

How to Write Your Own C++ Game Engine
source link: https://preshing.com/20171218/how-to-write-your-own-cpp-game-engine/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Dec 18, 2017
How to Write Your Own C++ Game Engine
Lately I’ve been writing a game engine in C++. I’m using it to make a little mobile game called Hop Out. Here’s a clip captured from my iPhone 6. (Unmute for sound!)
Hop Out is the kind of game I want to play: Retro arcade gameplay with a 3D cartoon look. The goal is to change the color of every pad, like in Q*Bert.
Hop Out is still in development, but the engine powering it is starting to become quite mature, so I thought I’d share a few tips about engine development here.
Why would you want to write a game engine? There are many possible reasons:
- You’re a tinkerer. You love building systems from the ground up and seeing them come to life.
- You want to learn more about game development. I spent 14 years in the game industry and I’m still figuring it out. I wasn’t even sure I could write an engine from scratch, since it’s vastly different from the daily responsibilities of a programming job at a big studio. I wanted to find out.
- You like control. It’s satisfying to organize the code exactly the way you want, knowing where everything is at all times.
- You feel inspired by classic game engines like AGI (1984), id Tech 1 (1993), Build (1995), and industry giants like Unity and Unreal.
- You believe that we, the game industry, should try to demystify the engine development process. It’s not like we’ve mastered the art of making games. Far from it! The more we examine this process, the greater our chances of improving upon it.
The gaming platforms of 2017 – mobile, console and PC – are very powerful and, in many ways, quite similar to one another. Game engine development is not so much about struggling with weak and exotic hardware, as it was in the past. In my opinion, it’s more about struggling with complexity of your own making. It’s easy to create a monster! That’s why the advice in this post centers around keeping things manageable. I’ve organized it into three sections:
- Use an iterative approach
- Think twice before unifying things too much
- Be aware that serialization is a big subject
This advice applies to any kind of game engine. I’m not going to tell you how to write a shader, what an octree is, or how to add physics. Those are the kinds of things that, I assume, you already know that you should know – and it depends largely on the type of game you want to make. Instead, I’ve deliberately chosen points that don’t seem to be widely acknowledged or talked about – these are the kinds of points I find most interesting when trying to demystify a subject.
Use an Iterative Approach
My first piece of advice is to get something (anything!) running quickly, then iterate.
If possible, start with a sample application that initializes the device and draws something on the screen. In my case, I downloaded SDL, opened Xcode-iOS/Test/TestiPhoneOS.xcodeproj, then ran the testgles2 sample on my iPhone.

Voilà! I had a lovely spinning cube using OpenGL ES 2.0.
My next step was to download a 3D model somebody made of Mario. I wrote a quick & dirty OBJ file loader – the file format is not that complicated – and hacked the sample application to render Mario instead of a cube. I also integrated SDL_Image to help load textures.

Then I implemented dual-stick controls to move Mario around. (In the beginning, I was contemplating making a dual-stick shooter. Not with Mario, though.)

Next, I wanted to explore skeletal animation, so I opened Blender, modeled a tentacle, and rigged it with a two-bone skeleton that wiggled back and forth.
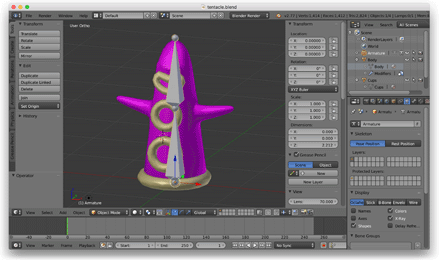
At this point, I abandoned the OBJ file format and wrote a Python script to export custom JSON files from Blender. These JSON files described the skinned mesh, skeleton and animation data. I loaded these files into the game with the help of a C++ JSON library.

Once that worked, I went back into Blender and made more elaborate character. (This was the first rigged 3D human I ever created. I was quite proud of him.)

Over the next few months, I took the following steps:
- Started factoring out vector and matrix functions into my own 3D math library.
- Replaced the
.xcodeprojwith a CMake project. - Got the engine running on both Windows and iOS, because I like working in Visual Studio.
- Started moving code into separate “engine” and “game” libraries. Over time, I split those into even more granular libraries.
- Wrote a separate application to convert my JSON files into binary data that the game can load directly.
- Eventually removed all SDL libraries from the iOS build. (The Windows build still uses SDL.)
The point is: I didn’t plan the engine architecture before I started programming. This was a deliberate choice. Instead, I just wrote the simplest code that implemented the next feature, then I’d look at the code to see what kind of architecture emerged naturally. By “engine architecture”, I mean the set of modules that make up the game engine, the dependencies between those modules, and the API for interacting with each module.
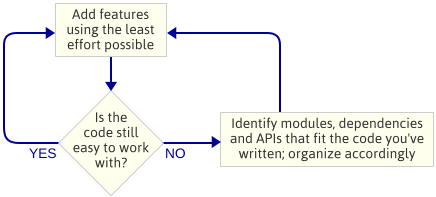
This is an iterative approach because it focuses on smaller deliverables. It works well when writing a game engine because, at each step along the way, you have a running program. If something goes wrong when you’re factoring code into a new module, you can always compare your changes with the code that worked previously. Obviously, I assume you’re using some kind of source control.
You might think a lot of time gets wasted in this approach, since you’re always writing bad code that needs to be cleaned up later. But most of the cleanup involves moving code from one .cpp file to another, extracting function declarations into .h files, or equally straightforward changes. Deciding where things should go is the hard part, and that’s easier to do when the code already exists.
I would argue that more time is wasted in the opposite approach: Trying too hard to come up with an architecture that will do everything you think you’ll need ahead of time. Two of my favorite articles about the perils of over-engineering are The Vicious Circle of Generalization by Tomasz Dąbrowski and Don’t Let Architecture Astronauts Scare You by Joel Spolsky.
I’m not saying you should never solve a problem on paper before tackling it in code. I’m also not saying you shouldn’t decide what features you want in advance. For example, I knew from the beginning that I wanted my engine to load all assets in a background thread. I just didn’t try to design or implement that feature until my engine actually loaded some assets first.
The iterative approach has given me a much more elegant architecture than I ever could have dreamed up by staring at a blank sheet of paper. The iOS build of my engine is now 100% original code including a custom math library, container templates, reflection/serialization system, rendering framework, physics and audio mixer. I had reasons for writing each of those modules, but you might not find it necessary to write all those things yourself. There are lots of great, permissively-licensed open source libraries that you might find appropriate for your engine instead. GLM, Bullet Physics and the STB headers are just a few interesting examples.
Think Twice Before Unifying Things Too Much
As programmers, we try to avoid code duplication, and we like it when our code follows a uniform style. However, I think it’s good not to let those instincts override every decision.
Resist the DRY Principle Once in a While
To give you an example, my engine contains several “smart pointer” template classes, similar in spirit to std::shared_ptr. Each one helps prevent memory leaks by serving as a wrapper around a raw pointer.
Owned<>is for dynamically allocated objects that have a single owner.Reference<>uses reference counting to allow an object to have several owners.audio::AppOwned<>is used by code outside the audio mixer. It allows game systems to own objects that the audio mixer uses, such as a voice that’s currently playing.audio::AudioHandle<>uses a reference counting system internal to the audio mixer.
It may look like some of those classes duplicate the functionality of the others, in violation of the DRY (Don’t Repeat Yourself) Principle. Indeed, earlier in development, I tried to re-use the existing Reference<> class as much as possible. However, I found that the lifetime of an audio object is governed by special rules: If an audio voice has finished playing a sample, and the game does not hold a pointer to that voice, the voice can be queued for deletion immediately. If the game holds a pointer, then the voice object should not be deleted. And if the game holds a pointer, but the pointer’s owner is destroyed before the voice has ended, the voice should be canceled. Rather than adding complexity to Reference<>, I decided it was more practical to introduce separate template classes instead.
95% of the time, re-using existing code is the way to go. But if you start to feel paralyzed, or find yourself adding complexity to something that was once simple, ask yourself if something in the codebase should actually be two things.
It’s OK to Use Different Calling Conventions
One thing I dislike about Java is that it forces you to define every function inside a class. That’s nonsense, in my opinion. It might make your code look more consistent, but it also encourages over-engineering and doesn’t lend itself well to the iterative approach I described earlier.
In my C++ engine, some functions belong to classes and some don’t. For example, every enemy in the game is a class, and most of the enemy’s behavior is implemented inside that class, as you’d probably expect. On the other hand, sphere casts in my engine are performed by calling sphereCast(), a function in the physics namespace. sphereCast() doesn’t belong to any class – it’s just part of the physics module. I have a build system that manages dependencies between modules, which keeps the code organized well enough for me. Wrapping this function inside an arbitrary class won’t improve the code organization in any meaningful way.
Then there’s dynamic dispatch, which is a form of polymorphism. We often need to call a function for an object without knowing the exact type of that object. A C++ programmer’s first instinct is to define an abstract base class with virtual functions, then override those functions in a derived class. That’s valid, but it’s only one technique. There are other dynamic dispatch techniques that don’t introduce as much extra code, or that bring other benefits:
- C++11 introduced
std::function, which is a convenient way to store callback functions. It’s also possible to write your own version ofstd::functionthat’s less painful to step into in the debugger. - Many callback functions can be implemented with a pair of pointers: A function pointer and an opaque argument. It just requires an explicit cast inside the callback function. You see this a lot in pure C libraries.
- Sometimes, the underlying type is actually known at compile time, and you can bind the function call without any additional runtime overhead. Turf, a library that I use in my game engine, relies on this technique a lot. See
turf::Mutexfor example. It’s just atypedefover a platform-specific class. - Sometimes, the most straightforward approach is to build and maintain a table of raw function pointers yourself. I used this approach in my audio mixer and serialization system. The Python interpreter also makes heavy use of this technique, as mentioned below.
- You can even store function pointers in a hash table, using the function names as keys. I use this technique to dispatch input events, such as multitouch events. It’s part of a strategy to record game inputs and play them back with a replay system.
Dynamic dispatch is a big subject. I’m only scratching the surface to show that there many ways to achieve it. The more you write extendible low-level code – which is common in a game engine – the more you’ll find yourself exploring alternatives. If you’re not used to this kind of programming, the Python interpreter, which is written an C, is an excellent resource to learn from. It implements a powerful object model: Every PyObject points to a PyTypeObject, and every PyTypeObject contains a table of function pointers for dynamic dispatch. The document Defining New Types is a good starting point if you want to jump straight right in.
Be Aware that Serialization Is a Big Subject
Serialization is the act of converting runtime objects to and from a sequence of bytes. In other words, saving and loading data.
For many if not most game engines, game content is created in various editable formats such as .png, .json, .blend or proprietary formats, then eventually converted to platform-specific game formats that the engine can load quickly. The last application in this pipeline is often referred to as a “cooker”. The cooker might be integrated into another tool, or even distributed across several machines. Usually, the cooker and a number of tools are developed and maintained in tandem with the game engine itself.
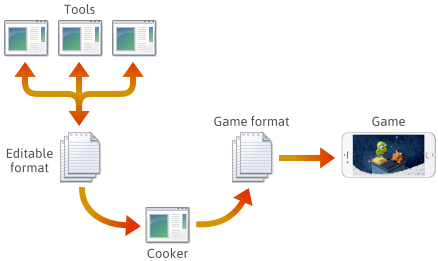
When setting up such a pipeline, the choice of file format at each stage is up to you. You might define some file formats of your own, and those formats might evolve as you add engine features. As they evolve, you might find it necessary to keep certain programs compatible with previously saved files. No matter what format, you’ll ultimately need to serialize it in C++.
There are countless ways to implement serialization in C++. One fairly obvious way is to add load and save functions to the C++ classes you want to serialize. You can achieve backward compatibility by storing a version number in the file header, then passing this number into every load function. This works, although the code can become cumbersome to maintain.
void load(InStream& in, u32 fileVersion) {
// Load expected member variables
in >> m_position;
in >> m_direction;
// Load a newer variable only if the file version being loaded is 2 or greater
if (fileVersion >= 2) {
in >> m_velocity;
}
}
It’s possible to write more flexible, less error-prone serialization code by taking advantage of reflection – specifically, by creating runtime data that describes the layout of your C++ types. For a quick idea of how reflection can help with serialization, take a look at how Blender, an open source project, does it.
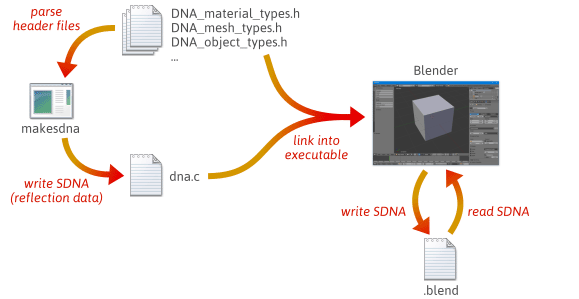
When you build Blender from source code, many steps happen. First, a custom utility named makesdna is compiled and run. This utility parses a set of C header files in the Blender source tree, then outputs a compact summary of all C types defined within, in a custom format known as SDNA. This SDNA data serves as reflection data. The SDNA is then linked into Blender itself, and saved with every .blend file that Blender writes. From that point on, whenever Blender loads a .blend file, it compares the .blend file’s SDNA with the SDNA linked into the current version at runtime, and uses generic serialization code to handle any differences. This strategy gives Blender an impressive degree of backward and forward compatibility. You can still load 1.0 files in the latest version of Blender, and new .blend files can be loaded in older versions.
Like Blender, many game engines – and their associated tools – generate and use their own reflection data. There are many ways to do it: You can parse your own C/C++ source code to extract type information, as Blender does. You can create a separate data description language, and write a tool to generate C++ type definitions and reflection data from this language. You can use preprocessor macros and C++ templates to generate reflection data at runtime. And once you have reflection data available, there are countless ways to write a generic serializer on top of it.
Clearly, I’m omitting a lot of detail. In this post, I only want to show that there are many different ways to serialize data, some of which are very complex. Programmers just don’t discuss serialization as much as other engine systems, even though most other systems rely on it. For example, out of the 96 programming talks given at GDC 2017, I counted 31 talks about graphics, 11 about online, 10 about tools, 4 about AI, 3 about physics, 2 about audio – but only one that touched directly on serialization.
At a minimum, try to have an idea how complex your needs will be. If you’re making a tiny game like Flappy Bird, with only a few assets, you probably don’t need to think too hard about serialization. You can probably load textures directly from PNG and it’ll be fine. If you need a compact binary format with backward compatibility, but don’t want to develop your own, take a look at third-party libraries such as Cereal or Boost.Serialization. I don’t think Google Protocol Buffers are ideal for serializing game assets, but they’re worth studying nonetheless.
Writing a game engine – even a small one – is a big undertaking. There’s a lot more I could say about it, but for a post of this length, that’s honestly the most helpful advice I can think to give: Work iteratively, resist the urge to unify code a little bit, and know that serialization is a big subject so you can choose an appropriate strategy. In my experience, each of those things can become a stumbling block if ignored.
I love comparing notes on this stuff, so I’d be really interested to hear from other developers. If you’ve written an engine, did your experience lead you to any of the same conclusions? And if you haven’t written one, or are just thinking about it, I’m interested in your thoughts too. What do you consider a good resource to learn from? What parts still seem mysterious to you? Feel free to leave a comment below or hit me up on Twitter!
Recommend
-
11
Write your Own Proof-of-Work Blockchain 2. Introduction
-
21
Write your Own Virtual Machine 2. Introduction In this...
-
10
« back — written by Brent on June 13, 2020 Don't write your own framework ...
-
17
The plan Our journey is made of 4 stations - each of them depending on the previous ones:
-
13
Write your own compiler - Station #3: the emitter Feb 8, 2017 • Yehonathan Sharvit The plan Our
-
11
Write your own compiler - Station #2: the parser Feb 8, 2017 • Yehonathan Sharvit The plan Our
-
15
Writing a compiler Nothing in computer science sounds more challenging than writing a compiler. And indeed, it is challenging - very challenging. You probably have to be one of those genius guys in order to...
-
10
Write your own compiler - Station #1: the tokenizer Feb 8, 2017 • Yehonathan Sharvit The plan Our
-
9
Write Your Own Kubernetes Sub-Command [Part 9]January 31st 2021 new story...
-
6
About me: My name is Solène Rapenne, pronouns she/her. I like learning and sharing knowledge. Hobbies: '(BSD OpenBSD Lisp cmdline gaming internet...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK