

On the complexity of JSON serialization | ample code
source link: https://einarwh.wordpress.com/2020/05/08/on-the-complexity-of-json-serialization/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

On the complexity of JSON serialization
Posted: May 8, 2020 | Author: Einar | Filed under: Uncategorized |7 CommentsI vented a bit on Twitter the other day about my frustrations with JSON serialization in software development.
I hate configuring JSON serializers.
— Einar W. Høst (@einarwh) May 7, 2020
I thought I’d try to write it out in a bit more detail.
I’m going to embrace ambiguity and use the term “serialization” to mean both actual serialization (producing a string from some data structure) and deserialization (producing a data structure from some string). The reason is that our terminology sucks, and we have no word that encompasses both. No, (de-)serialization is not a word. I think you’ll be able to work out which sense I’m using at any given point. You’re not a machine after all.
Here’s the thing: on every single software project or product I’ve worked on, JSON serialization has been a endless source of pain and bugs. It’s a push stream of trouble. Why is that so? What is so inherently complicated in the problem of JSON serialization that we always, by necessity, struggle with it?
It’s weird, because the JSON object model is really really simple. Moreover, it’s a bounded, finite set of problems, isn’t it? How do you serialize or deserialize JSON? Well, gee, you need to map between text and the various entities in the JSON object model. Specifically, you need to be able to handle the values null, true and false, you need to handle numbers, strings and whitespace (all of which are unambiguously defined), and you need to handle arrays and objects of values. That’s it. Once you’ve done that, you’re done. There are no more problems!
I mean, it’s probably an interesting engineering challenge to make that process fast, but that’s not something that should ever end up causing us woes. Someone else could solve that problem for us once and for all. People have solved problems much, much more complicated than that once and for all.
But I’m looking at the wrong problem of course. The real problem is something else, because “JSON serialization” as commonly practiced in software development today is much more than mere serializing and deserializing JSON!
This is actual JSON serialization:

This problem has some very nice properties! It is well-defined. It is closed. It has bounded complexity. There are no sources of new complexity unless the JSON specification itself is changed. It is an eminent candidate for a black box magical solution – some highly tuned, fast, low footprint enterprise-ready library or other. Great.
This, however, is “JSON serialization” as we practice it:

“JSON serialization” is not about mapping to or from a text string a single, canonical, well-defined object model. It is much more ambitious! It is about mapping to or from a text string containing JSON and some arbitrarily complex data model that we invented using a programming language of our choice. The reason, of course, is that we don’t want to work with a JSON representation in our code, we want to work with our own data structure. We may have a much richer type system, for instance, that we would like to exploit. We may have business rules that we want to enforce. But at the same it it’s so tedious to write the code to map between representations. Boilerplate, we call it, because we don’t like it. It would be very nice if the “JSON serializer” could somehow produce our own, custom representation directly! Look ma, no boilerplate! But now the original problem has changed drastically.
It now includes this:

The sad truth is that it belongs to a class of problems that is both boring and non-trivial. They do exist. It is general data model mapping, where only one side has fixed properties. It could range from very simple (if the two models are identical) to incredibly complex or even unsolvable. It depends on your concrete models. And since models are subject to change, so is the complexity of your problems. Hence the endless stream of pain and bugs mentioned above.
How does an ambitious “JSON serializer” attempt to solve this problem? It can’t really know how to do the mapping correctly, so it must guess, based on conventions and heuristics. Like if two names are the same, you should probably map between them. Probably. Like 99% certain that it should map. Obviously it doesn’t really know about your data model, so it needs to use the magic of reflection. For deserialization, it needs to figure out the correct way to construct instances of your data represention. What if there are multiple ways? It needs to choose one. Sometimes it will choose or guess wrong, so there needs to be mechanisms for giving it hints to rectify that. What if there are internal details in your data representation that doesn’t have a natural representation in JSON? It needs to know about that. More mechanisms to put in place. And so on and so forth, ad infinitum.
This problem has some very bad properties! It is ill-defined. It is open. It has unbounded, arbitrary complexity. There are endless sources of new complexity, because you can always come up with new ways of representing your data in your own code, and new exceptions to whatever choices the “JSON serializer” needs to make. The hints you gave it may become outdated. It’s not even obvious that there exists an unambiguous mapping to or from your data model and JSON. It is therefore a terrible candidate for a black box magical solution!
It’s really mind-boggling that we can talk about “single responsibility principle” with a grave expression on our faces and then happily proceed to do our “JSON serialization”. Clearly we’re doing two things at once. Clearly our “JSON serializer” now has two responsibilities, not one. Clearly there is more than one reason to change. And yet here we are. Because it’s so easy, until it isn’t.
But there are more problems. Consider a simple refactoring: changing the name of a property of your data model, for instance. It’s trivial, right? Just go ahead and change it! Now automatically your change also affects your JSON document. Is that what you want? Always? To change your external contract when your internal representation changes? You want your JSON representation tightly coupled to your internal data model? Really? “But ha, ha! That’s not necessarily so!” you may say, because you might be a programmer and a knight of the technically correct. “You can work around that!” And indeed you can. You can use the levers on the black box solution to decouple what you’ve coupled! Very clever! You can perhaps annotate your property with an explicit name, or even take full control over the serialization process by writing your own custom serializer plug-in thing. But at that point it is time for a fundamental question: “why are you doing this again?”.
Whenever there is potentially unbounded complexity involved in a problem, you really want full control over the solution. You want maximum transparency. Solving the problem by trying to give the black box the right configurations and instructions is much, much more difficult than just doing it straightforwardly “by hand”, as it were. By hand, there are no “exceptions to the default”, you just make the mapping you want. Conversely, if and when you summon a daemon to solve a problem using the magic of reflection, you really want that problem to be a fixed one. Keep the daemon locked in a sealed box. If you ever have to open the box, you’ve lost. You’ll need to tend to the deamon endlessly and its mood varies. It is a Faustian bargain.
So what am I suggesting? I’m suggesting letting JSON serialization be about JSON only. Let JSON serializer libraries handle translating between text and a representation of the JSON object model. They can do that one job really well, quickly and robustly. Once you have that, you take over! You take direct control over the mapping from JSON to your own model.
It looks like this:
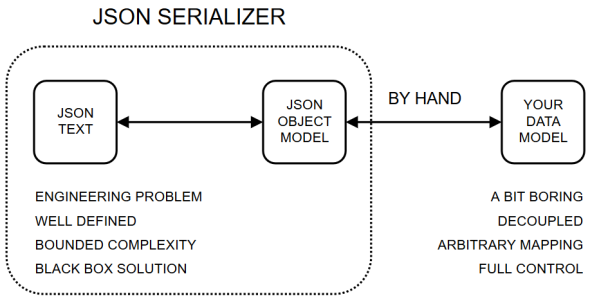
There is still potentially arbitrary complexity involved of course, in the mapping between JSON and your own model. But it is visible, transparent complexity that you can address with very simple means. So simple that we call it boilerplate.
There is a famous paper by Fred Brooks Jr kalled “No Silver Bullet“. In it, Brooks distinguishes between “essential” and “accidental” complexity. That’s an interesting distinction, worthy of a discussion of its own. But I think it’s fair to say that for “JSON serialization”, we’re deep in the land of the accidental. There is nothing inescapable about the complexity of serializing and deserializing JSON.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK