

OpenStack Neutron L3层高可靠
source link: https://blog.csdn.net/xiaoquqi/article/details/39429261
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
英文地址:http://assafmuller.com/2014/08/16/layer-3-high-availability/
L3层Agent的低可靠解决方案
当前,你可以通过多网络节点的方式解决负载分担,但是这并非高可靠和冗余的解决方案。假设你有三个网络节点,当你创建新的路由时,会自动的将新路由规划和分布在这三个网络节点中的一个上。但是,如果一个节点坏掉,上面运行的所有路由将无法提供服务,路由转发也无法正常进行。在Neutron的ceHouse版本中,没有提供任何内置的解决方案。
DHCP Agent的高可靠的变通之道
DHCP的Agent是一个另类——DHCP协议本身就支持在同一个资源池内同时使用多个DHCP提供服务。
在neutron.conf中仅仅需要改变:
dhcp_agents_per_network = X这样DHCP的调度程序会为同一网络启动X个DHCP Agents。所以,对于三个网络节点,并设置dhcp_agents_per_network = 2,每个Neutron网络会在三个节点中启动两个DHCP Agents。这个是如何工作的呢?
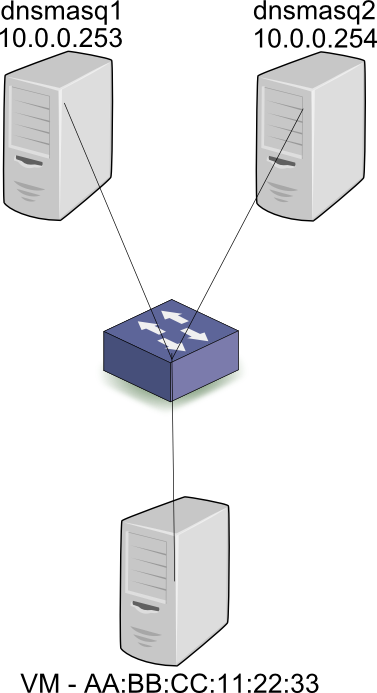
首先,让我们来看一下物理层面的实现。当一台主机连接到子网10.0.0.0/24,会发出DHCP Discover广播包。两个DHCP服务进程dnsmasq1和dnsmasq2(或者其他的DHCP服务)收到广播包,并回复10.0.0.2。假设第一个DHCP服务响应了服务器请求,并将10.0.0.2的请求广播出去,并且指明提供IP的是dnsmasq1-10.0.0.253。所有服务都会接收到广播,但是只有dnsmasq1会回复ACK。由于所有DHCP通讯都是基于广播,第二个DHCP服务也会收到ACK,于是将10.0.0.2标记已经被AA:BB:CC:11:22:33获取,而不会提供给其他的主机。总结一下,所有客户端与服务端的通讯都是基于广播,因此状态(IP地址什么时候被分配,被分配给谁)可以被所有分布的节点正确获知。
在Neutron中,分配MAC地址与IP地址的关系,是在每个dnsmasq服务之前完成的,也就是当Neutron创建Port时。因此,在DHCP请求广播之前,所有两个dnsmasq服务已经在leases文件中获知了,AA:BB:CC:11:22:33应该分配10.0.0.2的映射关系。
回到L3 Agent的低可用
- Pacemaker/Corosync - 使用外部的集群管理技术,为Active节点指定一个Standby的网络节点。Standby节点在正常情况下等呀、等呀等,一旦Active节点发生故障,L3 Agent立即在Standby节点启动。这两个节点配置相同的主机名,当Standby的Agent出台并和服务之前开始同步后,它自己的ID不会改变,因此就像管理同一个router一样。
- 另外一个方案是采用定时同步的方式(cron job)。用Python SDK开发一段脚本,使用API获取所有已经故去的Agent们,之后获取所有上面承载的路由,并且把他们重新分配给其他的Agent。
- 在Juno开发过程中,查看Kevin Benton的这个Patch: https://review.openstack.org/#/c/110893/,让Neutron自己具备重新分配路由的功能。
重新分配路由——路漫漫兮
以上列出的解决方案,实质上都有从失败到恢复的时间,如果在简单的应用场景下,恢复一定数量的路由到新节点并不算慢。但是想象一下,如果有上千个路由就需要话费数个小时完成,重新分配和配置的过程。人们非常需要快速的故障恢复!
分布式虚拟路由(Distributed Virtual Router)
这里有一些文档描述DVR是如何工作的:
这里的要点是将路由放到计算节点(compute nodes),这让网络节点的L3 Agent变得没用了。是不是这样呢?
- DVR主要处理Floating IPs,把SNAT留给网络节点的L3 Agent
- 不和VLANs一起工作,仅仅支持tunnes和L2pop开启
- 每个计算节点需要连接外网
- L3 HA是对部署的一种简化,这个基于Havana和Icehouse版本部署的云平台所不具备的
3层高可靠
什么是VRRP,如何在真实世界里工作
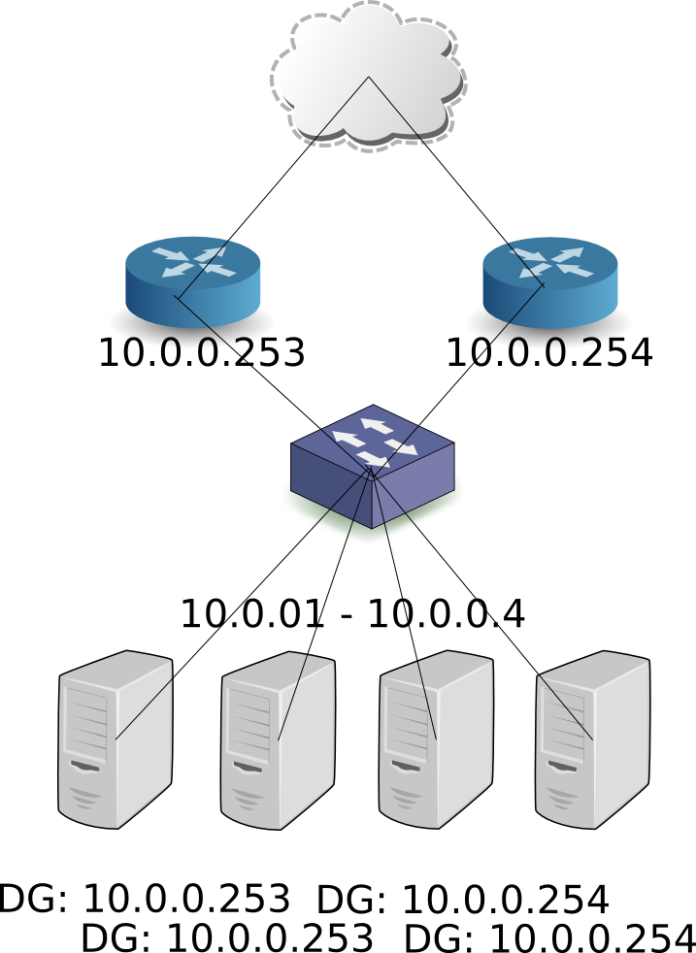
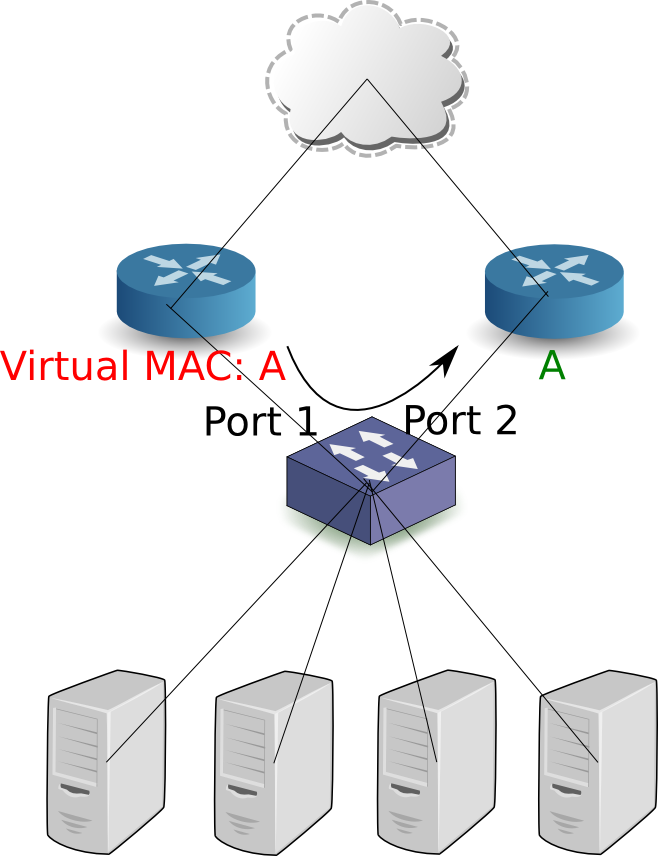

1、每一个路由得到一个新的IP地址,不管VRRP的状态。Master路由将VIP配置为附加的或第二地址。
2、仅仅VIP配置了。例如:Master路由配置了VIP,同时Slave上没有IP配置。
VRRP —— 一些事实
- 直接在IP协议中封装
- Active实例使用多播地址224.0.0.18, MAC 01-00-5E-00-00-12来给Standby路由发送hello消息
- 虚拟MAC地址格式:00-00-5E-00-01-{VRID},因此只有256个不同的VRIDs(0到255)在一个广播域中
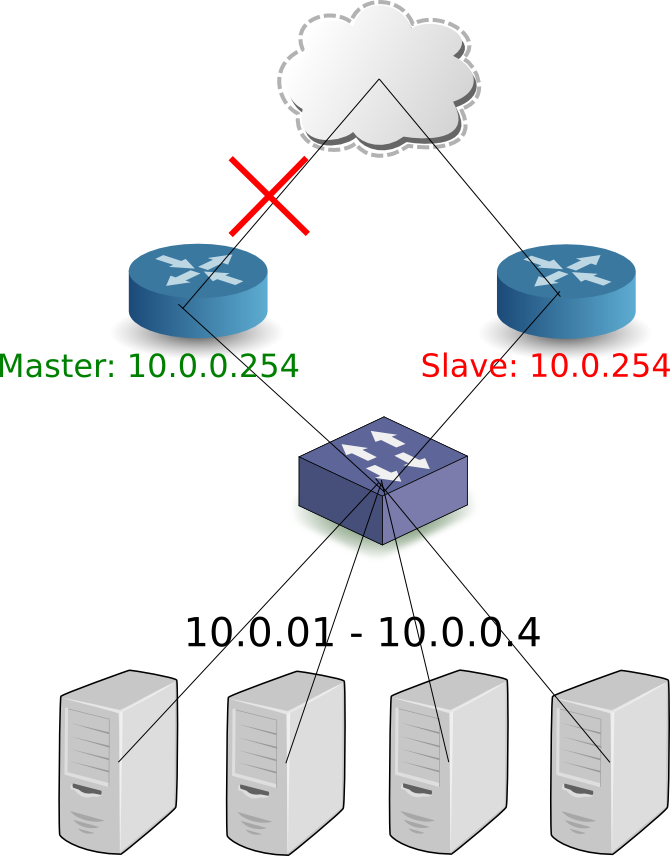
- 选举机制使用用户配置优先级,从1到255,越高优先级越高
- 优先选举策略(Preemptive elections),和其他网络协议一样,意味着一个Standby被配置为较高优先级,或者从连接中断回复后(之前是Active实例),它始终会恢复为Active路由
- 非优先选举策略(Non-preemptive elections)意外着当Active路由回复后,仍然作为Standby角色
- 发送Hello间隔是可以设置的(假定为每T秒),如果Standby路由在3T秒后仍然没有收到master的hello消息,就会触发选举机制
回到Neutron的领地
[stack@vpn-6-88 ~]$ sudo ip netns exec qrouter-b30064f9-414e-4c98-ab42-646197c74020 ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
...
2794: </span><span style="color:#ff0000;"><strong>ha-45249562-ec</strong></span><span style="color:#333333;">: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 12:34:56:78:2b:5d brd ff:ff:ff:ff:ff:ff
inet 169.254.0.2/24 brd 169.254.0.255 scope global ha-54b92d86-4f
valid_lft forever preferred_lft forever
inet6 fe80::1034:56ff:fe78:2b5d/64 scope link
valid_lft forever preferred_lft forever
2795: qr-dc9d93c6-e2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether ca:fe:de:ad:be:ef brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 scope global qr-0d51eced-0f
valid_lft forever preferred_lft forever
inet6 fe80::c8fe:deff:fead:beef/64 scope link
valid_lft forever preferred_lft forever
2796: qg-843de7e6-8f: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether ca:fe:de:ad:be:ef brd ff:ff:ff:ff:ff:ff
inet 19.4.4.4/24 scope global qg-75688938-8d
valid_lft forever preferred_lft forever
inet6 fe80::c8fe:deff:fead:beef/64 scope link
valid_lft forever preferred_lft forever</span>vrrp_sync_group VG_1 {
group {
VR_1
}
notify_backup "/path/to/notify_backup.sh"
notify_master "/path/to/notify_master.sh"
notify_fault "/path/to/notify_fault.sh"
}
vrrp_instance VR_1 {
state BACKUP
interface ha-45249562-ec
virtual_router_id 1
priority 50
nopreempt
advert_int 2
track_interface {
ha-45249562-ec
}
virtual_ipaddress {
19.4.4.4/24 dev qg-843de7e6-8f
}
virtual_ipaddress_excluded {
10.0.0.1/24 dev qr-dc9d93c6-e2
}
virtual_routes {
0.0.0.0/0 via 19.4.4.1 dev qg-843de7e6-8f
}
}#!/usr/bin/env bash
neutron-ns-metadata-proxy --pid_file=/tmp/tmpp_6Lcx/tmpllLzNs/external/pids/b30064f9-414e-4c98-ab42-646197c74020/pid --metadata_proxy_socket=/tmp/tmpp_6Lcx/tmpllLzNs/metadata_proxy --router_id=b30064f9-414e-4c98-ab42-646197c74020 --state_path=/opt/openstack/neutron --metadata_port=9697 --debug --verbose
echo -n master > /tmp/tmpp_6Lcx/tmpllLzNs/ha_confs/b30064f9-414e-4c98-ab42-646197c74020/state* 我们是不是忘了Metadata Agent呢?
未来的工作和局限性
- TCP连接跟踪——在当前的实现中,TCP连接的session在失败恢复后中断。一种解决方案是使用conntrackd复制HA路由间的session状态,这样当故障恢复后,TCP的session会恢复到失败前的状态。
- Master节点在哪?当前,还没有办法让管理员知道哪个网络节点是HA路由的Master实例。计划由Agent提供这些信息,并可以通过API进行查询。
- Agent大逃亡——理想状态下,将一个节点变为维护模式后,应该触发所有HA路由所在节点回收他们的Master状态,加速恢复速度。
- 通知L2pop VIP的改变——考虑在一个tenant网络中路由IP/MAC,只有Master配置真正的有IP地址,但是同一个Neutron Port和同样的MAC会在相关的网络出现。这可能对配置了L2pop驱动产生不利,因为它只希望在一个网络中MAC地址只存在一处。解决的计划是一旦检测到VRRP状态改变,从Agent发送一个RPC消息,这样当路由变为Master,控制节点被通知到了,这样就能改变L2pop的状态了。
- 内置的防火墙、VPN和负载均衡即服务。在DVR和L3 HA与这些服务整合时还有问题,可能会在kilo中解决。
- 每一个Tenant一个HA网络。这就意味着每个Tenant只能有255个HA路由,因为每个路由需要一个VRID,根据VRRP协议每个广播域只允许255个不同的VRID值。
使用和配置
neutron.confl3_ha = True
max_l3_agents_per_router = 2
min_l3_agents_per_router = 2- l3_ha 表示所有的路由默认使用HA模式(与之前不同)。默认是关闭的。
- 你可以根据网络节点的数量设置最大最小值。如果你部署了4个网络节点,但是设置最大值为2,只有两个L3 Agent会被用于HA路由(一个是Master,一个是Slave)。
- min被用来稳健性(sanity)的检查:如果你有两个网络节点,其中一个坏掉了,任何新建的路由在这段时间都会失败,因为你至少需要min个L3 Agent启动来建立HA路由。
neutron router-create --ha=<True | False> router1Spec
How to test
Code
Dedicated wiki page
Section in Neutron L3 sub team wiki (Including overview of patch dependencies and future work)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK