

The Lean Theorem Prover | Homotopy Type Theory
source link: https://homotopytypetheory.org/2015/12/02/the-proof-assistant-lean/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

The Lean Theorem Prover
Lean is a new player in the field of proof assistants for Homotopy Type Theory. It is being developed by Leonardo de Moura working at Microsoft Research, and it is still under active development for the foreseeable future. The code is open source, and available on Github.
You can install it on Windows, OS X or Linux. It will come with a useful mode for Emacs, with syntax highlighting, on-the-fly syntax checking, autocompletion and many other features. There is also an online version of Lean which you can try in your browser. The on-line version is quite a bit slower than the native version and it takes a little while to load, but it is still useful to try out small code snippets. You are invited to test the code snippets in this post in the on-line version. You can run code by pressing shift+enter.
In this post I’ll first say more about the Lean proof assistant, and then talk about the considerations for the HoTT library of Lean (Lean has two libraries, the standard library and the HoTT library). I will also cover our approach to higher inductive types. Since Lean is not mature yet, things mentioned below can change in the future.
Update January 2017: the newest version of Lean currently doesn’t support HoTT, but there is a frozen version which does support HoTT. The newest version is available here, and the frozen version is available here. To use the frozen version, you will have to compile it from the source code yourself.
Examples
First let’s go through some examples. Don’t worry if you don’t fully understand these examples for now, I’ll go over the features in more detail below. You can use the commands check, print and eval to ask Lean for information. I will give the output as a comment, which is a double dash in Lean. check just gives the type of an expression.
check Σ(x y : ℕ), x + 5 = y-- Σ (x y : ℕ), x + 5 = y : Type₀This states that this sigma-type lives in the lowest universe in Lean (since ℕ and le live in the lowest universe). Unicode can be input (in both the browser version and the Emacs version) using a backslash. For example Σ is input by \Sigma or \S. In the browser version you have to hit space to convert it to Unicode.
check is useful to see the type of a theorem (the curly braces indicate that those arguments are implicit).
check @nat.le_trans-- nat.le_trans : Π {n m k : ℕ}, n ≤ m → m ≤ k → n ≤ kprint can show definitions.
open eqprint inverse-- definition eq.inverse : Π {A : Type} {x y : A}, x = y → y = x :=-- λ (A : Type) (x : A), eq.rec (refl x)It prints which notation uses a particular symbol.
print ×-- _ `×`:35 _:34 := prod #1 #0And it prints inductive definitions.
print bool-- inductive bool : Type₀-- constructors:-- bool.ff : bool-- bool.tt : booleval evaluates an expression.
eval (5 + 3 : ℕ)-- 8The Kernel
Lean is a proof assistant with as logic dependent type theory with inductive types and universes, just as Coq and Agda. It has a small kernel, which implements only the following components:
- Dependent lambda calculus
- Universe polymorphism in a hierarchy of
many universe levels
- Inductive types and inductive families of types, generating only the recursor for an inductive type.
In particular it does not contain
- A Termination checker
- Fixpoint operators
- Pattern matching
- Module management and overloading
Let’s discuss the above features in more detail. The function types are exactly as in the book with judgemental beta and eta rules. There are a lot of different notations for functions and function types, for example
open natvariables (A B : Type) (P : A → Type)(Q : A → B → Type) (f : A → A)check A -> Bcheck ℕ → ℕcheck Π (a : A), P acheck Pi a, P acheck ∀a b, Q a bcheck λ(n : ℕ), 2 * n + 3check fun a, f (f a)Lean supports universe polymorphism. So if you define the identity function as follows
definition my_id {A : Type} (a : A) : A := ayou actually get a function my_id.{u} for every universe u. You rarely have to write universes explicitly, but you can always give them explicitly if you want. For example:
definition my_id.{u} {A : Type.{u}} (a : A) : A := aset_option pp.universes truecheck sum.{7 5}-- sum.{7 5} : Type.{7} → Type.{5} → Type.{7}The universes in Lean are not cumulative. However, with universe polymorphism universe cumulativity is rarely needed. In the cases where you would use universe cumulativity you can use the lift map explicitly. There are only a handful of definitions or theorems (less than 10) currently in the HoTT library where lifts are needed (if it is not proving something about lifts itself). Some examples:
- In the proof that univalence implies function extensionality;
- In the proof that
Type.{u}is not a set, given thatType.{0}is not a set; - In the Yoneda Lemma;
- In the characterization of equality in sum types (see below for the pattern matching notation):
open sumdefinition sum.code.{u v} {A : Type.{u}}{B : Type.{v}} : A + B → A + B → Type.{max u v}| sum.code (inl a) (inl a') := lift (a = a')| sum.code (inr b) (inr b') := lift (b = b')| sum.code _ _ := lift empty
The first two examples only need lifts because we also decided that inductive types without parameters (empty, unit, bool, nat, etc.) should live in the lowest universe, instead of being universe polymorphic.
Lastly, the kernel contains inductive types. The syntax to declare them is very similar to Coq’s. For example, you can write
inductive my_nat :=| zero : my_nat| succ : my_nat → my_natwhich defines the natural numbers. This gives the type my_nat with two constructors my_nat.zero and my_nat.succ, a dependent recursor my_nat.rec and two computation rules.
Lean also automatically defines a couple of other useful definitions, like the injectivity of the constructors, but this is done outside the kernel (for a full list you can execute print prefix my_nat if you’ve installed Lean). Lean supports inductive families and mutually defined inductive types, but not induction-induction or induction-recursion.
There is special support for structures – inductive types with only one constructor. For these the projections are automatically generated, and we can extend structures with additional fields. This is also implemented outside the kernel. In the following example we extend the structure of groups to the structure of abelian groups.
import algebra.groupopen algebrastructure my_abelian_group (A : Type) extends group A :=(mul_comm : ∀a b, mul a b = mul b a)print my_abelian_groupcheck @my_abelian_group.to_group-- abelian_group.to_group : Π {A : Type}, abelian_group A → group AThe result is a structure with all the fields of group, but with one additional field. Also, the coercion from abelian_group to group is automatically defined.
The Lean kernel can be instantiated in multiple ways. There is a standard mode where the lowest universe Prop is impredicative and has proof irrelevance. The standard mode also has built-in quotient types. Secondly, there is the HoTT mode without impredicative or proof irrelevant universes. The HoTT mode also has some support for HITs; see below.
Elaboration
On top of the kernel there is a powerful elaboration engine which
- Infers implicit universe variables
- Infers implicit arguments, using higher order unification
- Supports overloaded notation or declarations
- Inserts coercions
- Infers implicit arguments using type classes
- Convert readable proofs to proof terms
- Constructs terms using tactics
It does most of these things simultaneously, for example it can use the term constructed by type classes to find out implicit arguments for functions.
Let’s run through the above list in more detail.
1. As said before, universe variables are rarely needed explicitly, usually only in cases where it would be ambiguous when you don’t give them (for example sum.code as defined above could also live in Type.{(max u v)+3} if the universe levels were not given explicitly).
2. As in Coq and Agda, we can use binders with curly braces {...} to indicate which arguments are left implicit. For example with the identity function above, if we write id (3 + 4) this will be interpreted as @id _ (3 + 4). Then the placeholder _ will be filled by the elaborator to get @id ℕ (3 + 4). Lean also supports higher order unification. This allows, for example, to leave the type family of a transport implicit. For example (▸ denotes transport):
open eqvariables (A : Type) (R : A → A → Type)variables (a b c : A) (f : A → A → A)example (r : R (f a a) (f a a)) (p : a = b): R (f a b) (f b a) :=p ▸ rOr the following lemma about transport in sigma-types:
open sigma sigma.ops eqvariables {A : Type} {B : A → Type}{C : Πa, B a → Type} {a₁ a₂ : A}definition my_sigma_transport (p : a₁ = a₂)(x : Σ(b : B a₁), C a₁ b): p ▸ x = ⟨p ▸ x.1, p ▸D x.2⟩ :=eq.rec (sigma.rec (λb c, idp) x) pset_option pp.notation falsecheck @my_sigma_transport-- my_sigma_transport :-- Π {A : Type} {B : A → Type} {C : Π (a : A), B a → Type} {a₁ a₂ : A} (p : eq a₁ a₂) (x : sigma (C a₁)),-- eq (transport (λ (a : A), sigma (C a)) p x) (dpair (transport B p (pr₁ x)) (transportD C p (pr₁ x) (pr₂ x)))Here the first transport is along the type family λa, Σ(b : B a), C a b. The second transport is along the type family B and the p ▸D is a dependent transport which is a map C a₁ b → C a₂ (p ▸ b). The check command shows these type families. Also in the proof we don’t have to give the type family of the inductions eq.rec and sigma.rec explicitly. However, for nested inductions higher-order unification becomes expensive quickly, and it is better to use pattern matching or the induction tactic, discussed below.
3&4 Lean supports overloading and coercions. Some examples:
open eq is_equiv equiv equiv.opsexample {A B : Type} (f : A ≃ B) {a : A} {b : B}(p : f⁻¹ b = a) : f a = b :=(eq_of_inv_eq p)⁻¹In this example f is in the type of equivalences between A and B and is coerced into the function type. Also, ⁻¹ is overloaded to mean both function inverse and path inverse.
5. Lean has type classes, similar to Coq’s and Agda’s, but in Lean they are very tightly integrated into the elaboration process. We use type class inference for inverses of functions. We can write f⁻¹ for an equivalence f : A → B, and then Lean will automatically try to find an instance of type is_equiv f.
Here’s an example, where we prove that the type of natural transformations between two functors is a set.
import algebra.category.nat_transopen category functor is_truncexample {C D : Precategory} (F G : C ⇒ D): is_hset (nat_trans F G) :=is_trunc_equiv_closed 0 !nat_trans.sigma_charIn the proof we only have to show that the type of natural transformation is equivalent to a sigma-type (nat_trans.sigma_char) and that truncatedness respects equivalences (is_trunc_equiv_closed). The fact that the sigma-type is a set is then inferred by type class resolution.
The brackets [...] specify that that argument is inferred by type class inference.
6. There are multiple ways to write readable proofs in Lean, which are then converted to proof terms by the elaborator. One thing you can do is define functions using pattern matching. We already saw an example above with sum.code. In contrast to Coq and Agda, these expressions are not part of the kernel. Instead, they are ‘compiled down’ to basic recursors, keeping Lean’s kernel simple, safe, and, well, ‘lean.’ Here is a simple example. The print command shows how inv is defined internally.
open eqdefinition my_inv {A : Type} : Π{a b : A}, a = b → b = a| my_inv (idpath a) := idpath aprint my_inv-- definition my_inv : Π {A : Type} {a b : A}, a = b → b = a :=-- λ (A : Type) {a b : A} (a_1 : a = b), eq.cases_on a_1 (idpath a)Here are some neat examples with vectors.
open natinductive vector (A : Type) : ℕ → Type :=| nil {} : vector A zero| cons : Π {n}, A → vector A n → vector A (succ n)open vector-- some notation. The second line allows us to use-- [1, 3, 10] as notation for vectorsnotation a :: b := cons a bnotation `[` l:(foldr `,` (h t, cons h t) nil `]`) := lvariables {A B : Type}definition map (f : A → B): Π {n : ℕ}, vector A n → vector B n| map [] := []| map (a::v) := f a :: map vdefinition tail: Π {n : ℕ}, vector A (succ n) → vector A n| n (a::v) := v-- no need to specify "tail nil", because that case is-- excluded because of the type of taildefinition diag: Π{n : ℕ}, vector (vector A n) n → vector A n| diag nil := nil| diag ((a :: v) :: M) := a :: diag (map tail M)-- no need to specify "diag (nil :: M)"eval diag [[(1 : ℕ), 2, 3],[4, 5, 6],[7, 8, 9]]-- we need to specify that these are natural numbers-- [1,5,9]You can use calculations in proofs, for example in the following construction of the composition of two natural transformations:
import algebra.categoryopen category functor nat_transvariables {C D : Precategory} {F G H : C ⇒ D}definition nt.compose (η : G ⟹ H) (θ : F ⟹ G): F ⟹ H :=nat_trans.mk(λ a, η a ∘ θ a)(λ a b f,calc H f ∘ (η a ∘ θ a)= (H f ∘ η a) ∘ θ a : by rewrite assoc... = (η b ∘ G f) ∘ θ a : by rewrite naturality... = η b ∘ (G f ∘ θ a) : by rewrite assoc... = η b ∘ (θ b ∘ F f) : by rewrite naturality... = (η b ∘ θ b) ∘ F f : by rewrite assoc)There are various notations for using forward reasoning. For example the following proof is from the standard library. In the proof below we use the notation `p > 0`, which is interpreted as the inhabitant of the type p > 0 in the current context. We also use the keyword this, which is the name term constructed by the previous unnamed have expression.
definition infinite_primes (n : nat) : {p | p ≥ n ∧ prime p} :=let m := fact (n + 1) inhave m ≥ 1, from le_of_lt_succ (succ_lt_succ (fact_pos _)),have m + 1 ≥ 2, from succ_le_succ this,obtain p `prime p` `p ∣ m + 1`, from sub_prime_and_dvd this,have p ≥ 2, from ge_two_of_prime `prime p`,have p > 0, from lt_of_succ_lt (lt_of_succ_le `p ≥ 2`),have p ≥ n, from by_contradiction(suppose ¬ p ≥ n,have p < n, from lt_of_not_ge this, have p ≤ n + 1, from le_of_lt (lt.step this), have p ∣ m, from dvd_fact `p > 0` this,have p ∣ 1, from dvd_of_dvd_add_right (!add.comm ▸ `p ∣ m + 1`) this,have p ≤ 1, from le_of_dvd zero_lt_one this,absurd (le.trans `2 ≤ p` `p ≤ 1`) dec_trivial),subtype.tag p (and.intro this `prime p`)7. Lean has a tactic language, just as Coq. You can write
begin...tactics...endanywhere in a term to synthesize that subterm with tactics. You can also use by *tactic* to apply a single tactic (which we used in the above calculation proof). The type of the subterm you want to synthesize is the goal and you can use tactics to solve the goal or apply backwards reasoning on the goal. For example if the goal is f x = f y you can use the tactic apply ap f to reduce the goal to x = y. Another tactic is the exact tactic, which means you give the term explicitly.
The proof language offers various mechanisms to pass back and forth between the two modes. You can begin using tactics anywhere a proof term is expected, and, conversely, you can enter structured proof terms while in tactic mode using the exact tactic.
A very simple tactic proof is
open eqvariables {A B C : Type} {a a' : A}example (g : B → C) (f : A → B) (p : a = a'): g (f a) = g (f a') :=beginapply ap g,apply ap f,exact pendwhich produces the proof term ap g (ap f p). In the Emacs mode of Lean you can see the intermediate goals by moving your cursor to the desired location and pressing Ctrl-C Ctrl-G
Lean has too many tactics to discuss here, although not as many as Coq. Here are some neat examples of tactics in Lean.
The cases tactic can be used to destruct a term of an inductive type. In the following examples, it destructs the path p to reflexivity. In the second example it uses that succ is injective, since it is the constructor of nat, so that it can still destruct p. It also doesn’t matter whether the free variable is on the left hand side or the right hand side of the equality. In the last example it uses that different constructors of an inductive type cannot be equal.
open nat eqexample {A : Type} {x y : A} (p : x = y) : idp ⬝ p = p :=begin cases p, reflexivity endexample (n m l : ℕ) (p : succ n = succ (m + l)): n = m + l :=begin cases p; reflexivity endexample (n : ℕ) (p : succ n = 0) : empty :=by cases pThe rewrite tactic is useful for doing a lot of rewrite rules. It is modeled after the rewrite tactic in SSReflect. For example in the following proof of Eckmann-Hilton we rewrite the goal 4 times with theorems to solve the goal. The notation ▸* simplifies the goal similar to Coq’s simpl, and -H means to rewrite using H⁻¹.
open eqtheorem eckmann_hilton {A : Type} {a : A}(p q : idp = idp :> a = a) : p ⬝ q = q ⬝ p :=beginrewrite [-whisker_right_idp p, -whisker_left_idp q, ▸*,idp_con, whisker_right_con_whisker_left p q]endThe induction tactic performs induction. For example if the goal is P n for a natural number n (which need not be a variable), then you can use induction n to obtain the two goals P 0 and P (k + 1) assuming P k. What’s really neat is that it supports user-defined recursors. So you can define the recursor of a HIT, tag it with the [recursor] attribute, and then it can be used for the induction tactic. Even more: you can arrange it in such a way that it uses the nondependent recursion principle whenever possible, and otherwise the dependent recursion principle.
import homotopy.circle types.intopen circle equiv int eq pidefinition circle_code (x : S¹) : Type₀ :=begininduction x, -- uses the nondependent recursor{ exact ℤ},{ apply ua, exact equiv_succ}-- equiv_succ : ℤ ≃ ℤ with underlying function succenddefinition transport_circle_code_loop (a : ℤ): transport circle_code loop a = succ a :=ap10 !elim_type_loop a-- ! is the "dual" of @, i.e. it inserts-- placeholders for explicit argumentsdefinition circle_decode {x : S¹}: circle_code x → base = x :=begininduction x, -- uses the dependent recursor{ exact power loop},{ apply arrow_pathover_left, intro b,apply concato_eq, apply pathover_eq_r,rewrite [power_con,transport_circle_code_loop]}endIn the future there will be more tactics, providing powerful automation such as a simplifier and a tableaux theorem prover.
The HoTT Library
I’ve been extensively working this year on the HoTT library of Lean, with the help of Jakob von Raumer and Ulrik Buchholtz. The HoTT library is coming along nicely. We have most things from the first 7 chapters of the HoTT book, and some category theory. In this file there is a summary what is in the HoTT library sorted by where it appears in the HoTT book.
I’ve developed the library partly by porting it from the Coq-HoTT library, since Coq’s syntax is pretty close to Lean. Other things I’ve proven using the proof in the book, or just by proving it myself.
In the library we are heavily using the cubical ideas Dan Licata wrote about earlier this year. For example we have the type of pathovers, which are heterogenous paths lying over another path. These can be written as b =[p] b' (or pathover B b p b' if you want to give the fibration explicitly). These are used for the recursion principle of HITs
definition circle.rec {P : circle → Type} (Pbase : P base)(Ploop : Pbase =[loop] Pbase) (x : circle) : P xand for the equality in sigma’s
variables {A : Type} {B : A → Type}definition sigma_eq_equiv (u v : Σa, B a): (u = v) ≃ (Σ(p : u.1 = v.1), u.2 =[p] v.2)There are also squares and squareovers which are presentations of higher equalities. One neat example which shows the strength of these additional structures is the following example. I had the term 

If every square is formulated as a path between compositions of paths, then this rewriting takes a lot of work. You have to rewrite any individual square (assuming it is formulated as “top equals composition of the other three sides”), then you have to perform a lot of associativity steps to be able to cancel the sides which you get in the middle of the diagram.
Or you can formulate and prove a dedicated lemma for this rewrite step, which also takes quite some work.
However, because I formulated these two-dimensional paths as squares, I could first horizontally compose the four squares. This gives a square with as top 
HITs
Lastly I want to talk about our way of handling HITs in Lean. In Coq and Agda the way to define a HIT is to make a type with the point constructors and then (inconsistently) assume that this type contains the right path constructors and the correct induction principle and computation rules. Then we forget we assumed something which was inconsistent. This is often called Dan Licata’s trick. This works well, but it’s not so clean since it assumes an inconsistency.
In Lean, we add two specific HITs as kernel extension. These HITs are the quotient and the 
The quotient (not to be confused with a set-quotient) is the following HIT: (this is not Lean syntax)
HIT quotient {A : Type} (R : A → A → Type) :=| i : A → quotient R| p : Π{a a' : A}, R a a' → i a = i a'So in a quotient we specify the type of points, and we can add any type of paths to the quotient.
In Lean we have the following constants for quotients. The computation rule for points, rec_class_of, is just defined as reflexivity, to illustrate that the reduction rule is added to the Lean kernel.
open quotientprint quotientprint class_ofprint eq_of_relprint quotient.recprint rec_class_ofprint rec_eq_of_relUsing these HITs, we can define all HITs in Chapters 1-7 of the book. For example we can define the sequential colimit of a type family 
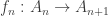


inductive R : (Σn, A n) → (Σn, A n) → Type :=| Rmk : Π{n : ℕ} (a : A n), R ⟨n+1, f a⟩ ⟨n, a⟩In similar ways we can define pushouts, suspensions, spheres and so on. But you can define more HITs with quotients. In my previous blog post I wrote how to construct the propositional truncation using just quotients. In fact, Egbert Rijke and I are working on a generalization of this construction to construct all
Quotients can even be used to construct HITs with 2-path constructors. I have formalized a way to construct quite general HITs with 2-constructors, as long as they are nonrecursive. The HIT I constructed has three constructors. The point constructor i and path constructor p are the same as for the quotient, but there is also a 2-path constructor, which can equate
- One path constructors
- Reflexivity
ap i pwhereiis the point constructor andpis a path inA- concatenations and/or inverses of such paths
Formally, the defintion of the HIT is as follows. Given a type 

inductive T : A → A → Type :=| of_rel : Π{a a'}, R a a' → T a a'| of_path : Π{a a'}, a = a' → T a a'| symm : Π{a a'}, T a a' → T a' a| trans : Π{a a' a''}, T a a' → T a' a'' → T a a''Note that if we’re given a map 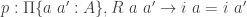

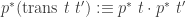
Now if you’re also given a “relation on 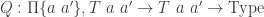
HIT two_quotient A R Q,i : A → two_quotient A R Qp : Π{a a' : A}, R a a' → i a = i a'r : Π{a a'} (r s : T a a'), Q r s → p* r = p* sThis two_quotient allows to construct at least the following HITs:
- The torus (the formulation with two loops and a 2-constructor)
- The reduced suspension
- The groupoid quotient
So in conclusion, from quotients you can define the most commonly used HITs. You can (probably) not define every possible HIT, though, so for the other HITs you still have to use Dan Licata’s trick. I should note here that currently there is no private modifier in Lean yet, so we cannot do Dan Licata’s trick very well in Lean now.
These are all the topics I want to talk about in this blog post. I tried to cover as much of the functionalities of Lean, but there are still features I haven’t talked about. For more information, you can look at the Lean tutorial. Keep in mind that the tutorial is written for the standard library, not the HoTT library, and you might want to skip the first couple of chapters explaining dependent type theory. The Quick Reference chapter at the end of the tutorial (or in pdf format) is also very useful. Also feel free to ask any questions in the comments, in the lean-user google group or in an issue on Github. Finally, if you’re willing to help with the HoTT library, that would be very much appreciated!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK