

腾讯GameAISDK试用报告 - 漫漫路
source link: https://www.lanindex.com/%e8%85%be%e8%ae%afgameaisdk%e8%af%95%e7%94%a8%e6%8a%a5%e5%91%8a/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

腾讯在今年8月份的时候开源了自家基于AI的游戏自动化测试工具GameAISDK(https://github.com/Tencent/GameAISDK)。这个东西最吸引人的地方就是使用了CV+AI的技术来实现游戏自动化。
区别与以前的脚本或者UI自动化工具,对业务代码侵入少,技术前沿。
总体结论(个人主观)
总分100分的话,我给60分,主要槽点如下:
- 各种BUG,文档教程与实际不一致;
- 环境安装有些复杂,而且对安装环境限制比较死,如果不是Ubuntu或者Windows需要花大力气才能安装成功使用;
- 强化学习DQN的方式基本是鸡肋;
- 源代码里面很多tricky的地方,给阅读理解造成困扰;
下面我选取一下典型的例子来分析一下,可能每个点都提一下核心问题和总结,因为要展开说每个点都可以形成单独文章。
后面简称GameAISDK为工程。
安装环境的问题
官方教程只给出了Ubuntu和Windows的安装教程,经过实践在Mac系统上是无法使用的。主要原因是工程内部有内部进程组件Tbus,这个是腾讯内部的进程间通信组件,目前没开源。工程里装载的是已经编译好的Linux与Windows版本库,没有Mac版本的Tbus。
在Debian和Centos上面均可以安装成功使用,但是如果需要使用GPU版本,主要看你的显卡驱动与Cuda、Cudnn的关系,然后Cuda与工程里的Tensorflow版本也是强相关的,如果你改变了Tensorflow的版本,工程里部分代码可能需要修改以适配新的Tensorflow库,这是一个连环套。
这里给一个参考,在Debian 9下面是可以成功安装并使用工程的:
显卡:Tesla T4
驱动版本:440.56
Cuda:10.1
Cudnn:7.5
Tensorflow:2.1(自编译版本,指定Cuda与Cudnn版本)
强化学习(Reinforcement Learning ,RL)与模仿学习(Imitation Learning,IL)
工程提供强化学习与模仿学习两种学习方式,它们的对比大概如下:
模仿学习强化学习训练时长快慢训练难度一般难适用范围小偏中大
其实模仿学习与强化学习按我的理解在游戏自动化测试中是一个互补的方式。但是工程里面基于DQN的RL方式实属鸡肋,原因如下:
- 设置的Reward目前只支持数字,如果需要多维Reward支持或者非数字Reward需要大改;
- 在识别Reward数字这里没有合适方式保持较高的识别率(比如因为数字透明度问题导致的识别误差),从而导致Reward跳变影响训练过程;
- 训练积累缓慢,稍微复杂点的游戏单台手机训练1~2天都难以出成果,因为训练方式的限制无法有效的加速;
所以目前只有模仿学习有实际的用途,但是无奈的是适用范围稍小。
IOService占用CPU100%的BUG
第一次发现这个BUG是在一次AI进程使用过后:先停掉了AIClient,发现IOService这个进程CPU占用一直是100%(其实在使用过程中也会一直处于100%,只是停掉AIClient之后明显暴露了)。
具体原因是在IOService/pyIOService/IOService.py
//_UpdateFrameframe = ImgDecode(frameBuff, frameType)这个ImgDecode特别耗资源,每次_UpdateFrame都会调用,IO_SERVICE_CONTEXT里面存放的是上一个帧的内容。个人觉得在没有收到新帧时重复的ImgDecode是没有必要的,所以需要把下面代码上提,放到ImgDecode之前,发现如果没有新帧就直接返回:
frameSeq = IO_SERVICE_CONTEXT['frame_seq'] if self.__lastFrameSeq == frameSeq: return修改之后在工程使用的时候CPU占用显著降低,并且不影响AI模型的预测。
滑动操作官方教程和实际配置不一致
在利用模仿学习录制样本的时候,如果配置了滑动操作需要额外增加四个配置项:startX,startY,endX,endY。它们作用在如果AI预测了这次滑动行为,那么反应在手机屏幕上的滑动应该怎么划。
所以这里滑动配置的逻辑是:startRect和endRect用作样本录制时的参考,额外增加的四个配置项用作预测结果的行为。
关于SDKTool这一块UI状态机的细节文档缺失
个人推荐是一直运行AI+UI模式的,为什么?
如果只运行AI模式,游戏内的弹窗是无法处理的。当然你可以将弹窗处理录制到样本行为里,但是会有两个问题:1、如果弹窗内容随机,样本学习是否能覆盖全?;2、弹窗的点击区域和其他行为区域有冲突怎么办?
所以个人推荐AI+UI的模式。但是UI模式有一个严格的状态机机制。这里官方文档是丝毫没有提到的,可以参考下面的流程图:
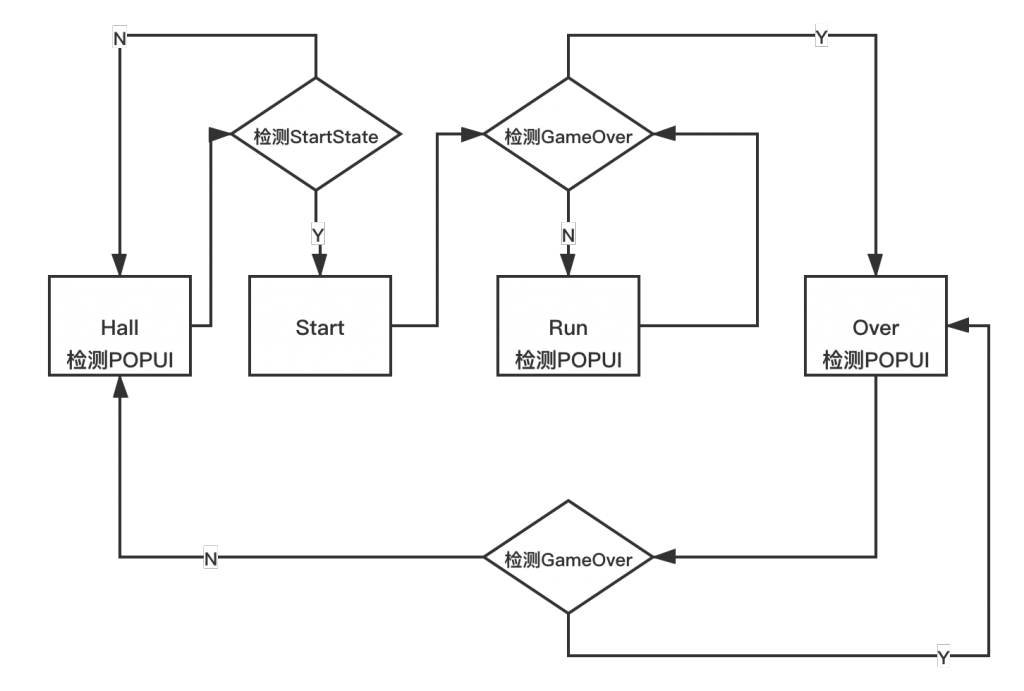
在Run这个状态会开启AI模式,发送的帧会进入训练好的模型里进行行为预测。
在Hall,Run,Over这三个状态会持续检查POPUI的情况,如果检测到会做既定的操作但是不会影响状态变更。
总体来说GameAISDK技术新颖,但是就目前放出的版本来看能解决的问题比较有限,而且官方比较“懒”,距离首版发布已经四个多月,在这期间没有更新一次版本做特定增加或者BUG修复,有些匪夷所思。不知道是不是和当初的Tars一样,为了所谓的“KPI”而开源?
总之希望开源的GameAISDK越来越好,少一些功利,多一些诚恳。
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK