

机器学习算法之XGBoost
source link: https://www.biaodianfu.com/xgboost.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在上一篇Boosting方法的介绍中,对XGBoost有过简单的介绍。为了更还的掌握XGBoost这个工具。我们再来对它进行更加深入细致的学习。
什么是XGBoost?
- 全称:eXtreme Gradient Boosting
- 作者:陈天奇(华盛顿大学博士)
- 基础:GBDT
- 所属:boosting迭代型、树类算法。
- 适用范围:分类、回归
- 优点:速度快、效果好、能处理大规模数据、支持多种语言、支持自定义损失函数等等。
- 缺点:算法参数过多,调参负责,对原理不清楚的很难使用好XGBoost。不适合处理超高维特征数据。
- 项目地址:https://github.com/dmlc/xgboost
XGBoost的原理
XGBoost 所应用的算法就是 gradient boosting decision tree,既可以用于分类也可以用于回归问题中。那什么是 Gradient Boosting?Gradient boosting 是 boosting 的其中一种方法。所谓 Boosting ,就是将弱分离器 f_i(x) 组合起来形成强分类器 F(x) 的一种方法。所以 Boosting 有三个要素:
- A loss function to be optimized:例如分类问题中用 cross entropy,回归问题用 mean squared error。
- A weak learner to make predictions:例如决策树。
- An additive model:将多个弱学习器累加起来组成强学习器,进而使目标损失函数达到极小。
Gradient boosting 就是通过加入新的弱学习器,来努力纠正前面所有弱学习器的残差,最终这样多个学习器相加在一起用来进行最终预测,准确率就会比单独的一个要高。之所以称为 Gradient,是因为在添加新模型时使用了梯度下降算法来最小化的损失。一般来说,gradient boosting 的实现是比较慢的,因为每次都要先构造出一个树并添加到整个模型序列中。而 XGBoost 的特点就是计算速度快,模型表现好,这两点也正是这个项目的目标。
XGBoost的优势
XGBoost算法可以给预测模型带来能力的提升。当我对它的表现有更多了解的时候,当我对它的高准确率背后的原理有更多了解的时候,你会发现它具有很多优势:
- 正则化。XGBoost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- XGBoost工具支持并行。Boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 高度的灵活性。XGBoost支持用户自定义目标函数和评估函数,只要目标函数二阶可导就行。
- 缺失值处理。XGBoost内置处理缺失值的规则。用户需要提供一个和其它样本不同的值,然后把它作为一个参数传进去,以此来作为缺失值的取值。XGBoost在不同节点遇到缺失值时采用不同的处理方法,并且会学习未来遇到缺失值时的处理方法。
- 剪枝。当分裂时遇到一个负损失时,GBM会停止分裂。因此GBM实际上是一个贪心算法。 XGBoost会一直分裂到指定的最大深度(max_depth),然后回过头来剪枝。如果某个节点之后不再有正值,它会去除这个分裂。 这种做法的优点,当一个负损失(如-2)后面有个正损失(如+10)的时候,就显现出来了。GBM会在-2处停下来,因为它遇到了一个负值。但是XGBoost会继续分裂,然后发现这两个分裂综合起来会得到+8,因此会保留这两个分裂。比起GBM,这样不容易陷入局部最优解。
- 内置交叉验证。XGBoost允许在每一轮boosting迭代中使用交叉验证。因此,可以方便地获得最优boosting迭代次数。而GBM使用网格搜索,只能检测有限个值。
- 在已有的模型基础上继续。XGBoost可以在上一轮的结果上继续训练。
基础知识——GBDT
XGBoost是在GBDT的基础上对boosting算法进行的改进,内部决策树使用的是回归树,简单回顾GBDT如下:
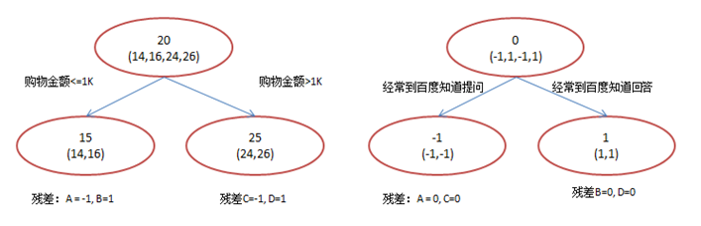
回归树的分裂结点:
对于平方损失函数,拟合的就是残差;
对于一般损失函数(梯度下降),拟合的就是残差的近似值,分裂结点划分时枚举所有特征的值,选取划分点。
最后预测的结果是每棵树的预测结果相加。
XGBoost算法原理知识
定义树的复杂度
1、把树拆分成树结构部分q和叶子权重部分w
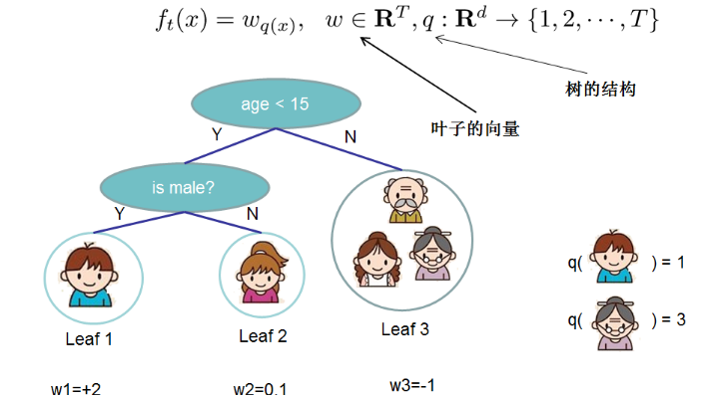
2、树的复杂度函数和样例
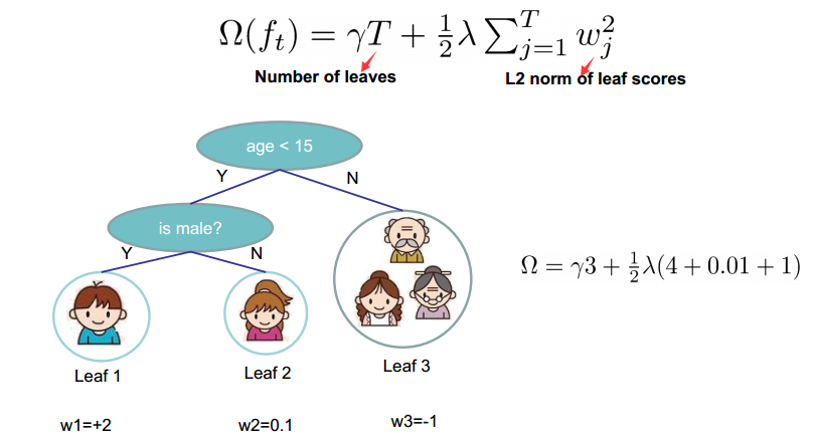
定义树的结构和复杂度的原因很简单,这样就可以衡量模型的复杂度了啊,从而可以有效控制过拟合。
XGBoost中的boosting tree模型
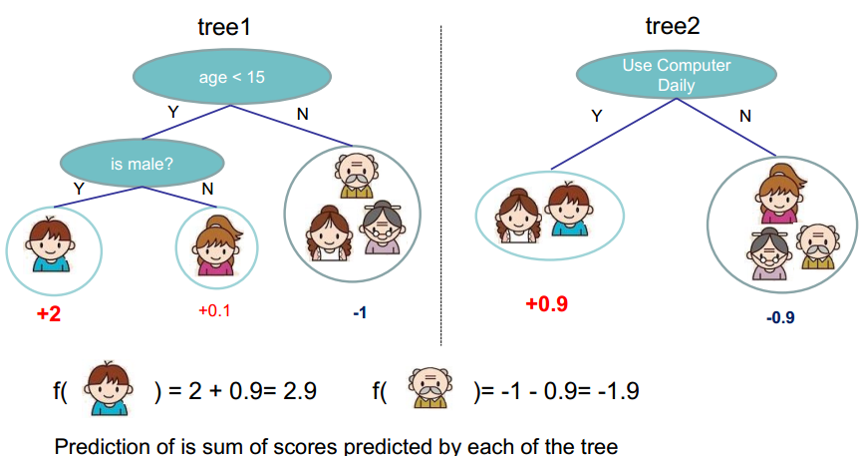
和传统的boosting tree模型一样,XGBoost的提升模型也是采用的残差(或梯度负方向),不同的是分裂结点选取的时候不一定是最小平方损失。
\mathcal{L}(\phi)=\sum_{i} l\left(\hat{y}_{i}, y_{i}\right)+\sum_{k} \Omega\left(f_{k}\right)
\text { where } \Omega(f)=\gamma T+\frac{1}{2} \lambda\|w\|^{2}
对目标函数的改写——二阶泰勒展开(关键)

最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。这么写的原因很明显,由于之前的目标函数求最优解的过程中只对平方损失函数时候方便求,对于其他的损失函数变得很复杂,通过二阶泰勒展开式的变换,这样求解其他损失函数变得可行了。当定义了分裂候选集合的时候I_j = \{i|q(x_i)=j\}。可以进一步改目标函数。分裂结点的候选集是很关键的一步,这是xgboost速度快的保证,怎么选出来这个集合,后面会介绍。
\begin{aligned}Obj^{(t)} & \simeq \sum_{i=1}^{n}\left[g_{i} f_{t}\left(x_{i}\right)+\frac{1}{2} h_{i} f_{t}^{2}\left(x_{i}\right)\right]+\Omega\left(f_{t}\right) \\ &=\sum_{i=1}^{n}\left[g_{i} w_{q\left(x_{i}\right)}+\frac{1}{2} h_{i} w_{q\left(x_{i}\right)}^{2}\right]+\gamma T+\lambda \frac{1}{2} \sum_{j=1}^{T} w_{j}^{2} \\ &=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T \end{aligned}
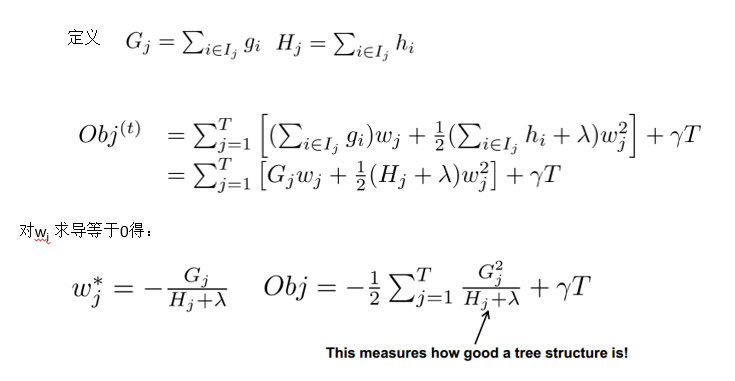
树结构的打分函数
Obj代表了当指定一个树的结构的时候,在目标上面最多减少多少?

对于每一次尝试去对已有的叶子加入一个分割
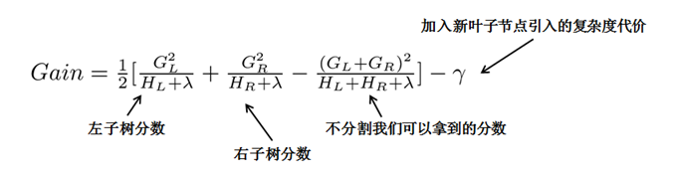
这样就可以在建树的过程中动态的选择是否要添加一个结点。
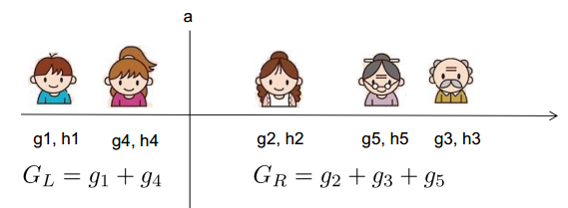
假设要枚举所有x < a 这样的条件,对于某个特定的分割a,要计算a左边和右边的导数和。对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和GL、GR。然后用上面的公式计算每个分割方案的分数就可以了。
寻找分裂结点的候选集
1、暴力枚举
2、近似方法 ,近似方法通过特征的分布,按照百分比确定一组候选分裂点,通过遍历所有的候选分裂点来找到最佳分裂点。两种策略:全局策略和局部策略。
- 在全局策略中,对每一个特征确定一个全局的候选分裂点集合,就不再改变;
- 在局部策略中,每一次分裂都要重选一次分裂点。
前者需要较大的分裂集合,后者可以小一点。对比补充候选集策略与分裂点数目对模型的影响。全局策略需要更细的分裂点才能和局部策略差不多
3、Weighted Quantile Sketch

陈天奇提出并从概率角度证明了一种带权重的分布式的Quantile Sketch。
参考链接:
如何使用XGBoost?
XGBoost的安装
网上很多教程教的是如何进行编译安装,过程比较繁琐,比较简单的方式是下载已经编译好的.whl文件进行安装。
XGBoost的参数
XGBoost的作者把所有的参数分成了三类:
- 通用参数:宏观函数控制。
- Booster参数:控制每一步的booster(tree/regression)。
- 学习目标参数:控制训练目标的表现。
在这里我们会类比GBM来讲解,所以作为一种基础知识。
这些参数用来控制XGBoost的宏观功能。
- booster[默认gbtree] 选择每次迭代的模型,有两种选择:
- gbtree:基于树的模型
- gbliner:线性模型。使用带l1,l2 正则化的线性回归模型作为基学习器。因为boost 算法是一个线性叠加的过程,而线性回归模型也是一个线性叠加的过程。因此叠加的最终结果就是一个整体的线性模型,xgboost 最后会获得这个线性模型的系数。
- dart: 表示采用dart booster
- silent[默认0] 当这个参数值为1时,静默模式开启,不会输出任何信息。一般这个参数就保持默认的0,因为这样能帮我们更好地理解模型。
- nthread[默认值为最大可能的线程数] 这个参数用来进行多线程控制,应当输入系统的核数。如果你希望使用CPU全部的核,那就不要输入这个参数,算法会自动检测它。
- num_pbuffer 指定了prediction buffer(该buffer 用于保存上一轮boostring step 的预测结果) 的大小。通常设定为训练样本的数量。该参数由xgboost 自动设定,无需用户指定。
- num_feature 样本的特征数量。通常设定为特征的最大维数。该参数由xgboost 自动设定,无需用户指定。
Tree Booster 参数
因为tree booster的表现远远胜过linear booster,所以linear booster很少用到。针对tree booster 的参数(适用于booster=gbtree,dart) :
- eta[默认3] 和GBM中的 learning rate 参数类似。通过减少每一步的权重,可以提高模型的鲁棒性。范围为 [0,1],典型值为0.01-0.2。
- min_child_weight[默认1] 子节点的权重阈值。它刻画的是:对于一个叶子节点,当对它采取划分之后,它的所有子节点的权重之和的阈值。所谓的权重,对于线性模型(booster=gblinear),权重就是:叶子节点包含的样本数量,对于树模型(booster=gbtree,dart),权重就是:叶子节点包含样本的所有二阶偏导数之和。这个参数用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。该值越大,则算法越保守(尽可能的少划分)。
- 如果它的所有子节点的权重之和大于该阈值,则该叶子节点值得继续划分
- 如果它的所有子节点的权重之和小于该阈值,则该叶子节点不值得继续划分
- max_delta_step[默认为0] 每棵树的权重估计时的最大delta step。取值范围为[0,\infty],0 表示没有限制。
- max_depth[默认6] GBM中的参数相同,这个值为树的最大深度。这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。需要使用CV函数来进行调优。典型值:3-10
- max_leaf_nodes 树上最大的节点或叶子的数量。可以替代max_depth的作用。因为如果生成的是二叉树,一个深度为n的树最多生成n^2个叶子。如果定义了这个参数,GBM会忽略max_depth参数。
- gamma[默认0] 也称作最小划分损失min_split_loss。 它刻画的是:对于一个叶子节点,当对它采取划分之后,损失函数的降低值的阈值。该值越大,则算法越保守(尽可能的少划分)。默认值为 0
- 如果大于该阈值,则该叶子节点值得继续划分
- 如果小于该阈值,则该叶子节点不值得继续划分
- max_delta_step[默认0] 这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。通常,这个参数不需要设置。但是当各类别的样本十分不平衡时,它对逻辑回归是很有帮助的。这个参数一般用不到,但是你可以挖掘出来它更多的用处。
- subsample[默认1] 对训练样本的采样比例。和GBM中的subsample参数一模一样。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:5-1
- colsample_bytree[默认1] 构建子树时,对特征的采样比例。和GBM里面的max_features参数类似。用来控制每棵随机采样的列数的占比(每一列是一个特征)。典型值:5-1
- colsample_bylevel[默认1] 寻找划分点时,对特征的采样比例。用来控制树的每一级的每一次分裂,对列数的采样的占比。一般不太用这个参数,因为subsample参数和colsample_bytree参数可以起到相同的作用。如果为5, 表示随机使用一半的特征来寻找最佳划分点。它有助于缓解过拟合。
- lambda[默认1] 权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。该值越大则模型越简单。
- alpha[默认0] 权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。该值越大则模型越简单。
- scale_pos_weight[默认1] 用于调整正负样本的权重,常用于类别不平衡的分类问题。一个典型的参数值为:负样本数量/正样本数量。
- tree_method[默认为’auto’] 指定了构建树的算法,可以为下列的值(分布式,以及外存版本的算法只支持 ‘approx’,’hist’,’gpu_hist’ 等近似算法):
- ‘auto’: 使用启发式算法来选择一个更快的tree_method:
- 对于小的和中等的训练集,使用exact greedy 算法分裂节点
- 对于非常大的训练集,使用近似算法分裂节点
- 旧版本在单机上总是使用exact greedy 分裂节点
- ‘exact’: 使用exact greedy 算法分裂节点
- ‘approx’: 使用近似算法分裂节点
- ‘hist’: 使用histogram 优化的近似算法分裂节点(比如使用了bin cacheing 优化)
- ‘gpu_exact’: 基于GPU 的exact greedy 算法分裂节点
- ‘gpu_hist’: 基于GPU 的histogram 算法分裂节点
- ‘auto’: 使用启发式算法来选择一个更快的tree_method:
- sketch_eps[默认值为03] 指定了分桶的步长。其取值范围为 (0,1)。它仅仅用于 tree_medhod=’approx’。它会产生大约1/ sketch_eps个分桶。它并不会显示的分桶,而是会每隔 sketch_pes 个单位(一个单位表示最大值减去最小值的区间)统计一次。用户通常不需要调整该参数。
- updater[默认为 ‘grow_colmaker,prune’] 它是一个逗号分隔的字符串,指定了一组需要运行的tree updaters,用于构建和修正决策树。该参数通常是自动设定的,无需用户指定。但是用户也可以显式的指定。
- refresh_leaf[默认为1] 它是一个updater plugin。 如果为 true,则树节点的统计数据和树的叶节点数据都被更新;否则只有树节点的统计数据被更新。
- process_type 指定要执行的处理过程(如:创建子树、更新子树)。该参数通常是自动设定的,无需用户指定。
- grow_policy[默认为’depthwise’] 用于指定子树的生长策略。仅仅支持tree_method=’hist’。 有两种策略:
- ‘depthwise’:优先拆分那些靠近根部的子节点。
- ‘lossguide’:优先拆分导致损失函数降低最快的子节点
- max_leaves[默认为0] 最多的叶子节点。如果为0,则没有限制。该参数仅仅和grow_policy=’lossguide’ 关系较大。
- max_bin[默认值为 256] 指定了最大的分桶数量。该参数仅仅当 tree_method=’hist’,’gpu_hist’ 时有效。
- Predictor[默认为’cpu_predictor’] 指定预测器的算法,可以为:
- ‘cpu_predictor’: 使用CPU 来预测
- ‘gpu_predictor’: 使用GPU 来预测。对于tree_method=’gpu_exact,gpu_hist’, ‘gpu_redictor’ 是默认值。
Dart Booster 参数
XGBoost基本上都是组合大量小学习率的回归树。在这种情况,越晚添加的树比越早添加的树更重要。Rasmi根据深度神经网络社区提出一个新的使用dropout的boosted trees,并且证明它在某些情况有更好的结果。以下是新的tree boosterdart的介绍。
DART booster 原理:为了缓解过拟合,采用dropout 技术,随机丢弃一些树。
由于引入了随机性,因此dart 和gbtree 有以下的不同:
- 因为随机dropout不使用用于保存预测结果的buffer所以训练会更慢
- 因为随机早停可能不够稳定
DART算法和MART(GBDT)算法主要有两个不同点:
dropout
计算下一棵树要拟合的梯度的时候,仅仅随机从已经生成的树中选取一部分。假设经过n次迭代之后当前模型为M,M=\sum_{i=1}^nT_i,当中T_i是第i次学习到的树。DART算法首先选择一个随机子集I\subset{\{1,…,n\}},创建模型\hat{M}=\sum_{i\in{I}}T_i。树T从\{(x,-L_x’(\hat{M}(x)))\}学习得到,当中L_x’()表示求损失函数的梯度作为下一次的标签,GDBT中使用损失函数的梯度作为下一个树的输入标签。
归一化
DART和MART第二点不同就是DART添加一棵树时需要先归一化。归一化背后的原理是:树T是尝试减少\hat{M}和最优预测器之间的差距,dropped trees也是为了减少这个差距。因此引入new tree和dropped trees都是为了达到相同的目标。进一步说,假设通过I建立模型\hat{M}时drop掉k棵树。所以新的树T大概是dropped trees中每一个独立的树的k倍。因此,DART算法将树T乘以1/k,这使T的大小和每一个单独的dropped trees相同。然后,新的树和dropped trees都乘以k/(1+k),再将新的树加入集成模型中。乘以k/(k+1)是为了保证新的树的引入和不引入的效果一样。
XGBoost官方文档
- 第m步,假设随机丢弃K棵,被丢弃的树的下标为集合\mathbb K。令D=\sum_{k\in \mathbb K}h_k,第m棵树为h_m。则目标函数为:
\mathcal L=\sum_{i=1}^NL\left(y_i,\hat y^{<m-1>}_i-D(\mathbf {\vec x}_i)+\nu h_m(\mathbf{\vec x}_i)\right)+\Omega(f_m)
- 由于dropout 在设定目标函数时引入了随机丢弃,因此如果直接引入h_m,则会引起超调。因此引入缩放因子,这称作为归一化:
f_m = \sum_{k\ne \mathbb K} h_k+\alpha\left(\sum_{k\in\mathbb K}h_k+b \nu h_m\right)
- 其中b为新的子树与丢弃的子树的权重之比,\alpha为修正因子。
- 令\hat M=\sum_{k\ne \mathbb K} h_k。采用归一化的原因是:h_m试图缩小\hat M到目标之间的 gap;而D也会试图缩小\hat M到目标之间的gap。如果同时引入随机丢弃的子树集合D,以及新的子树h_m,则会引起超调。
- 有两种归一化策略:
- ‘tree’: 新加入的子树具有和每个丢弃的子树一样的权重,假设都是都是\frac 1K。此时b=\frac 1K,则有:
\alpha\left(\sum_{k\in\mathbb K}h_k+b \nu h_m\right)=\alpha\left(\sum_{k\in\mathbb K}h_k+\frac \nu K h_m\right) \sim \alpha\left(1+\frac \nu K\right)D=\alpha \frac{K+\nu}{K}D
要想缓解超调,则应该使得\alpha\left(\sum_{k\in\mathbb K}h_k+b \nu h_m\right) \sim D,则有:\alpha=\frac{K}{K+\nu}。
-
- ‘forest’:新加入的子树的权重等于丢弃的子树的权重之和。假设被丢弃的子树权重都是\frac 1K, 则此时b=1,则有:
\alpha\left(\sum_{k\in\mathbb K}h_k+b \nu h_m\right)=\alpha\left(\sum_{k\in\mathbb K}h_k+ \nu h_m\right) \sim \alpha\left(1+ \nu \right)D
要想缓解超调,则应该使得\alpha\left(\sum_{k\in\mathbb K}h_k+b \nu h_m\right) \sim D,则有\alpha=\frac{1}{1+\nu}: 。
原始链接:Rashmi Korlakai Vinayak, Ran Gilad-Bachrach. “DART: Dropouts meet Multiple Additive Regression Trees.
DART booster继承了gbtree,所以dart也有eta.gamma,max_depth等参数,额外增加的参数如下:
- sample_type[默认值’uniform’] 它指定了丢弃时的策略:
- ‘uniform’: 随机丢弃子树
- ‘weighted’: 根据权重的比例来丢弃子树
- normaliz_type它指定了归一化策略:
- ‘tree’: 新的tree和每一个dropped trees有同样的权重,新的子树将被缩放为:\frac{1}{K+v};被丢弃的子树被缩放为\frac{v}{K+v}。其中v为学习率,K为被丢弃的子树的数量
- ‘forest’:新的树和所有dropped trees的和有相同的权重,新的子树将被缩放为:\frac{1}{1+v};被丢弃的子树被缩放为\frac{v}{1+v}。其中v为学习率
- rate_drop[默认为0] dropout rate,指定了当前要丢弃的子树占当前所有子树的比例。范围为[0,1]。
- one_drop[默认为0] 如果该参数为true,则在dropout 期间,至少有一个子树总是被丢弃。
- skip_drop[默认为0] 它指定了不执行 dropout 的概率,其范围是[0,1]。
- 如果一次dropout被略过,新的树被添加进model用和gbtree一样的方式。
- 非0的skip_drop比rate_drop和one_drop有更高的优先级。
Linear Booster 参数
- Lambda[默认为0] L2 正则化系数(基于weights 的正则化),该值越大则模型越简单
- Alpha[默认为0] L1 正则化系数(基于weights的正则化),该值越大则模型越简单
- lambda_bias[默认为0] L2 正则化系数(基于bias 的正则化), 没有基于bias 的 L1 正则化,因为它不重要。
Tweedie Regression 参数
- weedie_variance_power[默认为5] 指定了tweedie 分布的方差。取值范围为 (1,2),越接近1,则越接近泊松分布;越接近2,则越接近 gamma 分布。
学习目标参数
这个参数用来控制理想的优化目标和每一步结果的度量方法。
- objective[默认reg:linear] 指定任务类型
- ‘reg:linear’: 线性回归模型。它的模型输出是连续值
- ‘reg:logistic’: 逻辑回归模型。它的模型输出是连续值,位于区间[0,1] 。
- ‘binary:logistic’:二分类的逻辑回归模型,它的模型输出是连续值,位于区间[0,1] ,表示取正负类别的概率。它和’reg:logistic’ 几乎完全相同,除了有一点不同:
- ‘reg:logistic’ 的默认evaluation metric 是 rmse 。
- ‘binary:logistic’ 的默认evaluation metric 是 error
- ‘binary:logitraw’: 二分类的逻辑回归模型,输出为分数值(在logistic 转换之前的值)
- ‘count:poisson’: 对 count data 的 poisson regression, 输出为泊松分布的均值。
- ‘multi:softmax’: 基于softmax 的多分类模型。此时你需要设定num_class 参数来指定类别数量。返回预测的类别(不是概率)
- ‘multi:softprob’: 基于softmax 的多分类模型,但是它的输出是一个矩阵:ndata*nclass,给出了每个样本属于每个类别的概率。
- ‘rank:pairwise’: 排序模型(优化目标为最小化pairwise loss)
- ‘reg:gamma’: gamma regression,输出为伽马分布的均值。
- ‘reg:tweedie’:’tweedie regression’。
- base_score[默认为5] 所有样本的初始预测分,它用于设定一个初始的、全局的bias。当迭代的数量足够大时,该参数没有什么影响。
- eval_metric[默认值取决于objective参数的取值] 对于有效数据的度量方法。对于回归问题,默认值是rmse,对于分类问题,默认值是error。排序问题的默认值是 mean average precision。典型值有:
- rmse 均方根误差
- mae 平均绝对误差
- logloss 负对数似然函数值
- error 二分类错误率(阈值为5),它计算的是:预测错误的样本数/所有样本数
- error@t 二分类的错误率。但是它的阈值不再是5, 而是由字符串t 给出(它是一个数值转换的字符串)
- merror 多分类错误率,它计算的是:预测错误的样本数/所有样本数
- mlogloss多类分类的负对数似然函数
- auc 损失函数 auc 曲线下面积
- ndcg Normalized Discounted Cumulative Gain 得分
- map Mean average precision 得分
- ndcg@n,map@n n 为一个整数,用于切分验证集的top 样本来求值。
- ndcg-,map-,ndcg@n-,map@n- NDCG and MAP will evaluate the score of a list without any positive samples as 1. By adding “-” in the evaluation metric XGBoost will evaluate these score as 0 to be consistent under some conditions. training repeatedly
- poisson-nloglik 对于泊松回归,使用负的对数似然
- gamma-nloglik 对于伽马回归,使用负的对数似然
- gamma-deviance 对于伽马回归,使用残差的方差
- tweedie-nloglik: 对于tweedie 回归,使用负的对数似然
- Seed[默认0] 随机数的种子,设置它可以复现随机数据的结果,也可以用于调整参数。
如果你之前用的是Scikit-learn,你可能不太熟悉这些参数。但是有个好消息,python的XGBoost模块有一个sklearn包。这个包中的参数是按sklearn风格命名的。会改变的函数名是:
- eta ->learning_rate
- lambda->reg_lambda
- alpha->reg_alpha
你肯定在疑惑为啥咱们没有介绍和GBM中的’n_estimators’类似的参数。XGBoost中确实有一个类似的参数,是在标准XGBoost实现中调用拟合函数时,把它作为’num_boosting_rounds’参数传入。
参考链接:
对于external-memory 和 in-memory 计算,二者几乎没有区别。除了在文件名上有所不同。
- in-memory 的文件名为:filename
- external-memory 的文件名为:filename#cacheprefix。
- filename:是你想加载的数据集(当前只支持导入libsvm 格式的文件)的路径名
- cacheprefix:指定的cache 文件的路径名。xgboost 将使用它来做external memory cache。如:dtrain = xgb.DMatrix(‘../data/my_data.txt.train#train_cache.cache’),此时你会发现在txt 所在的位置会由xgboost 创建一个my_cache.cache 文件。
- 推荐将nthread 设置为真实CPU 的数量。现代的CPU都支持超线程,如4核8线程。此时nthread 设置为4而不是8。
- 对于分布式计算,外存计算时文件名的设定方法也相同:data = “hdfs:///path-to-data/my_data.txt.train#train_cache.cache”
GPU计算
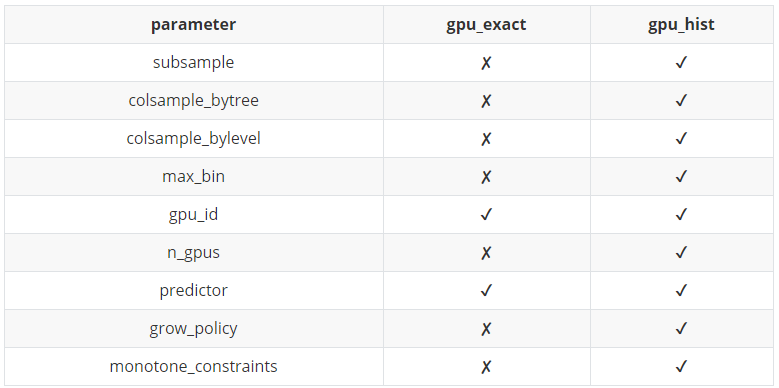
xgboost 支持使用gpu 计算,前提是安装时开启了GPU 支持。要想使用GPU 训练,需要指定tree_method 参数为下列的值:
- ‘gpu_exact’: 标准的xgboost 算法。它会对每个分裂点进行精确的搜索。相对于’gpu_hist’,它的训练速度更慢,占用更多内存
- ‘gpu_hist’:使用xgboost histogram 近似算法。它的训练速度更快,占用更少内存
当tree_method 为’gpu_exact’,’gpu_hist’ 时,模型的predict 默认采用GPU 加速。
你可以通过设置predictor 参数来指定predict 时的计算设备:
- ‘cpu_predictor’: 使用CPU 来执行模型预测
- ‘gpu_predictor’: 使用GPU 来执行模型预测
多GPU 可以通过grow_gpu_hist 参数和 n_gpus 参数配合使用。如果n_gpus设置为 -1,则所有的GPU 都被使用。它默认为1。多GPU 不一定比单个GPU 更快,因为PCI总线的带宽限制,数据传输速度可能成为瓶颈。可以通过gpu_id 参数来选择设备,默认为 0 。如果非0,则GPU 的编号规则为 mod(gpu_id + i) % n_visible_devices for i in 0~n_gpus-1
GPU 计算支持的参数:
在模型中可能会有一些单调的约束:当x \le x^\prime时:
- 若f(x_1,x_2,\cdots,x,\cdots,x_{n}) \le f(x_1,x_2,\cdots,x^\prime,\cdots,x_{n}) ,则称该约束为单调递增约束
- 若f(x_1,x_2,\cdots,x,\cdots,x_{n}) \ge f(x_1,x_2,\cdots,x^\prime,\cdots,x_{n}) ,则称该约束为单调递减约束
如果想在xgboost 中添加单调约束,则可以设置monotone_constraints 参数。假设样本有 2 个特征,则:
- params[‘monotone_constraints’] = “(1,-1)” :表示第一个特征是单调递增;第二个特征是单调递减
- params[‘monotone_constraints’] = “(1,0)” :表示第一个特征是单调递增;第二个特征没有约束
- params[‘monotone_constraints’] = “(1,1)” :表示第一个特征是单调递增;第二个特征是单调递增
右侧的 1 表示单调递增约束;0 表示无约束; -1 表示单调递减约束。 有多少个特征,就对应多少个数值。
XGBoost的数据接口
xgboost 的数据存储在DMatrix 对象中,xgboost 支持直接从下列格式的文件中加载数据:
- libsvm 文本格式的文件。其格式为:
[label] [index1]:[value1] [index2]:[value2] ... [label] [index1]:[value1] [index2]:[value2] ... ...
- xgboost binary buffer 文件
dtrain = xgb.DMatrix('train.svm.txt') #libsvm 格式
dtest = xgb.DMatrix('test.svm.buffer') # xgboost binary buffer 文件
- 二维的numpy array 中加载数据
data = np.random.rand(5, 10) label = np.random.randint(2, size=5) dtrain = xgb.DMatrix(data, label=label)#从 numpy array 中加载
- sparse array 中加载数据
csr = scipy.sparse.csr_matrix((dat, (row, col))) dtrain = xgb.DMatrix(csr)
DMatrix
DMatrix: 由xgboost 内部使用的数据结构,它存储了数据集,并且针对了内存消耗和训练速度进行了优化。
xgboost.DMatrix(data, label=None, missing=None, weight=None, silent=False,
feature_names=None, feature_types=None, nthread=None)
- data:表示数据集。可以为:
- 一个字符串,表示文件名。数据从该文件中加载
- 一个二维的 numpy array, 表示数据集。
- label:一个序列,表示样本标记。
- missing: 一个值,它是缺失值的默认值。
- weight:一个序列,给出了数据集中每个样本的权重。
- silent: 一个布尔值。如果为True,则不输出中间信息。
- feature_names: 一个字符串序列,给出了每一个特征的名字
- feature_types: 一个字符串序列,给出了每个特征的数据类型
- nthread:线程数
- feature_names: 返回每个特征的名字
- feature_types: 返回每个特征的数据类型
- .get_base_margin(): 返回一个浮点数,表示DMatrix 的 base margin。
- .set_base_margin(margin): 设置DMatrix 的 base margin。参数:margin,t一个序列,给出了每个样本的prediction margin
- .get_float_info(field): 返回一个numpy array, 表示DMatrix 的 float property 。
- .set_float_info(field,data): 设置DMatrix 的 float property。
- .set_float_info_npy2d(field,data): 设置DMatrix 的 float property。这里的data 是二维的numpy array参数:
- field: 一个字符串,给出了information 的字段名。注:意义未知。
- data: 一个numpy array,给出了数据集每一个点的float information
- .get_uint_info(field): 返回DMatrix 的 unsigned integer property。
- .set_unit_info(field,data): 设置DMatrix 的 unsigned integer property。返回值:一个numpy array,表示数据集的unsigned integer information
- .get_label(): 返回一个numpy array,表示DMatrix 的 label 。
- .set_label(label): 设置样本标记。
- .set_label_npy2d(label): 设置样本标记。这里的label 为二维的numpy array。参数: label: 一个序列,表示样本标记
- .get_weight():一个numpy array,返回DMatrix 的样本权重。
- .set_weight(weight): 设置样本权重。
- .set_weight_npy2d(weight): 设置样本权重。这里的weight 为二维的numpy array
- .num_col(): 返回DMatrix 的列数,返回值:一个整数,表示特征的数量
- .num_row(): 返回DMatrix 的行数,返回值:一个整数,表示样本的数量
- save_binary(fname,silent=True): 保存DMatrix 到一个 xgboost buffer 文件中。参数:
- fname: 一个字符串,表示输出的文件名
- silent: 一个布尔值。如果为True,则不输出中间信息。
- .set_group(group): 设置DMatrix 每个组的大小(用于排序任务)参数:group: 一个序列,给出了每个组的大小
- slice(rindex): 切分DMaxtrix ,返回一个新的DMatrix。 该新的DMatrix 仅仅包含rindex
- 参数:rindex: 一个列表,给出了要保留的index
- 返回值:一个新的DMatrix 对象
data/train.svm.txt 的内容: 1 1:1 2:2 1 1:2 2:3 1 1:3 2:4 1 1:4 2:5 0 1:5 2:6 0 1:6 2:7 0 1:7 2:8 0 1:8 2:9
测试代码:
import xgboost as xgt
import numpy as np
class MatrixTest:
'''
测试 DMatrix
'''
def __init__(self):
self._matrix1 = xgt.DMatrix('data/train.svm.txt')
self._matrix2 = xgt.DMatrix(data=np.arange(0, 12).reshape((4, 3)),
label=[1, 2, 3, 4], weight=[0.5, 0.4, 0.3, 0.2],
silent=False, feature_names=['a', 'b', 'c'],
feature_types=['int', 'int', 'float'], nthread=2)
def print(self, matrix):
print('feature_names:%s' % matrix.feature_names)
print('feature_types:%s' % matrix.feature_types)
def run_get(self, matrix):
print('get_base_margin():', matrix.get_base_margin())
print('get_label():', matrix.get_label())
print('get_weight():', matrix.get_weight())
print('num_col():', matrix.num_col())
print('num_row():', matrix.num_row())
def test(self):
print('查看 matrix1 :')
self.print(self._matrix1)
# feature_names:['f0', 'f1', 'f2']
# feature_types:None
print('\n查看 matrix2 :')
self.print(self._matrix2)
# feature_names:['a', 'b', 'c']
# feature_types:['int', 'int', 'float']
print('\n查看 matrix1 get:')
self.run_get(self._matrix1)
# get_base_margin(): []
# get_label(): [1. 1. 1. 1. 0. 0. 0. 0.]
# get_weight(): []
# num_col(): 3
# num_row(): 8
print('\n查看 matrix2 get:')
self.run_get(self._matrix2)
# get_base_margin(): []
# get_label(): [1. 2. 3. 4.]
# get_weight(): [0.5 0.4 0.3 0.2]
# num_col(): 3
# num_row(): 4
print(self._matrix2.slice([0, 1]).get_label())
# [1. 2.]
XGBoost模型接口
Booster
Booster 是xgboost 的模型,它包含了训练、预测、评估等任务的底层实现。
xbgoost.Booster(params=None,cache=(),model_file=None)
- params: 一个字典,给出了模型的参数。该Booster 将调用set_param(params) 方法来设置模型的参数。
- cache:一个列表,给出了缓存的项。其元素是DMatrix 的对象。模型从这些DMatrix 对象中读取特征名字和特征类型(要求这些DMatrix 对象具有相同的特征名字和特征类型)
- model_file: 一个字符串,给出了模型文件的位置。如果给出了model_file,则调用load_model(model_file) 来加载模型。
属性:通过方法来存取、设置属性。
- .attr(key): 获取booster 的属性。如果该属性不存在,则返回None参数:key: 一个字符串,表示要获取的属性的名字
- .set_attr(**kwargs): 设置booster 的属性。参数:kwargs: 关键字参数。注意:参数的值目前只支持字符串。如果参数的值为None,则表示删除该参数。
- .attributes(): 以字典的形式返回booster 的属性
- .set_param(params,value=None): 设置booster 的参数。参数:
- params:一个列表(元素为键值对)、一个字典、或者一个字符串。表示待设置的参数;
- value:如果params 为字符串,那么params 就是键,而value就是参数值。
- .boost(dtrain,grad,hess): 执行一次训练迭代。参数:
- dtrain:一个 DMatrix 对象,表示训练集
- grad:一个列表,表示一阶的梯度
- hess:一个列表,表示二阶的偏导数
- .update(dtrain,iteration,fobj=None):对一次迭代进行更新。参数:
- dtrain:一个 DMatrix 对象,表示训练集
- iteration:一个整数,表示当前的迭代步数编号
- fobj: 一个函数,表示自定义的目标函数。由于Booster 没有.train() 方法,因此需要用下面的策略进行迭代:
for i in range(0,100):
booster.update(train_matrix,iteration=i)
- .copy(): 拷贝当前的booster,并返回一个新的Booster 对象
- .dump_model(fout,fmap=”,with_stats=False): dump 模型到一个文本文件中。参数:
- fout: 一个字符串,表示输出文件的文件名;
- fmap: 一个字符串,表示存储feature map 的文件的文件名。booster 需要从它里面读取特征的信息,该文件每一行依次代表一个特征,每一行的格式为:feature name:feature type,其中feature type 为int、float 等表示数据类型的字符串;
- with_stats:一个布尔值。如果为True,则输出split 的统计信息。
- .get_dump(fmap=”,with_stats=False,dump_format=’text’): dump 模型为字符的列表(而不是存到文件中)。参数:dump_format: 一个字符串,给出了输出的格式。回值:一个字符串的列表。每个字符串描述了一棵子树。
- .eval(data,name=’eval’,iteration=0): 对模型进行评估。返回值:一个字符串,表示评估结果参数:
- data: 一个DMatrix 对象,表示数据集
- name: 一个字符串,表示数据集的名字
- iteration: 一个整数,表示当前的迭代编号
- .eval_set(evals,iteration=0,feval=None): 评估一系列的数据集。返回值:一个字符串,表示评估结果。参数:
- evals: 一个列表,列表元素为元组(DMatrix,string), 它给出了待评估的数据集
- iteration: 一个整数,表示当前的迭代编号
- feval: 一个函数,给出了自定义的评估函数
- .get_fscore(fmap=”): 返回每个特征的重要性。booster 需要从它里面读取特征的信息。返回值:一个字典,给出了每个特征的重要性
- .get_score(fmap=”,importance_type=’weight’): 返回每个特征的重要性。返回值:一个字典,给出了每个特征的重要性。参数:importance_type:一个字符串,给出了特征的衡量指标。可以为:
- ‘weight’: 此时特征重要性衡量标准为:该特征在所有的树中,被用于划分数据集的总次数。
- ‘gain’: 此时特征重要性衡量标准为:该特征在树的’cover’ 中,获取的平均增益。
- .get_split_value_histogram(feature,fmap=”,bins=None,as_pandas=True):获取一个特征的划分value histogram。返回值:以一个numpy ndarray 或者DataFrame 形式返回的、代表拆分点的histogram 的结果。参数:
- feature: 一个字符串,给出了划分特征的名字
- fmap:一个字符串,给出了feature map 文件的文件名。booster 需要从它里面读取特征的信息。
- bins: 最大的分桶的数量。如果bins=None 或者 bins>n_unique,则分桶的数量实际上等于n_unique。 其中 n_unique 是划分点的值的unique
- as_pandas :一个布尔值。如果为True,则返回一个DataFrame; 否则返回一个numpy ndarray。
- .load_model(fname): 从文件中加载模型。参数:fname: 一个文件或者一个内存buffer, xgboost 从它加载模型
- .save_model(fname): 保存模型到文件中。参数:fname: 一个字符串,表示文件名
- save_raw(): 将模型保存成内存buffer。返回值:一个内存buffer,代表该模型
- .load_rabit_checkpoint(): 从rabit checkpoint 中初始化模型。返回值:一个整数,表示模型的版本号
- .predict(data,output_margin=False,ntree_limit=0,pred_leaf=False,pred_contribs=False,approx_contribs=False): 执行预测。该方法不是线程安全的。对于每个booster来讲,你只能在某个线程中调用它的.predict 方法。如果你在多个线程中调用.predict 方法,则可能会有问题。要想解决该问题,你必须在每个线程中调用copy() 来拷贝该booster 到每个线程中。返回值:一个ndarray,表示预测结果。参数:
- data: 一个 DMatrix 对象,表示测试集
- output_margin: 一个布尔值。表示是否输出原始的、未经过转换的margin value
- ntree_limit: 一个整数。表示使用多少棵子树来预测。默认值为0,表示使用所有的子树。如果训练的时候发生了早停,则你可以使用best_ntree_limit。
- pred_leaf: 一个布尔值。如果为True,则会输出每个样本在每个子树的哪个叶子上。它是一个nsample x ntrees 的矩阵。每个子树的叶节点都是从1 开始编号的。
- pred_contribs: 一个布尔值。如果为True, 则输出每个特征对每个样本预测结果的贡献程度。它是一个nsample x ( nfeature+1) 的矩阵。之所以加1,是因为有bias 的因素。它位于最后一列。其中样本所有的贡献程度相加,就是该样本最终的预测的结果。
- approx_contribs: 一个布尔值。如果为True,则大致估算出每个特征的贡献程度。
Booster 没有 train 方法。因此有两种策略来获得训练好的 Booster
- 从训练好的模型的文件中.load_model() 来获取
- 多次调用.update() 方法
import xgboost as xgt
import pandas as pd
from sklearn.model_selection import train_test_split
_label_map = {
# 'Iris-setosa':0, #经过裁剪的,去掉了 iris 中的 setosa 类
'Iris-versicolor': 0,
'Iris-virginica': 1
}
class BoosterTest:
'''
测试 Booster
'''
def __init__(self):
df = pd.read_csv('./data/iris.csv')
_feature_names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']
x = df[_feature_names]
y = df['Class'].map(lambda x: _label_map[x])
train_X, test_X, train_Y, test_Y = train_test_split(x, y,
test_size=0.3, stratify=y, shuffle=True, random_state=1)
self._train_matrix = xgt.DMatrix(data=train_X, label=train_Y,
eature_names=_feature_names,
feature_types=['float', 'float', 'float', 'float'])
self._validate_matrix = xgt.DMatrix(data=test_X, label=test_Y,
feature_names=_feature_names,
feature_types=['float', 'float', 'float', 'float'])
self._booster = xgt.Booster(params={
'booster': 'gbtree',
'silent': 0, # 打印消息
'eta': 0.1, # 学习率
'max_depth': 5,
'tree_method': 'exact',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'seed': 321},
cache=[self._train_matrix, self._validate_matrix])
def test_attribute(self):
'''
测试属性的设置和获取
:return:
'''
self._booster.set_attr(key1='1')
print('attr:key1 -> ', self._booster.attr('key1'))
print('attr:key2 -> ', self._booster.attr('key2'))
print('attributes -> ', self._booster.attributes())
def test_dump_model(self):
'''
测试 dump 模型
:return:
'''
_dump_str = self._booster.get_dump(fmap='model/booster.feature',
with_stats=True, dump_format='text')
print('dump:', _dump_str[0][:20] + '...' if _dump_str else [])
self._booster.dump_model('model/booster.model',
fmap='model/booster.feature', with_stats=True)
def test_train(self):
'''
训练
:return:
'''
for i in range(0, 100):
self._booster.update(self._train_matrix, iteration=i)
print(self._booster.eval(self._train_matrix, name='train', iteration=i))
print(self._booster.eval(self._validate_matrix, name='eval', iteration=i))
def test_importance(self):
'''
测试特征重要性
:return:
'''
print('fscore:', self._booster.get_fscore('model/booster.feature'))
print('score.weight:', self._booster.get_score(importance_type='weight'))
print('score.gain:', self._booster.get_score(importance_type='gain'))
def test(self):
self.test_attribute()
# attr:key1 -> 1
# attr:key2 -> None
# attributes -> {'key1': '1'}
self.test_dump_model()
# dump: []
self.test_train()
# [0] train-auc:0.980816
# [0] eval-auc:0.933333
# ...
# [99] train-auc:0.998367
# [99] eval-auc:0.995556
self.test_dump_model()
# dump: 0:[f2<4.85] yes=1,no...
self.test_importance()
# score: {'f2': 80, 'f3': 72, 'f0': 6, 'f1': 5}
# score.weight: {'Petal Length': 80, 'Petal Width': 72, 'Sepal Length': 6, 'Sepal Width': 5}
# score.gain: {'Petal Length': 3.6525380337500004, 'Petal Width': 2.2072901486111114, 'Sepal Length': 0.06247816666666667, 'Sepal Width': 0.09243024}
if __name__ == '__main__':
BoosterTest().test()
xgboost.train(): 使用给定的参数来训练一个booster
xgboost.train(params, dtrain, num_boost_round=10, evals=(), obj=None, feval=None, maximize=False, early_stopping_rounds=None, evals_result=None, verbose_eval=True, xgb_model=None, callbacks=None, learning_rates=None)
- params: 一个列表(元素为键值对)、一个字典,表示训练的参数
- dtrain:一个DMatrix 对象,表示训练集
- num_boost_round: 一个整数,表示boosting 迭代数量
- evals: 一个列表,元素为(DMatrix,string)。 它给出了训练期间的验证集,以及验证集的名字(从而区分验证集的评估结果)。
- obj:一个函数,它表示自定义的目标函数
- feval: 一个函数,它表示自定义的evaluation 函数
- maximize: 一个布尔值。如果为True,则表示是对feval 求最大值;否则为求最小值
- early_stopping_rounds:一个整数,表示早停参数。如果在early_stopping_rounds 个迭代步内,验证集的验证误差没有下降,则训练停止。该参数要求evals 参数至少包含一个验证集。如果evals 参数包含了多个验证集,则使用最后的一个。返回的模型是最后一次迭代的模型(而不是最佳的模型)。如果早停发生,则模型拥有三个额外的字段:
- .best_score: 最佳的分数
- .best_iteration: 最佳的迭代步数
- .best_ntree_limit: 最佳的子模型数量
- evals_result: 一个字典,它给出了对测试集要进行评估的指标。
- verbose_eval: 一个布尔值或者整数。如果为True,则evalutation metric 将在每个boosting stage 打印出来。如果为一个整数,则evalutation metric 将在每隔verbose_eval个boosting stage 打印出来。另外最后一个boosting stage,以及早停的boosting stage 的 evalutation metric 也会被打印。
- learning_rates: 一个列表,给出了每个迭代步的学习率。你可以让学习率进行衰减。
- xgb_model: 一个Booster实例,或者一个存储了xgboost 模型的文件的文件名。它给出了待训练的模型。这种做法允许连续训练。
- callbacks: 一个回调函数的列表,它给出了在每个迭代步结束之后需要调用的那些函数。你可以使用xgboost 中预定义的一些回调函数(位于callback 模块) 。如:xgboost.reset_learning_rate(custom_rates)
返回值:一个Booster 对象,表示训练好的模型
xgboost.cv(): 使用给定的参数执行交叉验证 。它常用作参数搜索
xgboost.cv(params, dtrain, num_boost_round=10, nfold=3, stratified=False, folds=None,
metrics=(), obj=None, feval=None, maximize=False, early_stopping_rounds=None,
fpreproc=None, as_pandas=True, verbose_eval=None, show_stdv=True, seed=0,
callbacks=None, shuffle=True)
- params: 一个列表(元素为键值对)、一个字典,表示训练的参数
- dtrain:一个DMatrix 对象,表示训练集
- num_boost_round: 一个整数,表示boosting 迭代数量
- nfold: 一个整数,表示交叉验证的fold 的数量
- stratified: 一个布尔值。如果为True,则执行分层采样
- folds: 一个scikit-learn 的 KFold 实例或者StratifiedKFold 实例。
- metrics:一个字符串或者一个字符串的列表,指定了交叉验证时的evaluation metrics。如果同时在params 里指定了eval_metric,则metrics 参数优先。
- obj:一个函数,它表示自定义的目标函数
- feval: 一个函数,它表示自定义的evaluation 函数
- maximize: 一个布尔值。如果为True,则表示是对feval 求最大值;否则为求最小值
- early_stopping_rounds:一个整数,表示早停参数。如果在early_stopping_rounds 个迭代步内,验证集的验证误差没有下降,则训练停止。返回evaluation history 结果中的最后一项是最佳的迭代步的评估结果
- fpreproc: 一个函数。它是预处理函数,其参数为(dtrain,dtest,param), 返回值是经过了变换之后的 (dtrain,dtest,param)
- as_pandas: 一个布尔值。如果为True,则返回一个DataFrame ;否则返回一个numpy.ndarray
- verbose_eval: 参考train()
- show_stdv: 一个布尔值。是否verbose 中打印标准差。它对返回结果没有影响。返回结果始终包含标准差。
- seed: 一个整数,表示随机数种子
- callbacks: 参考train()
- shuffle: 一个布尔值。如果为True,则创建folds 之前先混洗数据。
返回值:一个字符串的列表,给出了evaluation history 。它给的是早停时刻的history(此时对应着最优模型),早停之后的结果被抛弃。
import xgboost as xgt
import pandas as pd
from sklearn.model_selection import train_test_split
_label_map = {
# 'Iris-setosa':0, #经过裁剪的,去掉了 iris 中的 setosa 类
'Iris-versicolor': 0,
'Iris-virginica': 1
}
class TrainTest:
def __init__(self):
df = pd.read_csv('./data/iris.csv')
_feature_names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']
x = df[_feature_names]
y = df['Class'].map(lambda x: _label_map[x])
train_X, test_X, train_Y, test_Y = train_test_split(x, y, test_size=0.3,
stratify=y, shuffle=True, random_state=1)
self._train_matrix = xgt.DMatrix(data=train_X, label=train_Y,
feature_names=_feature_names,
feature_types=['float', 'float', 'float', 'float'])
self._validate_matrix = xgt.DMatrix(data=test_X, label=test_Y,
feature_names=_feature_names,
feature_types=['float', 'float', 'float', 'float'])
def train_test(self):
params = {
'booster': 'gbtree',
'eta': 0.01,
'max_depth': 5,
'tree_method': 'exact',
'objective': 'binary:logistic',
'eval_metric': ['logloss', 'error', 'auc']
}
eval_rst = {}
booster = xgt.train(params, self._train_matrix, num_boost_round=20,
evals=([(self._train_matrix, 'valid1'), (self._validate_matrix, 'valid2')]),
early_stopping_rounds=5, evals_result=eval_rst, verbose_eval=True)
## 训练输出
# Multiple eval metrics have been passed: 'valid2-auc' will be used for early stopping.
# Will train until valid2-auc hasn't improved in 5 rounds.
# [0] valid1-logloss:0.685684 valid1-error:0.042857 valid1-auc:0.980816 valid2-logloss:0.685749 valid2-error:0.066667 valid2-auc:0.933333
# ...
# Stopping. Best iteration:
# [1] valid1-logloss:0.678149 valid1-error:0.042857 valid1-auc:0.99551 valid2-logloss:0.677882 valid2-error:0.066667 valid2-auc:0.966667
print('booster attributes:', booster.attributes())
# booster attributes: {'best_iteration': '1', 'best_msg': '[1]\tvalid1-logloss:0.678149\tvalid1-error:0.042857\tvalid1-auc:0.99551\tvalid2-logloss:0.677882\tvalid2-error:0.066667\tvalid2-auc:0.966667', 'best_score': '0.966667'}
print('fscore:', booster.get_fscore())
# fscore: {'Petal Length': 8, 'Petal Width': 7}
print('eval_rst:', eval_rst)
# eval_rst: {'valid1': {'logloss': [0.685684, 0.678149, 0.671075, 0.663787, 0.656948, 0.649895], 'error': [0.042857, 0.042857, 0.042857, 0.042857, 0.042857, 0.042857], 'auc': [0.980816, 0.99551, 0.99551, 0.99551, 0.99551, 0.99551]}, 'valid2': {'logloss': [0.685749, 0.677882, 0.670747, 0.663147, 0.656263, 0.648916], 'error': [0.066667, 0.066667, 0.066667, 0.066667, 0.066667, 0.066667], 'auc': [0.933333, 0.966667, 0.966667, 0.966667, 0.966667, 0.966667]}}
def cv_test(self):
params = {
'booster': 'gbtree',
'eta': 0.01,
'max_depth': 5,
'tree_method': 'exact',
'objective': 'binary:logistic',
'eval_metric': ['logloss', 'error', 'auc']
}
eval_history = xgt.cv(params, self._train_matrix, num_boost_round=20,
nfold=3, stratified=True, metrics=['error', 'auc'],
early_stopping_rounds=5, verbose_eval=True, shuffle=True)
## 训练输出
# [0] train-auc:0.974306+0.00309697 train-error:0.0428743+0.0177703 test-auc:0.887626+0.0695933 test-error:0.112374+0.0695933
# ....
print('eval_history:', eval_history)
# eval_history: test-auc-mean test-auc-std test-error-mean test-error-std \
# 0 0.887626 0.069593 0.112374 0.069593
# 1 0.925821 0.020752 0.112374 0.069593
# 2 0.925821 0.020752 0.098485 0.050631
# train-auc-mean train-auc-std train-error-mean train-error-std
# 0 0.974306 0.003097 0.042874 0.01777
# 1 0.987893 0.012337 0.042874 0.01777
# 2 0.986735 0.011871 0.042874 0.01777
Scikit-Learn API
xgboost 给出了针对scikit-learn 接口的API。
xgboost.XGBRegressor: 它实现了scikit-learn 的回归模型API
class xgboost.XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100,
silent=True, objective='reg:linear', booster='gbtree', n_jobs=1, nthread=None,
gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1,
colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)
- max_depth: 一个整数,表示子树的最大深度
- learning_rate: 一个浮点数,表示学习率
- n_estimators:一个整数,也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。
- silent: 一个布尔值。如果为False,则打印中间信息
- objective: 一个字符串或者可调用对象,指定了目标函数。其函数签名为:objective(y_true,y_pred) -> gra,hess。 其中:
- y_true: 一个形状为[n_sample] 的序列,表示真实的标签值
- y_pred: 一个形状为[n_sample] 的序列,表示预测的标签值
- grad: 一个形状为[n_sample] 的序列,表示每个样本处的梯度
- hess: 一个形状为[n_sample] 的序列,表示每个样本处的二阶偏导数
- booster: 一个字符串。指定了用哪一种基模型。可以为:’gbtree’,’gblinear’,’dart’
- n_jobs: 一个整数,指定了并行度,即开启多少个线程来训练。如果为-1,则使用所有的CPU
- gamma: 一个浮点数,也称作最小划分损失min_split_loss。 它刻画的是:对于一个叶子节点,当对它采取划分之后,损失函数的降低值的阈值。
- min_child_weight: 一个整数,子节点的权重阈值。它刻画的是:对于一个叶子节点,当对它采取划分之后,它的所有子节点的权重之和的阈值。
- max_delta_step: 一个整数,每棵树的权重估计时的最大delta step。取值范围为,0 表示没有限制,默认值为 0 。
- subsample:一个浮点数,对训练样本的采样比例。取值范围为 (0,1],默认值为 1 。如果为5, 表示随机使用一半的训练样本来训练子树。它有助于缓解过拟合。
- colsample_bytree: 一个浮点数,构建子树时,对特征的采样比例。取值范围为 (0,1], 默认值为 1。如果为5, 表示随机使用一半的特征来训练子树。它有助于缓解过拟合。
- colsample_bylevel: 一个浮点数,寻找划分点时,对特征的采样比例。取值范围为 (0,1], 默认值为 1。如果为5, 表示随机使用一半的特征来寻找最佳划分点。它有助于缓解过拟合。
- reg_alpha: 一个浮点数,是L1 正则化系数。它是xgb 的alpha 参数
- reg_lambda: 一个浮点数,是L2 正则化系数。它是xgb 的lambda 参数
- scale_pos_weight: 一个浮点数,用于调整正负样本的权重,常用于类别不平衡的分类问题。默认为 1。
- base_score:一个浮点数, 给所有样本的一个初始的预测得分。它引入了全局的bias
- random_state: 一个整数,表示随机数种子。
- missing: 一个浮点数,它的值代表发生了数据缺失。默认为nan
- kwargs: 一个字典,给出了关键字参数。它用于设置Booster 对象
xgboost.XGBClassifier :它实现了scikit-learn 的分类模型API
class xgboost.XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100,
silent=True, objective='binary:logistic', booster='gbtree', n_jobs=1,
nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1,
colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, base_score=0.5, random_state=0, seed=None,
missing=None, **kwargs)
参数参考xgboost.XGBRegressor
xgboost.XGBClassifier 和 xgboost.XGBRegressor 的方法:
- fit(X, y, sample_weight=None, eval_set=None, eval_metric=None,early_stopping_rounds=None,verbose=True, xgb_model=None) 训练模型
- X: 一个array-like,表示训练集
- y: 一个序列,表示标记
- sample_weight: 一个序列,给出了每个样本的权重
- eval_set: 一个列表,元素为(X,y),给出了验证集及其标签。它们用于早停。如果有多个验证集,则使用最后一个
- eval_metric: 一个字符串或者可调用对象,用于evaluation metric。如果为字符串,则是内置的度量函数的名字;如果为可调用对象,则它的签名为(y_pred,y_true)==>(str,value)
- early_stopping_rounds: 指定早停的次数。参考train()
- verbose: 一个布尔值。如果为True,则打印验证集的评估结果。
- xgb_model:一个Booster实例,或者一个存储了xgboost 模型的文件的文件名。它给出了待训练的模型。这种做法允许连续训练。
- predict(data, output_margin=False, ntree_limit=0) 执行预测
- data: 一个 DMatrix 对象,表示测试集
- output_margin: 一个布尔值。表示是否输出原始的、未经过转换的margin value
- ntree_limit: 一个整数。表示使用多少棵子树来预测。默认值为0,表示使用所有的子树。
- 如果训练的时候发生了早停,则你可以使用best_ntree_limit。
- .predict_proba(data, output_margin=False, ntree_limit=0) 执行预测,预测的是各类别的概率。它只用于分类问题,返回的是预测各类别的概率。参数:参考.predict()
- .evals_result(): 返回一个字典,给出了各个验证集在各个验证参数上的历史值。它不同于cv() 函数的返回值。cv() 函数返回evaluation history 是早停时刻的。而这里返回的是所有的历史值
import xgboost as xgt
import pandas as pd
from sklearn.model_selection import train_test_split
_label_map = {
# 'Iris-setosa':0, #经过裁剪的,去掉了 iris 中的 setosa 类
'Iris-versicolor': 0,
'Iris-virginica': 1
}
class SKLTest:
def __init__(self):
df = pd.read_csv('./data/iris.csv')
_feature_names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']
x = df[_feature_names]
y = df['Class'].map(lambda x: _label_map[x])
self.train_X, self.test_X, self.train_Y, self.test_Y = \
train_test_split(x, y, test_size=0.3, stratify=y, shuffle=True, random_state=1)
def train_test(self):
clf = xgt.XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100)
clf.fit(self.train_X, self.train_Y, eval_metric='auc',
eval_set=[(self.test_X, self.test_Y), ],
early_stopping_rounds=3)
# 训练输出:
# Will train until validation_0-auc hasn't improved in 3 rounds.
# [0] validation_0-auc:0.933333
# ...
# Stopping. Best iteration:
# [2] validation_0-auc:0.997778
print('evals_result:', clf.evals_result())
# evals_result: {'validation_0': {'auc': [0.933333, 0.966667, 0.997778, 0.997778, 0.997778]}}
print('predict:', clf.predict(self.test_X))
# predict: [1 1 0 0 0 1 1 1 0 0 0 1 1 0 1 1 0 1 0 0 0 0 0 1 1 0 0 1 1 0]
绘图API
xgboost.plot_importance():绘制特征重要性
xgboost.plot_importance(booster, ax=None, height=0.2, xlim=None, ylim=None,
title='Feature importance', xlabel='F score', ylabel='Features',
importance_type='weight', max_num_features=None, grid=True,
show_values=True, **kwargs)
- booster: 一个Booster对象, 一个 XGBModel 对象,或者由get_fscore() 返回的字典
- ax: 一个matplotlib Axes 对象。特征重要性将绘制在它上面。如果为None,则新建一个Axes
- grid: 一个布尔值。如果为True,则开启axes grid
- importance_type: 一个字符串,指定了特征重要性的类别。参考get_fscore()
- max_num_features: 一个整数,指定展示的特征的最大数量。如果为None,则展示所有的特征
- height: 一个浮点数,指定bar 的高度。它传递给barh()
- xlim: 一个元组,传递给xlim()
- ylim: 一个元组,传递给ylim()
- title: 一个字符串,设置Axes 的标题。默认为”Feature importance”。 如果为None,则没有标题
- xlabel: 一个字符串,设置Axes 的X 轴标题。默认为”F score”。 如果为None,则X 轴没有标题
- ylabel:一个字符串,设置Axes 的Y 轴标题。默认为”Features”。 如果为None,则Y 轴没有标题
- show_values: 一个布尔值。如果为True,则在绘图上展示具体的值。
- kwargs: 关键字参数,用于传递给barh()
xgboost.plot_tree(): 绘制指定的子树
xgboost.plot_tree(booster, fmap='', num_trees=0, rankdir='UT', ax=None, **kwargs)
- booster: 一个Booster对象, 一个 XGBModel 对象
- fmap: 一个字符串,给出了feature map 文件的文件名
- num_trees: 一个整数,制定了要绘制的子数的编号。默认为 0
- rankdir: 一个字符串,它传递给graphviz的graph_attr
- ax: 一个matplotlib Axes 对象。特征重要性将绘制在它上面。如果为None,则新建一个Axes
- kwargs: 关键字参数,用于传递给graphviz 的graph_attr
xgboost.to_graphviz(): 转换指定的子树成一个graphviz 实例
在IPython中,可以自动绘制graphviz 实例;否则你需要手动调用graphviz 对象的.render() 方法来绘制。
xgboost.to_graphviz(booster, fmap='', num_trees=0, rankdir='UT', yes_color='#0000FF',
no_color='#FF0000', **kwargs)
- yes_color: 一个字符串,给出了满足node condition 的边的颜色
- no_color: 一个字符串,给出了不满足node condition 的边的颜色
- 其它参数参考 plot_tree()
import xgboost as xgt
import pandas as pd
from sklearn.model_selection import train_test_split
from matplotlib.pylab import plot as plt
_label_map = {
# 'Iris-setosa':0, #经过裁剪的,去掉了 iris 中的 setosa 类
'Iris-versicolor': 0,
'Iris-virginica': 1
}
class PlotTest:
def __init__(self):
df = pd.read_csv('./data/iris.csv')
_feature_names = ['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width']
x = df[_feature_names]
y = df['Class'].map(lambda x: _label_map[x])
train_X, test_X, train_Y, test_Y = train_test_split(x, y,
test_size=0.3, stratify=y, shuffle=True, random_state=1)
self._train_matrix = xgt.DMatrix(data=train_X, label=train_Y,
feature_names=_feature_names,
feature_types=['float', 'float', 'float', 'float'])
self._validate_matrix = xgt.DMatrix(data=test_X, label=test_Y,
feature_names=_feature_names,
feature_types=['float', 'float', 'float', 'float'])
def plot_test(self):
params = {
'booster': 'gbtree',
'eta': 0.01,
'max_depth': 5,
'tree_method': 'exact',
'objective': 'binary:logistic',
'eval_metric': ['logloss', 'error', 'auc']
}
eval_rst = {}
booster = xgt.train(params, self._train_matrix,
num_boost_round=20, evals=([(self._train_matrix, 'valid1'),
(self._validate_matrix, 'valid2')]),
early_stopping_rounds=5, evals_result=eval_rst, verbose_eval=True)
xgt.plot_importance(booster)
plt.show()
XGBoost超参数调优实战
在对XGBoost进行优化调参的时候,使用的是Scikit-learn中sklearn.model_selection.GridSearchCV
常用参数解读:
- estimator:所使用的分类器,如果比赛中使用的是XGBoost的话,就是生成的model。比如: model = xgb.XGBRegressor(**other_params)
- param_grid:值为字典或者列表,即需要最优化的参数的取值。比如:cv_params = {‘n_estimators’: [550, 575, 600, 650, 675]}
- scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring=’roc_auc’,根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。scoring参数选择如下:
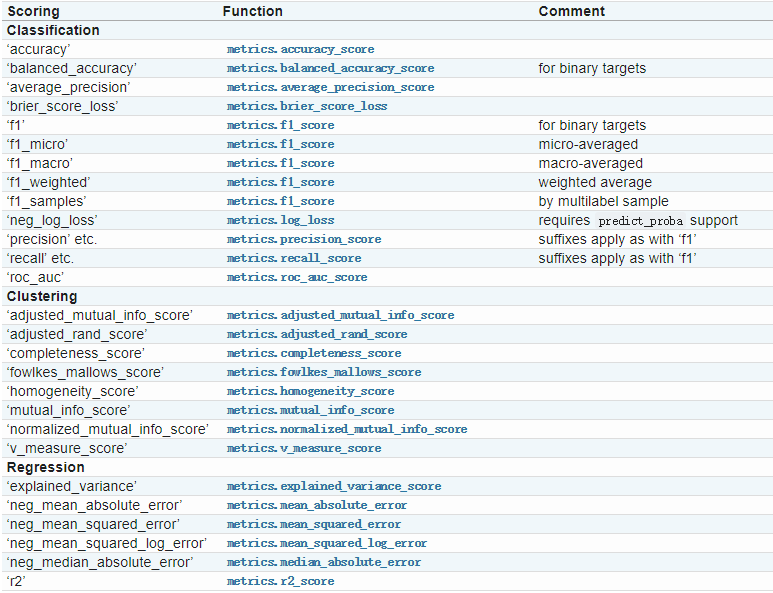
具体参考地址:http://scikit-learn.org/stable/modules/model_evaluation.html
演示时使用的r2这个得分函数,你也可以根据自己的实际需要来选择。调参刚开始的时候,一般要先初始化一些值:
- learning_rate: 0.1
- n_estimators: 500
- max_depth: 5
- min_child_weight: 1
- subsample: 0.8
- colsample_bytree:0.8
- gamma: 0
- reg_alpha: 0
- reg_lambda: 1
调参的时候一般按照以下顺序来进行:
1、最佳迭代次数:n_estimators
if __name__ == '__main__':
...
cv_params = {'n_estimators': [400, 500, 600, 700, 800]}
other_params = {'learning_rate': 0.1, 'n_estimators': 500, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
model = xgb.XGBRegressor(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.grid_scores_
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
运行后的结果为:
[Parallel(n_jobs=4)]: Done 25 out of 25 | elapsed: 1.5min finished
每轮迭代运行结果:[mean: 0.94051, std: 0.01244, params: {'n_estimators': 400}, mean: 0.94057, std: 0.01244, params: {'n_estimators': 500}, mean: 0.94061, std: 0.01230, params: {'n_estimators': 600}, mean: 0.94060, std: 0.01223, params: {'n_estimators': 700}, mean: 0.94058, std: 0.01231, params: {'n_estimators': 800}]
参数的最佳取值:{'n_estimators': 600}
最佳模型得分:0.9406056804545407
由输出结果可知最佳迭代次数为600次。但是,我们还不能认为这是最终的结果,由于设置的间隔太大,所以,我们又测试了一组参数,这次粒度小一些:
cv_params = {'n_estimators': [550, 575, 600, 650, 675]}
other_params = {'learning_rate': 0.1, 'n_estimators': 600, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
运行后最佳迭代次数变成了550。有人可能会问,那还要不要继续缩小粒度测试下去呢?这个可以看个人情况,如果你想要更高的精度,当然是粒度越小,结果越准确,大家可以自己慢慢去调试。
2、接下来要调试的参数是min_child_weight以及max_depth
注意:每次调完一个参数,要把 other_params对应的参数更新为最优值。
cv_params = {'max_depth': [3, 4, 5, 6, 7, 8, 9, 10], 'min_child_weight': [1, 2, 3, 4, 5, 6]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
运行后可知参数的最佳取值:{‘min_child_weight’: 5, ‘max_depth’: 4}。(代码输出结果被我省略了一部分,因为结果太长了,以下也是如此)
3、接着我们就开始调试参数:gamma
cv_params = {'gamma': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
由输出结果可知参数的最佳取值:{‘gamma’: 0.1}。
4、接着是subsample以及colsample_bytree
cv_params = {'subsample': [0.6, 0.7, 0.8, 0.9], 'colsample_bytree': [0.6, 0.7, 0.8, 0.9]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0.1, 'reg_alpha': 0, 'reg_lambda': 1}
运行后显示参数的最佳取值:{‘subsample’: 0.7,’colsample_bytree’: 0.7}
5、紧接着就是:reg_alpha以及reg_lambda
cv_params = {'reg_alpha': [0.05, 0.1, 1, 2, 3], 'reg_lambda': [0.05, 0.1, 1, 2, 3]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.7, 'colsample_bytree': 0.7, 'gamma': 0.1, 'reg_alpha': 0, 'reg_lambda': 1}
由输出结果可知参数的最佳取值:{‘reg_alpha’: 1, ‘reg_lambda’: 1}。
6、最后就是learning_rate,一般这时候要调小学习率来测试
cv_params = {'learning_rate': [0.01, 0.05, 0.07, 0.1, 0.2]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.7, 'colsample_bytree': 0.7, 'gamma': 0.1, 'reg_alpha': 1, 'reg_lambda': 1}
由输出结果可知参数的最佳取值:{‘learning_rate’: 0.1}。
我们可以很清楚地看到,随着参数的调优,最佳模型得分是不断提高的,这也从另一方面验证了调优确实是起到了一定的作用。不过,我们也可以注意到,其实最佳分数并没有提升太多。提醒一点,这个分数是根据前面设置的得分函数算出来的。
更多参考:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK