

索引文件的生成(十七)
source link: https://www.amazingkoala.com.cn/Lucene/Index/2020/0526/143.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
索引文件的生成(十七)(Lucene 8.4.0)
本文承接索引文件的生成(十六)之dvm&&dvd继续介绍剩余的内容,先给出流程图:
生成索引文件.dvd、.dvm之NumericDocValues的流程图
使用域值映射存储
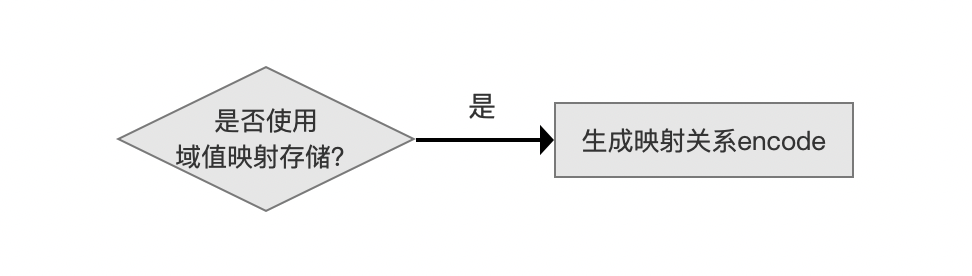
介绍本流程点之前,先介绍下什么是域值映射存储:
- 域值映射存储通过一个映射关系,将每一种域值映射为一个新的数值,并且存储该数值到索引文件.dvd中,在读取阶段通过该数值和映射关系,获得原始的域值。
生成映射关系encode需要几下几个步骤:
- 步骤一:收集域值种类
- 步骤二:排序域值
- 步骤三:写入到映射关系encode
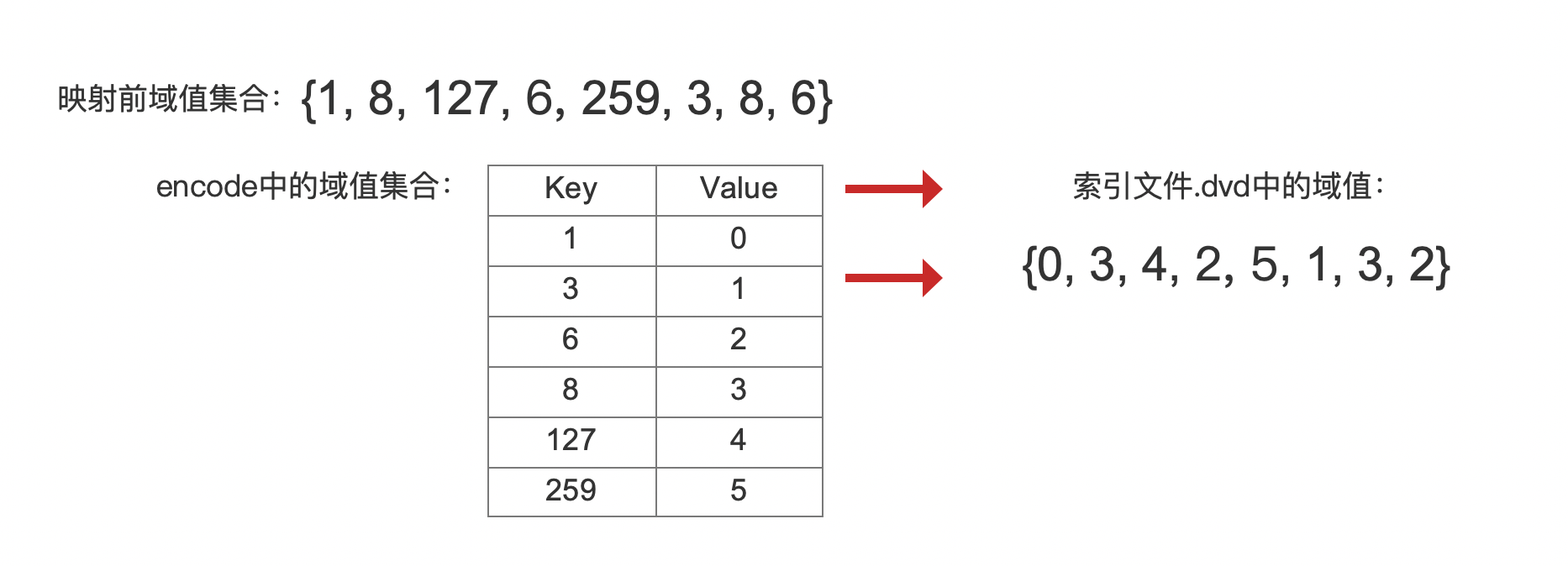
我们通过一个例子来介绍生成映射关系encode的过程,假设有以下的域值集合:
xxxxxxxxxx
{1, 8, 127, 6, 259, 3, 8, 6}步骤一:收集域值种类
该步骤即在文章索引文件的生成(十六)之dvm&&dvd中提到的使用一个Set<Long>对象uniqueValues来收集。在本例子,收集后的uniqueValues中包含的域值种类如下所示:
xxxxxxxxxx
{1, 8, 127, 6, 259, 3}步骤二:排序域值
排序后的域值如下所示:
xxxxxxxxxx
{1, 3, 6, 8, 127, 259}排序的目的在于使得映射后的域值仍具有跟映射前的域值的相同的排序属性(域值之间的大小关系)。
步骤三:写入到映射关系encode中
该步骤直接给出源码更容易理解:
xxxxxxxxxx
Map<Long, Integer> encode = new HashMap<>();
for (int i = 0; i < sortedUniqueValues.length; ++i) {encode.put(sortedUniqueValues[i], i);
}
上述代码中,sortedUniqueValues即排序后的uniqueValues,从代码可以看出映射后的域值是从0开始的递增值,下面给出当前例子生成映射关系encode的步骤:
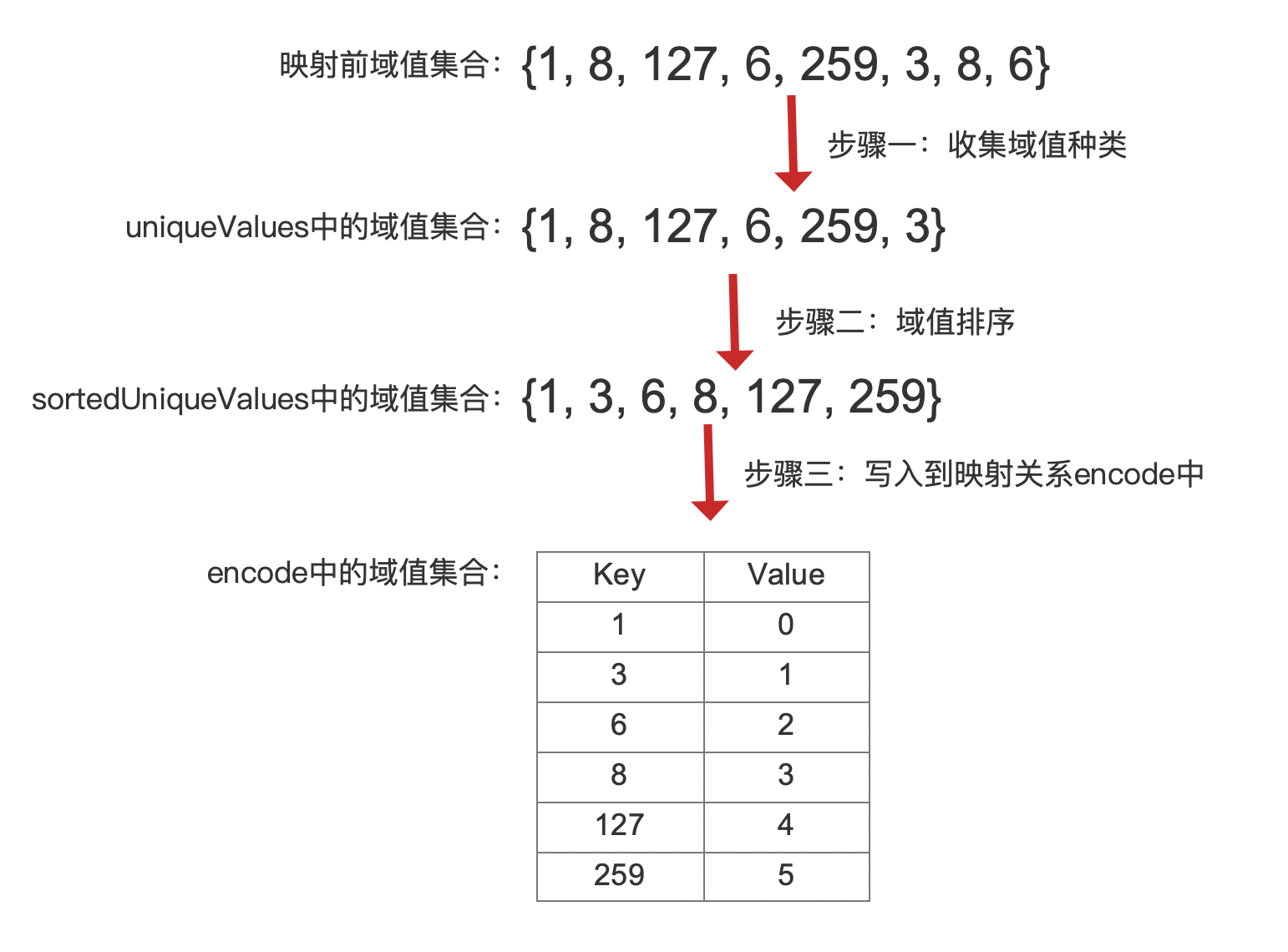
图3中可以看出,映射后的域值之间的大小关系(数值大小)与映射前的一致,当然我们需要将映射前的域值,即sortedUniqueValues中的域值集合写入到索引文件.dvm中,在读取阶段用于解码映射后的域值,这些域值在索引文件.dvm中的位置如下所示:
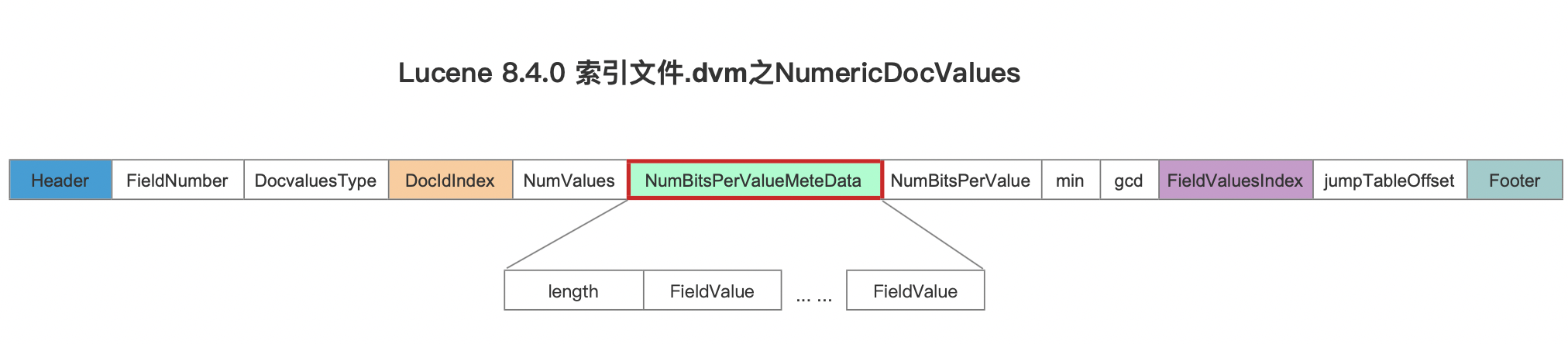
图4中,length描述的是域值种类数量,FieldValue即sortedUniqueValues中的域值集合。
我们回到当前流程点的介绍,使用域值映射需要满足下面的条件:
xxxxxxxxxx
if (uniqueValues.size() <= 256
&& uniqueValues.size() > 1
&& DirectWriter.unsignedBitsRequired(uniqueValues.size() - 1) < DirectWriter.unsignedBitsRequired((max - min) / gcd)) {... ... // code
}
上述条件中,域值种类数量在区间(1, 256]时使用域值映射,因为存储一个域值时,只需要最多一个字节,即8个bit来存储一个域值,如果不使用映射存储,只能使用(max - min) / gcd的方式(域值集合无序)存储域值,那么可能需要多个字节来存储,即在读取阶段,可能需要读取多个字节才能解码出一个域值,故使用域值映射能优化使用一个字节存储域值的读写性能;
但是相比较读写性能,Lucene更优先考虑存储性能,如果使用域值映射后需要占用更多的存储空间,那么就不使用域值映射存储,上述条件中,DirectWriter.unsignedBitsRequired()条件描述的是存储一个域值占用的bit数量。
另外关于上述条件的设计思想见这个issue: https://issues.apache.org/jira/browse/LUCENE-4936?jql=text%20~%20%22uniqueValues%22 。
使用block存储域值
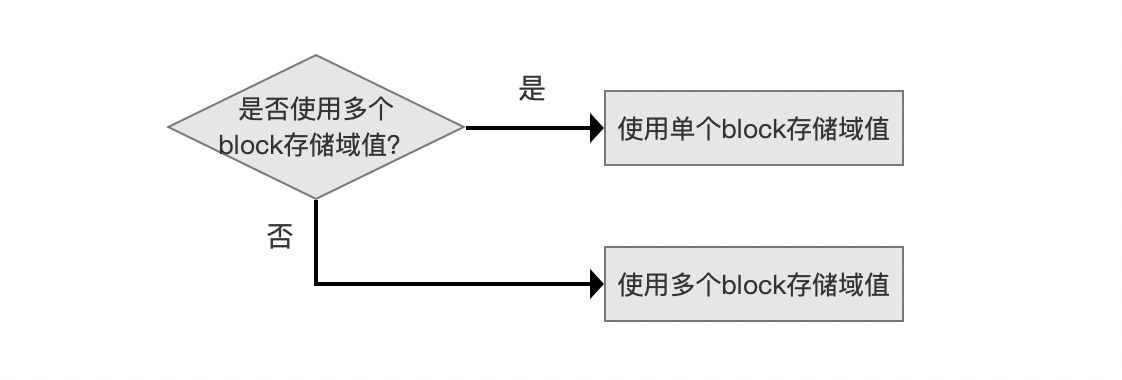
是否使用以及为什么使用多个block存储域值的原因已经在文章索引文件的生成(十六)之dvm&&dvd中介绍,这里不赘述。
从图1可以看出在使用单个block存储域值时,可能会使用域值映射存储,那么实际写入到索引文件.dvd中的域值为映射后的域值,如下图所示:
上述域值在索引文件.dvd中的位置如下所示:
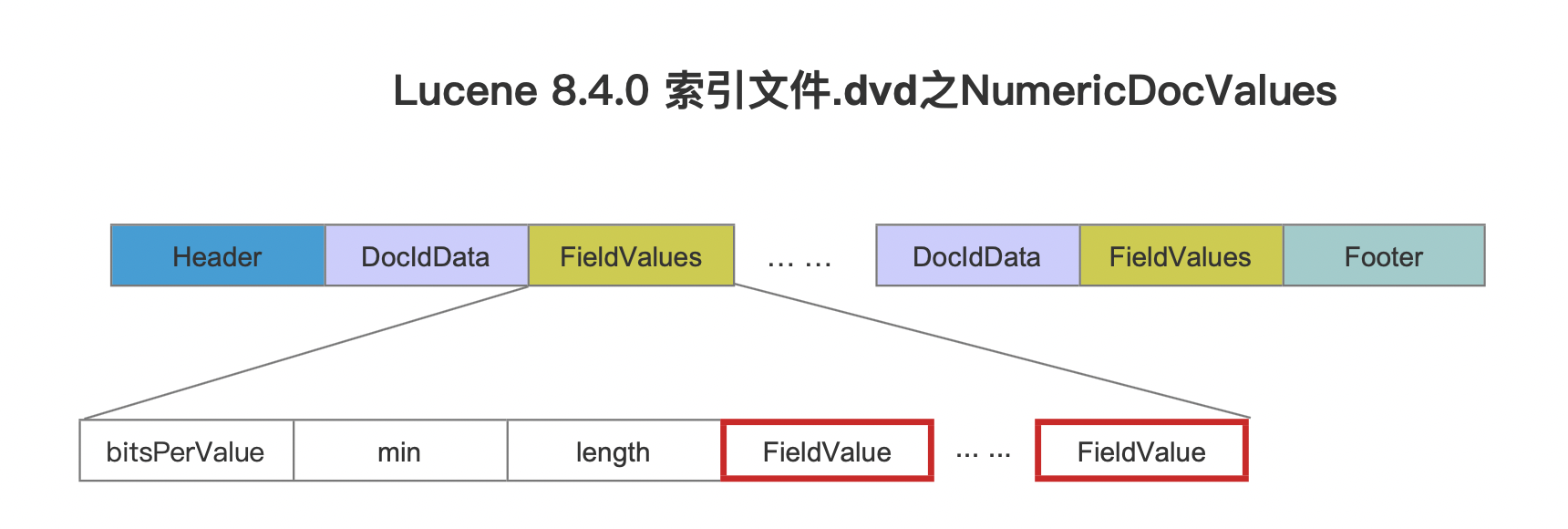
图7中其他字段的介绍见文章NumericDocValues。
以上就是生成索引文件.dvd、.dvm之NumericDocValues的全部内容,我们接着介绍生成索引文件.dvd、.dvm之SortedNumericDocValues的内容。
生成索引文件.dvd、.dvm之SortedNumericDocValues
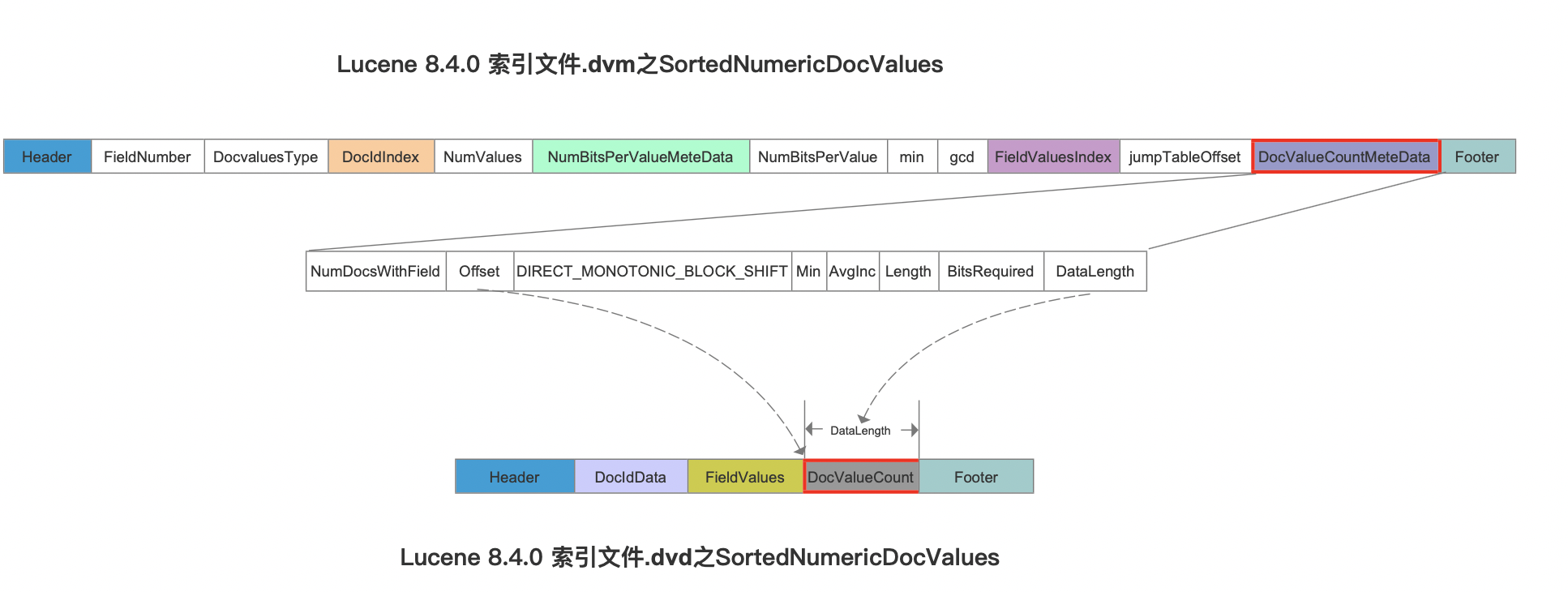
SortedNumericDocValues的数据结构跟NumericDocValues相似,它新增了字段用于描述SortedNumericDocValues相对于NumericDocValues新的特性,即一篇文档中允许存在多个域名相同的SortedNumericDocValuesField域,在下图中用红框标注:

点击查看大图

点击查看大图
注意的是上图中描述的是只有一种域名的情形。
在前面的文章中,我们知道图9中DocIdData描述了所有的文档号信息,由于每一个SortedNumericDocValues在一篇文档中可能存在多个值,故使用DocValueCount来实现索引,该索引描述了一篇文档中有多少个相同域名对应的SortedNumericDocValues信息,如下所示:
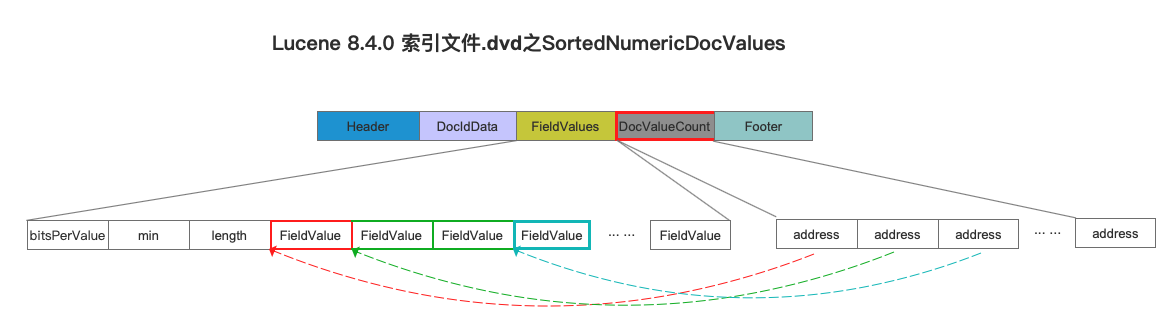
点击查看大图
图10中,address描述的是每篇文档中包含的相同域名对应的域值数量,例如用红色虚线表示这一篇文档中有1个域值,同理绿色虚线表示这一篇文档中有2个域值,在读取过程中,所有的域值会被读取到数组中,而address正是描述的数组的下标。
另外在索引文件.dvm中,DocValueCountMeteData用来描述DocValueCount字段在索引文件.dvd中的位置,如下所示:
点击查看大图
图11中,Offset跟DataLength两个字段描述了DocValueCount的信息在索引文件.dvm中的数据区间。
至此,生成索引文件.dvd、.dvm之NumericDocValues、SortedNumericDocValues的内容介绍完毕。
点击下载附件
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK