

Kubernetes网络和CNI
source link: http://just4coding.com/2020/07/25/kubernetes-cni/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Kubernetes网络和CNI
发表于
2020-07-25 分类于 Kubernetes
CNI: Container Network Interface是配置Linux容器网络接口的一种规范。它将容器运行时和容器网络实现解耦,使容器网络实现成为可插拔的插件。在不同的容器运行时环境中,容器网络实现可以复用。而在不同的网络环境中,也可以灵活的插拔不同的网络实现。
CNI规范主要涉及容器运行时和CNI插件两个角色,规范约定了二者的交互方式。容器运行时在容器实例创建时调用CNI插件的ADD接口以创建容器络连接所需的资源网络连接,当容器删除时调用CNI的DEL接口移除所创建的相应资源完成资源释放。不同的CNI插件按照规范所统一定义的接口、参数、响应实现不同的网络方案。
官方提供了开发库libcni,容器运行时可以使用该库来集成CNI能力,并且还提供了一系列的CNI插件参考实现。
目前CNI规范的最新版本为0.4.0。
从具体实现上看,容器运行时会先创建好相应的network namespace, 然后CNI插件负责将网络接口插入到容器实例的network namespace、在宿主机上做必要的网络操作(如绑定IP到接口、建立路由等)以实现容器网络连通。
一般设计中,主体模块与插件之间的交互会采用RPC、二进制兼容的动态库加载等手段。CNI规范则指定CNI插件实现为可执行程序,相应接口参数通过环境变量与标准输入流传给CNI插件,类似于早年WEB领域的CGI模式。
规范规定了如下操作:
ADD: 容器实例创建时,建立网络资源DEL: 容器实例销毁时,释放网络资源CHECK: 检查容器网络是否符合预期,这是0.4.0才引入的新接口VERSION: 返回版本信息
而通过环境变量来传递的参数有:
CNI_COMMAND: 所调用的操作,为ADD、DEL、CHECK、VERSIONCNI_CONTAINERID: 容器IDCNI_NETNS: 容器的network namespace文件的路径CNI_IFNAME: 容器网络接口的名称CNI_ARGS: 额外需要传递给CNI插件的参数,格式为以;分隔的Key/Value对,如”FOO=BAR;ABC=123“CNI_PATH:CNI插件的搜索路径
CNI规范还规定,容器网络实现所需的网络配置信息需要以JSON格式表达,容器运行时调用CNI插件时会将这些信息从插件进程的stdin输入, 格式为下:
{
"cniVersion": "0.4.0",
"name": "mynet",
"type": "bridge",
...
}
这三个参数是强制要求的:
cniVersion: 插件版本name: 网络名称type: 插件二进制文件名
其他参数是特定插件的自定义参数。
IPAM: IP Address Management是各种网络实现中相对独立的部分,因而CNI规范中将这部分以独立插件的形式进行约定。CNI插件可以调用各种不同的IPAM插件完成分配IP的操作。当前实现的有dhcp和host-local插件。
Kubernetes就是通过CNI机制来实现它的容器网络。Worker节点上的kubelet创建没有网络接口的容器后, 根据CNI网络配置文件来调用所指定的CNI插件完成容器网络的配置。
kublet会从参数--cni-conf-dir(默认值:/etc/cni/net.d)指定的目录中读取CNI网络配置文件, 然后从参数--cni-bin-dir(默认值:/opt/cni/bin)所指定的目录中找到CNI插件可执行程序进行调用。当有多个CNI网络配置时,kubelet会读取以字母顺序排序的第一个配置。
下面我们使用BASH来编写一个简单的CNI插件, 为了简单,我们基于0.3.1版本规范来实现。
Kubernetes网络模型的设计基于一个考虑:可以不做任何改变就将工作负载从虚拟机迁移到Kubernetes平台。因而它制定了三条基本原则:
- 所有
POD之间能够不经过NAT直接通信 - 所有
NODE能够不经过NAT与POD直接通信 POD内看到的IP与其他POD看到它的IP是一致的
在一个节点上实现满足这些条件的虚拟网络比较简单,较为复杂和困难的是在不同的节点之上构建满足这些约束的分布式网络。一般有两种方式:
Overlay: 通过隧道实现不同节点上的容器网络通信Underlay: 通过路由等实现容器网络通信
我们的CNI插件基于简单的静态路由配置实现容器网络通信。网络结构如图:
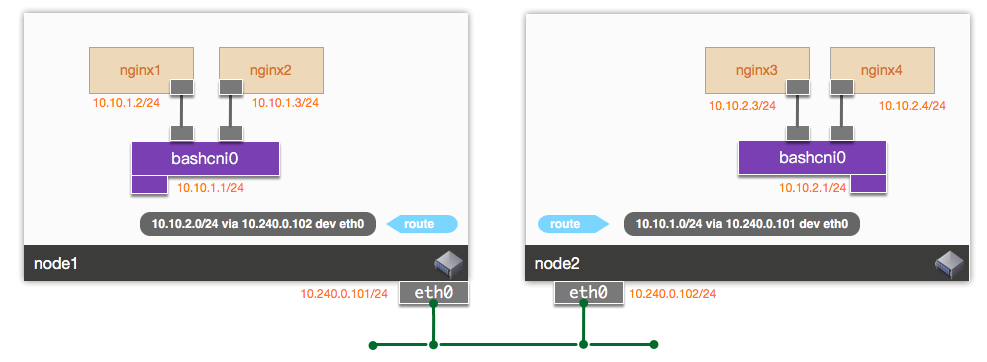
节点上创建一个Linux网桥bashcni0, 容器网络接口接口bashcni0上,三层接口bashcni0做为节点上容器网络的网关,节点之间通过静态路由实现容器网络数据包转发。
CNI插件可执行程序bash-cni代码如下:
#!/bin/bash -e
if [[ ${DEBUG} -gt 0 ]]; then set -x; fi
exec 3>&1 # make stdout available as fd 3 for the result
exec 1>> /var/log/bash-cni.log 2>&1
IP_STORE=/tmp/reserved_ips
VETH_STORE=/tmp/veth_index
stdin=`cat /dev/stdin`
log() {
echo "[$(date --rfc-3339=seconds)]: $*"
}
allocate_ip() {
for ip in "${all_ips[@]}"
do
reserved=false
for reserved_ip in "${reserved_ips[@]}"
do
if [ "$ip" = "$reserved_ip" ]; then
reserved=true
break
fi
done
if [ "$reserved" = false ]; then
echo "$ip" >> $IP_STORE
echo "$ip"
return
fi
done
}
case $CNI_COMMAND in
ADD)
log "CNI_COMMAND: $CNI_COMMAND CONTAINERID: $CNI_CONTAINERID NETNS: $CNI_NETNS IFNAME: $CNI_IFNAME"
network=$(echo $stdin | jq -r ".network")
log "NETWORK: $network"
subnet=$(echo $stdin | jq -r ".subnet")
log "SUBNET: $subnet"
subnet_mask_size=$(echo $subnet | awk -F "/" '{print $2}')
log "NETMASK: $subnet_mask_size"
all_ips=$(nmap -n -sL $subnet | grep "Nmap scan report" | awk '{print $NF}')
all_ips=(${all_ips[@]})
skip_ip=${all_ips[0]}
gw_ip=${all_ips[1]}
reserved_ips=$(cat $IP_STORE 2> /dev/null || printf "$skip_ip\n$gw_ip\n")
reserved_ips=(${reserved_ips[@]})
printf '%s\n' "${reserved_ips[@]}" > $IP_STORE
container_ip=$(allocate_ip)
mkdir -p /var/run/netns/
ln -sfT $CNI_NETNS /var/run/netns/$CNI_CONTAINERID
index=$(cat $VETH_STORE 2> /dev/null || printf "0\n")
host_if_name="veth$index"
temp_if_name="veth_c_$index"
log "HOST IFNAME: $host_if_name CONTAINERIP: $container_ip"
index=$((index + 1))
echo $index > $VETH_STORE
ip link add $temp_if_name type veth peer name $host_if_name
ip link set $host_if_name up
ip link set $host_if_name master bashcni0
ip link set $temp_if_name netns $CNI_CONTAINERID
ip netns exec $CNI_CONTAINERID ip link set $temp_if_name name $CNI_IFNAME
ip netns exec $CNI_CONTAINERID ip link set $CNI_IFNAME up
ip netns exec $CNI_CONTAINERID ip addr add $container_ip/$subnet_mask_size dev $CNI_IFNAME
ip netns exec $CNI_CONTAINERID ip route add default via $gw_ip dev $CNI_IFNAME
mac=$(ip netns exec $CNI_CONTAINERID ip link show $CNI_IFNAME | awk '/ether/ {print $2}')
echo "{
\"cniVersion\": \"0.3.1\",
\"interfaces\": [
{
\"name\": \"$CNI_IFNAME\",
\"mac\": \"$mac\",
\"sandbox\": \"$CNI_NETNS\"
}
],
\"ips\": [
{
\"version\": \"4\",
\"address\": \"$container_ip/$subnet_mask_size\",
\"gateway\": \"$gw_ip\",
\"interface\": 0
}
]
}" >&3
;;
DEL)
log "CNI_COMMAND: $CNI_COMMAND CONTAINERID: $CNI_CONTAINERID NETNS: $CNI_NETNS IFNAME: $CNI_IFNAME"
if [ -z "$CNI_NETNS" ]; then
exit
fi
ip=$(ip netns exec $CNI_CONTAINERID ip addr show $CNI_IFNAME | awk '/inet / {print $2}' | sed s%/.*%% || echo "")
if [ ! -z "$ip" ]
then
sed -i "/$ip/d" $IP_STORE
unlink /var/run/netns/$CNI_CONTAINERID
fi
;;
CHECK)
log "CNI_COMMAND: $CNI_COMMAND CONTAINERID: $CNI_CONTAINERID NETNS: $CNI_NETNS IFNAME: $CNI_IFNAME"
;;
VERSION)
log "CNI_COMMAND: $CNI_COMMAND CONTAINERID: $CNI_CONTAINERID NETNS: $CNI_NETNS IFNAME: $CNI_IFNAME"
echo '{
"cniVersion": "0.3.1",
"supportedVersions": [ "0.3.0", "0.3.1", "0.4.0"]
}' >&3
;;
*)
echo "Unknown cni command: $CNI_COMMAND"
exit
;;
esac
在ADD操作中,我们创建一对veth pair设备,一端接入bashcni0, 另一端放入容器的network namespace中。
我的实验环境为两个worker节点的Kubernetes集群。在两个节点上,将bash-cni程序放入/opt/cni/bin/目录下。
在两个节点上,在/etc/cni/net.d中写入文件00-bash-cni.conf, 内容分别如下:
{
"cniVersion": "0.3.1",
"name": "mynet",
"type": "bash-cni",
"network": "10.10.0.0/16",
"subnet": "10.10.1.0/24"
}
{
"cniVersion": "0.3.1",
"name": "mynet",
"type": "bash-cni",
"network": "10.10.0.0/16",
"subnet": "10.10.2.0/24"
}
两个节点各分配一个子网。将文件名以00开头是因为kubelet会从目录中以字母顺序读取配置文件。
接着,分别在两节点完成网桥创建与静态路由操作:
ip link add dev bashcni0 type bridge
ip link set up dev bashcni0
ip addr add 10.10.1.1/24 dev bashcni0
ip route add 10.10.2.0/24 via 10.240.0.102
ip link add dev bashcni0 type bridge
ip link set up dev bashcni0
ip addr add 10.10.2.1/24 dev bashcni0
ip route add 10.10.1.0/24 via 10.240.0.101
然后分别在每节点上创建两个pod:
[root@master1 ~]# kubectl apply -f nginx.yml
pod/nginx1 created
pod/nginx2 created
pod/nginx3 created
pod/nginx4 created
[root@master1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 18s
nginx2 1/1 Running 0 18s
nginx3 1/1 Running 0 18s
nginx4 1/1 Running 0 18s
nginx.yml代码如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx1
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
nodeSelector:
kubernetes.io/hostname: node1
---
apiVersion: v1
kind: Pod
metadata:
name: nginx2
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
nodeSelector:
kubernetes.io/hostname: node1
---
apiVersion: v1
kind: Pod
metadata:
name: nginx3
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
nodeSelector:
kubernetes.io/hostname: node2
---
apiVersion: v1
kind: Pod
metadata:
name: nginx4
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
nodeSelector:
kubernetes.io/hostname: node2
在node1上查看network namespace:
[root@node1 ~]# ip netns
3860f40d9c4fa78726bbd64963717f72389df8377406c5a7c7602d7cbdda4e3e (id: 1)
2dc473f08ebf516ac9de7e2f90212bc5814a15354a72db8d4ba93bb69189bd7b (id: 0)
cni-09556e7a-9c65-1f07-e7e3-b507b5497bff (id: 1)
cni-a119e178-7853-df56-86a1-1ebcac565ca4 (id: 0)
查看nginx1的IP,为10.10.1.2:
[root@node1 ~]# ip netns exec 2dc473f08ebf516ac9de7e2f90212bc5814a15354a72db8d4ba93bb69189bd7b ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
16: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether aa:2d:38:3d:83:79 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.1.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a82d:38ff:fe3d:8379/64 scope link
valid_lft forever preferred_lft forever
查看node2上nginx3的IP,为:10.10.2.3:
[root@node2 ~]# ip netns exec b6ba2fefdac62fe2730aa77a3a4aae415cdd5c2186716463910c20c5602ea27c ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
16: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d2:39:4f:ae:0e:b5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.2.3/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::d039:4fff:feae:eb5/64 scope link
valid_lft forever preferred_lft forever
我们从10.10.1.2访问10.10.2.3, 访问成功:
[root@node1 ~]# ip netns exec 2dc473f08ebf516ac9de7e2f90212bc5814a15354a72db8d4ba93bb69189bd7b ping -c 2 10.10.2.3
PING 10.10.2.3 (10.10.2.3) 56(84) bytes of data.
64 bytes from 10.10.2.3: icmp_seq=1 ttl=62 time=1.68 ms
64 bytes from 10.10.2.3: icmp_seq=2 ttl=62 time=0.611 ms
--- 10.10.2.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.611/1.146/1.681/0.535 ms
上边的步骤中,CNI可执行程序和配置文件的部署,网桥创建、静态路由配置都是手动执行完成。在实现生产可用的CNI插件时,一般可以使用Daemonset方式在每个节点上完成上述的环境初始化工作及程序配置安装。
可以简单的把上述步骤用BASH实现, install-cni.sh代码如下:
#!/bin/sh
set -x;
if [ -w "/host/opt/cni/bin/" ]; then
cp /opt/cni/bin/bash-cni /host/opt/cni/bin/;
echo "Wrote CNI binaries to /host/opt/cni/bin/";
fi;
sysctl -w net.ipv4.ip_forward=1
ip link add dev bashcni0 type bridge
ip link set up dev bashcni0
HOSTNAME=$(hostname -s)
case $HOSTNAME in
node1)
SUBNET='10.10.1.0/24'
ip addr add 10.10.1.1/24 dev bashcni0
ip route add 10.10.2.0/24 via 10.240.0.102
;;
node2)
SUBNET='10.10.2.0/24'
ip addr add 10.10.2.1/24 dev bashcni0
ip route add 10.10.1.0/24 via 10.240.0.101
;;
esac
TMP_CONF='/tmp/00-bash-cni.conf'
echo "{
\"cniVersion\": \"0.3.1\",
\"name\": \"mynet\",
\"type\": \"bash-cni\",
\"subnet\": \"$SUBNET\"
}" >$TMP_CONF
CNI_CONF_NAME="${CNI_CONF_NAME:-00-bash-cni.conf}"
mv $TMP_CONF /host/etc/cni/net.d/${CNI_CONF_NAME}
echo "Wrote CNI config: $(cat /host/etc/cni/net.d/${CNI_CONF_NAME})"
while :; do sleep 3600; done;
可以将这个文件构造成docker镜像, 用如下的YAML文件创建Daemonset实现各个节点的CNI插件部署。
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: bash-cni
namespace: kube-system
labels:
tier: node
k8s-app: bash-cni
spec:
template:
metadata:
labels:
tier: node
k8s-app: bash-cni
spec:
containers:
- name: install-cni
image: flygoast/bash-cni:0.0.3
imagePullPolicy: IfNotPresent
command: ["/install-cni.sh"]
volumeMounts:
- name: cni
mountPath: /host/etc/cni/net.d
- name: host-cni-bin
mountPath: /host/opt/cni/bin/
hostNetwork: true
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
volumes:
- name: cni
hostPath:
path: /etc/cni/net.d
- name: host-cni-bin
hostPath:
path: /opt/cni/bin
updateStrategy:
rollingUpdate:
maxUnavailable: 1
type: RollingUpdate
本文只是用于实验CNI规范的目的,如果需要实现一个生产使用的CNI插件,最好还是参考官方的框架与示例来实现:
参考链接:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK