably the premature calls of Florida both ways in the 2000 election.
We believe that Tuesday’s election in our novel pandemic situation requires attention to ethics from first principles. We will discuss why this is important. What it means to be ethical here? And how one can make an algorithm ethical?
The Issue
Algorithms have been around forever. Euclid devised his gcd algorithm in 300 BCE. In the first half of the last century, the central issue was how to define that an algorithm is effective. This led to showing that some problems are uncomputable, so that algorithms for them are impossible.
In the second half, the emphasis shifted to whether algorithms are efficient. This led to classifying problems as feasible or (contingently) hard. Although many algorithms for feasible problems have been improved in ways that redouble the effect of faster and cheaper hardware, the study of complexity classes such as 
The new territory, that of Kearns and Roth, is whether algorithms are ethical. Current ones that they and others have critqued as unethical accompany models for the likes of mortgages, small-business loans, parole decisions, and college admissions. The training data for these models often bakes in past biases. Besides problems of racial and gender bias and concerns of societal values, the raw fact is that past biases cause the models to miss the mark for today’s applications. For algorithms with such direct application to society, ethical design is critical.
But this requirement is further reaching that one might initially imagine, so that as with computability and complexity, the factors can be ingrained in the problems.
Consider a simple problem: We given a collection of pairs of numbers 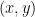

This is pretty easy if we can use both 



Then seeing only
The blurb for the Kearns-Roth book says that they “…explain how we can better embed human principles into machine code—without halting the advance of data-driven scientific exploration.” While we agree their approach is vital, we suspect that as with complexity there will be indelibly ethically hard tasks. We wonder whether election modeling has already become one of them.
Ken and I have two separate takes on this. We will do the first and then the other in a second post.
Red/Blue Leakage, Bias, and Ethics
One question on everyone’s minds is whether we will see a repeat of the forecasting misses from 2016. Let us remind that our own Election Day 2016 post started by defending Nate Silver of FiveThirtyEight for giving Donald Trump as much as a 30% chance to defeat Hillary Clinton. He had been attacked by representatives of many news and opinion agencies whose models had Clinton well over 90%.
We wonder whether these models were affected by the kind of biases highlighted in the book by Kearns and Roth. We must say right away that we are neither alleging conscious biases nor questioning the desire for prediction accuracy. One issue in ethical modeling (for parole, loans, admissions) is the divergence between algorithm outcomes that are most predictive versus those that are best for society. Here we agree that accurate prediction—and accurate projections as results come in after the polls close—is paramount. However, the algorithms used for the latter projections (which were not at fault in 2016 but have been wrong previously) may be even more subject to what we as computer scientists with crypto background see as a “leakage” issue.
Here is the point. Ideally, models using polling data and algorithms reading the Election Night returns should read the numbers as if they did not have ‘R’ and ‘D’ attached to them. Their own workings should be invariant under transformations that interchange Joe Biden and Donald Trump, or whoever are opposed in a local race. However, a crucial element in the projection models in particular is knowledge of voting geography. They must use data on the general voting preferences of regions where much of the vote is still extant. Thus they cannot avoid intimate knowledge of who is ‘R’ and who is ‘D.’ There is no double-blind or zero-knowledge approach to the subjects being projected.
There is also the question of error bars. A main point of our 2016 post (and of Silver’s analysis) was the high uncertainty factor that could be read from how the Clinton-Trump race unfolded. Underestimating uncertainty causes overconfidence in models. This can result from “groupthink” of the kind we perceive in newsrooms of many of the same outlets that are doing the projections. The algorithms ought to be isolated from opinions of those in the organization, but again there is reason from the last election to wonder about leakage.
Unlike cases addressed by Kearns and Roth, we do not see a solution to suggest. As in our simple 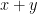
Open Problems
The word “election” does not appear in Kearns and Roth’s book. What further application of their standpoint to elections would you make?
Ken sees a larger question of ethical modeling decisions given the unprecedented circumstances of the current election. This comes not from spatial geography distorted by the pandemic but rather from the dimension of time injected by massive early voting and late counting of many mailed ballots. He will address this next.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK