

如何揪出网站上的网络爬虫:指纹识别
source link: https://zmister.com/archives/1604.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
如何揪出网站上的网络爬虫:指纹识别
网络上的爬虫日益猖獗,疯狂地采集网站上的内容,不仅没有带来一丝好处,反而导致内容的流失、增大服务器的压力。
在众多的访问者中识别出网络爬虫并限制其访问一直是各个网站运营者所关心和头疼的事情。
州的先生一直以来持有的观点就是,网络爬虫的反爬与反反爬,会像网络安全的黑客攻防一样,在你强化一步,我突破一步的节奏中不断升级和完善。没有哪一个反爬手段是一劳永逸的,也没有哪一个反反爬技术可以一招鲜吃遍天。
如果有,可能就是网站招安了爬虫,爬虫收购了网站。
在现行的网络爬虫检测技术中,主要有以下两大类:
行为检测是通过分析网页上用户的操作(鼠标的移动、点击、滚动行为和浏览行为)来判断操作者是否是机器控制的网络爬虫。
而指纹识别则是通过分析设备和浏览器的信息来判断访问者是否为网络爬虫。
行为检测要是深入展开来谈可以说上几天几夜,在此不表。
本文,主要介绍指纹识别的检测。
每一台电脑、每一个操作系统、每一个浏览器,都有属于它自己的设备信息。比如电脑的CPU数量、显卡型号、操作系统的位数、浏览器的版本等。
将这些设备信息加以组合,就可以作为请求者的指纹来进行识别。比如,一个Windows的浏览器,显示的却是Linux的操作系统,没问题就有鬼了。
再比如,用 Python 的小伙伴很喜欢使用的 Selenium,其会在浏览器中带上webdriver的标记,而这个标记,是正常的浏览器所没有的。
在 Github 上,有大神开源了一套浏览器指纹收集和识别的项目——fp-collect和fpscanner。
通过fp-collect,我们可以收集获取到当前访问者的浏览器指纹;通过fpscanner,我们可以判断浏览器的某一项指纹是否可疑。
fp-collect是一个 JavaScript 文件,放置在网页中加载,当访问者访问网页时,就可以获取到浏览器的指纹信息。
在此举一小例来演示:
例如,我们创建一个如下所示的HTML页面:
<html>
<script src="./fpCollect.min.js"></script>
<script>
fpCollect.generateFingerprint().then((fingerprint) => {
console.log(fingerprint)
});
</script>
</html>
当我们访问这个网页时,在控制台就可以看到我们的浏览器指纹。
下面我们分别用正常的浏览器和 Selenium 驱动的 Chrome 访问上述HTML页面:
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"E:\driver\chromedriver.exe")
driver.get("file:///F:/fp-collect/fp-collect.html")
最终对比两个浏览器的控制台输出的值,可以清晰地看到,Selenium 驱动的 Chrome 浏览器被识别出使用了 webdriver:
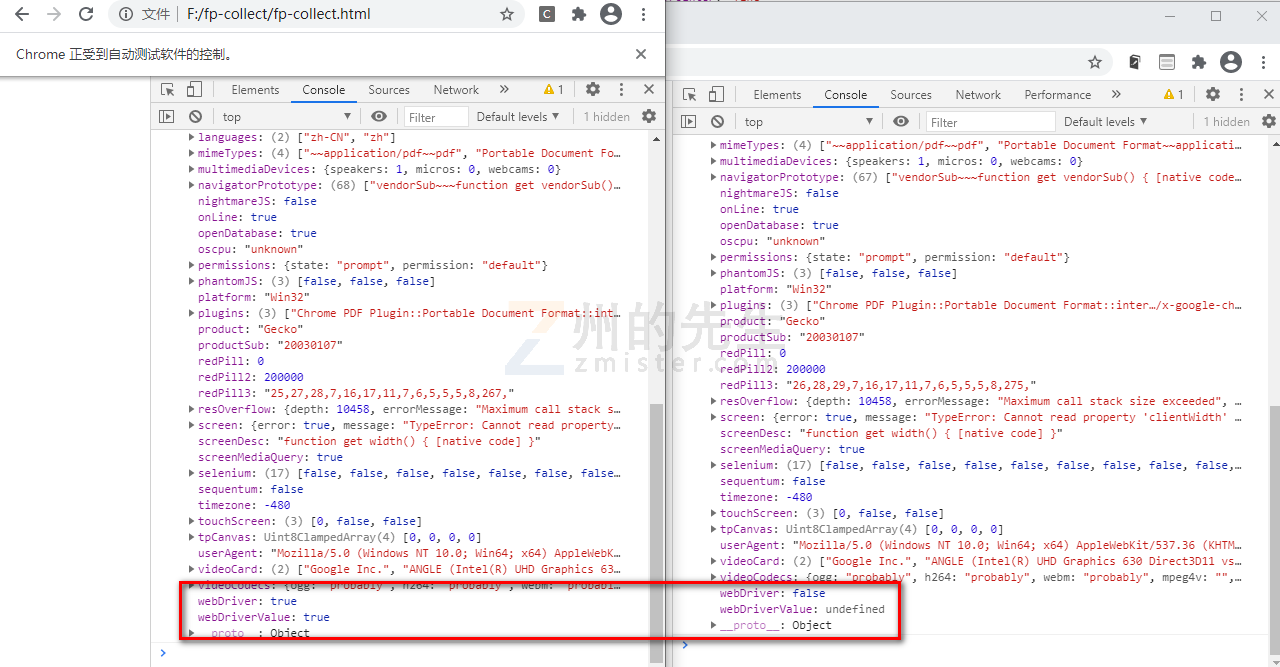
在此我们还没有使用fpscanner对浏览器的其他指纹进行识别。
fpscanner会对传入的浏览器指纹项进行识别和判断,最终给出三个结果:
- 一致:表示为检测到任何可疑;
- 不确定:表示检测的指纹可以是爬虫,也有可能不是爬虫;
- 不一致:表示检测的指纹是爬虫;
fpscanner的使用在此就不做演示,有兴趣的小伙伴可以自行试验一下。
如同文章开头所说的,爬虫攻防是一个持续性相互较量的过程,爬虫当然不会白白的把自己的真实指纹暴露出来。
在 Selenium 中 通过execute_cdp_cmd()方法,也能够将webdriver标记给去除掉。
虽然指纹识别有被攻破和绕过的可能,但是指纹识别相较于行为检测,可以比较快速地对访问者做出识别和判断,将那些看了几篇教程就撸起袖子一通乱干的爬虫死死地摁在地上。
就像一场战役的胜利,不仅仅是某一兵种的付出一样。网站的爬虫防御,也需要各个环节的配合和努力。指纹识别类似于静态检测,而行为识别则是动态检测,动静结合,方是长久。
当然,最长久之计还是:网站招安了爬虫,爬虫收购了网站。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK