

恶补基础知识
source link: https://www.zenlife.tk/%E6%81%B6%E8%A1%A5%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86.md
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
2015-11-04
返回链表的中间位置的那个节点。
本来以为需要扫两遍的,后来想想发现其实用两个指针,一个一次走一步,另一个一次走两步,扫一次遍就可以完成了。
求的最大递增子序列(不是长度)。动态规划使用的辅助数组是一维还是二维。
如果只是求出序列长度,用一维数组是可以做的。但是当时用的那个递推的公式用一维数组其实做不了。当时是这么想的,f(n)表示最大递增子序列长度,用h[k]表示长度为k的递增子序列中的最大值:
f(n) = f(n-1) + 1 如果a[n]大于h[k]。
f(n) = f(n) 这里是有一个简化,辅助数组只是记录了递增子序列中的最大值,而不是记录下整个递增子序列。一维其实得不到最终那个序列的。改成用二维数组,记录下整个子序列才可以实现。
用这个算法优势在于更新h[k]的时候,可以做二分搜索,所以可以用Nlog(N)求出序列长度。
用一维的辅助数组得到最长递增子序列,不是不可以,但需要用另一种递推公式:
f(n) = max(1, f(k)+1) k取值从0到n最长递增子序列,要么取当前元素,要么取前面f(1)到f(n-1)项中的最大值,条件是a[n]>a[k]。这样最终得到的f(n)数组,找它第一次发生变化的值,就可以把最长递增子序列串起来了。
帖一点代码,用第一种递推公式时算法关键部分大概是这样的:
for (i = 1; i < length; i++) {
if (a[i] > h[k - 1]) {
h[k] = a[i];
k++;
} else {
int pos = 0;
// 可以做二分搜索优化
for (int j = 0; j < k; j++) {
if (a[i] < h[j]) {
pos = j;
break;
}
};
h[pos] = a[i];
}
}
return k;用第二种递归公式,算法关键部分大概是这样的:
for (i=1; ia[j] && f[i]<=f[j]) {
f[i] = f[j] + 1;
}
}
}
return f[i];;>memmove和memcpy
memcpy是不考虑区域重叠的,而memmove要保证复制的时候不发生覆盖。
判断一个数字是否回文,要求O(1)空间
被我想复杂了。对于回文数,从低位到高位取出来再加回去,应该是等于原数的。不过不确定这是一个充要条件还是仅仅必要非充分条件。
还是根据定义的对称性来。获取最低位是取余10,获取最高位是除以10n。去掉最低位是除以10,去掉最高位是取余10n。
vvvvvvvvvv性能优化/高并发vvvvvvvvvvvv
不知道源代码的情况下,如何定位分析程序的性能问题。
先是确认大致的位置,是CPU,还是IO;是磁盘,还是网络。又或者是锁,系统调用,大量上下文切换。可用的工具有top,vmstat,iostat,sar,iftop等。
这里有篇文章比较不错,无耻地链接一下。
top中可以看到哪些信息。
总体的负载(load average),CPU、内存和交换分区的使用情况。
- us, user: 运行(未调整优先级的) 用户进程的CPU时间
- sy,system: 运行内核进程的CPU时间
- ni,niced:运行已调整优先级的用户进程的CPU时间
- wa,IO wait: 用于等待IO完成的CPU时间
- hi:处理硬件中断的CPU时间
- si: 处理软件中断的CPU时间
- st:这个虚拟机被hypervisor偷去的CPU时间。
具体各个进程的信息内存信息:
- VIRT 进程使用的虚拟内存。
- RES 驻留内存大小。驻留内存是任务使用的非交换物理内存大小。
- SHR SHR是进程使用的共享内存。
- MEM 进程使用的物理内存百分比
进程状态:
- D - 不可中断的睡眠态。
- R – 运行态
- S – 睡眠态
- T – 被跟踪或已停止
- Z – 僵尸态
简单设计一个高并发的服务器
高并发服务器的设计有很多种。可以是基于协程的,比如Go语言。可以是事件回调的,比如redis/nodejs这类。具体实现上面,可以做单进程,多线程,或者多进程。采用进程的比如redis,单个进程内一个事件循环,当io可用时会回调相应的操作。多线程的像skynet是,底层由一个线程中做epoll,M个线程中跑N个lua的vm,通过一个全局队列,相互之间发消息通讯。采用多进程的像nginx就是。
我还是继续说当时回答的一种方式。假设是一个无状态的简单业务,在listen之后fork出多个进程来。然后把监听的fd加到epoll中,在每个进程里面去做事件循环。当监听的那个fd的io可用时,调用accept接受连接。其实是类似于nginx的做法。中间涉及到epoll的惊群问题以及负载均衡的处理。这种模型对应于业务无状态,没有交互关系的时候比如简单。
什么是"惊群"问题。
惊群效应是指当一个fd的事件被触发时,所有等待这个fd的线程或进程都被唤醒。这样产生的问题是系统做了一些无意义的调度和上下文切换,会影响性能。
比如说listen以后fork出多个进程,在同一个fd上面在accept,有新的连接进来时,所有进程的accept都会返回,但是只有一个进程会读到数据,就是惊群。在Linux2.6以后accept已经不会出现惊群,只有一个进程会被唤醒。较新的系统也一般都解决了accept惊群的问题。我在自己mac上面测试了一下accept,没有出现惊群。
对于epoll和select这类,目前内核并没有解决惊群问题。可以在业务层做处理。nginx是通过加锁,多个子进程有一个锁,谁拿到锁,谁才可以将accept的fd加入到epoll队列中。其它进程没拿到锁,就不会把监听的fd加到epoll中,于是不会导致所有子进程的epoll被唤醒。
为什么accept解决了惊群问题,而epoll没解决呢?我猜想可能是因为accept只是一个资源,而epoll操作多个资源,数据不是互斥的。实现难度以及内核中做锁处理的性能影响,就没做这个feature。跟Go语言中select操作的场景可能有点类似。
vvvvvvvvvvGo语言vvvvvvvvvvvvvvv
Go的调度加上P这层,到底比之前M+G好在哪里
为了向完全不了解Go语言的人讲明白这个问题,我需要做一个类比:既然有进程了,为什么还需要线程?
进程是资源管理的基本单位,而线程是调度的基本单位。进程拥有的资源,比较明显的包括CPU内存这类,更广义上的还有打开的文件描述符,共享内存,锁,甚至信号处理函数等都可以算。切换进程时,硬件上下文和页表都需要切换。线程切换时需要处理的资源就更少,于是切换代价更小。扯远了,但是其实这个类比还是有一点是相似的。
回到Go的调度器,我认为引入P的好处可以用两点概括:
- 降低全局资源的争用
- 提升资源的利用率
P的加入为什么降低了全局资源的争用?在M+G的结构中,调度是使用了单个全局锁用来保护所有的goroutine相关的操作,创建销毁等。锁的粒度比较大,竞争会比较严重。加入P这一层以后,就变成了两级调度,M获取一个P以后就可以依次去执行挂在P上面的G,不需要加锁从全局队列获取。
再看第二点。一个很明显能看到一个事实:在M处于idle或者syscall的时候,它是不需要资源的。跟之前进程和线程类似—资源处理的优化。P代表的是执行Go代码时需要的资源。资源都被放在了P中而不是M中,当执行到syscall时直接将P从M中剥离出来,只让M去阻塞。资源P可以被其它M获取后继续运行。
之前由于G必须在M之间可随意切换,每个M都必须可以执行任何的G,于是它必须带着资源去睡眠,这是极大的浪费。
Go的内存分配的实现是使用的tcmalloc的那一套,tcmalloc为每个线程维护一个本地的内存分配池,只有当线程的分配池用尽时,才会向全局去取,这样可以极大地降低加锁开锁。在之前的结构中,有一个本地分配池MCache,MCache是每个M一个。事实上不运行G的M(进入系统调用)是不需要MCache的,造成内存资源浪费并且数据的局部性不友好。
添加P这层的修改只是做了两个事情:把一些中心化的变量移到P中(第1点)。把一些M中的跟执行活跃的G相关的变量移到P中(第2点)。
Go在大量system call的时候,M是否会增加?
这个问题需要说一下Go语言是如何处理系统调用的。当进入系统调用时,会保存硬件上下文(PC,SP很少几个寄存器),修改结构里的状态信息。接下来的动作是这个问题的重点:将P从M剥离,切换到其它的M上面。在M不够的时候,都会起一个新的M来运行P,所以,M是会增加的。
当M从系统调用返回后,它会尝试去拿到P然后执行G。如果拿不到P了,则会退出并回收线程。
但是还有一些细节,Go把系统调用的处理分成了会阻塞的系统调用和不会阻塞的系统调用。只有会阻塞的系统调用能导致P的切换,非阻塞的系统调用是能够立即返回的。对于网络io目前会复用线程的,设置了NONBLOCK,当io操作无法立即完成时,只是将G移动到阻塞队列中。后台做epoll,当io可用时再将G变成ready。
disk io没有优化时,多个goroutine同时执行磁盘io会产生过多额外的线程。
NUMA解释一下
NUMA是Non-uniform memory access的缩写。CPU的速度是越来越快,核也越来越多。此前它们是通过北桥连接到内存,但是总线带宽是有限的,慢慢的成为了瓶颈。于是新的硬件架构中,把内存控制器(原本北桥中读取内存的部分)做个拆分,平分到了每个核上。导致的结果是,当CPU访问属于自身的内存,才会有较短的响应时间。而如果需要访问其他CPU的内存时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了。也就是非一致的内存访问。
新的硬件架构为内核调度(也包含Go的runtime的调度)带来了复杂性的挑战。
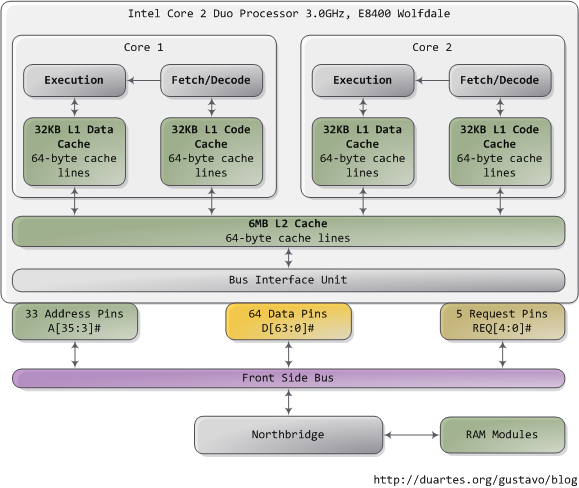
缓存友好。L1缓存是多大。CPU的硬件结构。
CPU不再是按字节访问内存,而是以64字节为单位(x86)的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的。
内存的顺序访问时,接下来的地址都落在缓存内,便是缓存友好的。跳转语句或者随机的访存,cache会miss,缓存不友好。
cache条目中要包含以下信息:
- cache line
- tag : 标记cache line对应的主存地址
- flag : 一些标记位,是否invalid,是否dirty等
不同硬件的L1缓存的大小不一定相同,常见的64k,比如随便在网上找的一个数据,Core i5-750是每核32K数据缓存,32K指令缓存。
CPU硬件结构取这里的一张图:
vvvvvvvvvv分布式存储vvvvvvvvvvvv
paxos和raft
aerospike对SSD具体做过哪些优化
直接写祼盘设备:跳过文件系统,因为操作系统的页缓存造成有些请求在16-32ms才完成,以及3%-5%超过1ms
索引全内存:SSD的擦除次数是有限的,修改索引时不需要访问ssd,减少SSD的损耗
多线程IO:SSD跟磁盘不一样,有多个控制器,并行可以发挥出性能。
写大块读小块:低的写放大和读延迟
Log structured file system, "copy on write"
vvvvvvvvvvv系统vvvvvvvvvvvvvv
shm和mmap区别是什么
shm的共享内存,即使所有访问共享内存的进程都已经正常终止,共享内存区仍然存在(除非显式删除共享内存)。而mmap的内存在进程退出时会自动释放。
shm共享内存中的数据不可以写到实际磁盘中,而mmap映射普通文件中以将数据写到磁盘中。
mmap有哪些使用场景
内存分配。常用的内存库的实现,对于大块的内存是通过mmap申请,然后自己去管理内存池的。
进程间共享内存。这是做IPC的一种方式,可以匿名映射然后fork在有亲缘关系的进程间共享内存,也可以映射到文件在不同进程间共享内存。
内存映射IO来读写文件。可以避开内核和用户空间的数据传输,对于大数据IO有性能优势。
mmap映射文件的时候进程被kill掉是否会刷磁盘
按书上的说法应该是:不能保证。
内核会自动将MAP_SHARED映射内容上的变更写到底层文件中,但是并不保证这种同步操作何时发生。
不管正常退出或异常退出,在进程退出时系统会执行一些动作,其中包括解除该进程的映射区域。但是解除映射并不会调用msync。为了确保一个共享文件映射的内容被写入到底层文件中,在munmap之前一定要手动调用msync。
简单地测试了一下,在自己的mac上,以及在linux上,kill-9,其实数据都刷进去了。不过得按书上说法来。
vvvvvvvvvvv网络vvvvvvvvvvvvvv
TIME_WAIT和CLOSE_WAIT状态。大量连接处理CLOST_WAIT状态,可能是什么原因导致的。
主动关闭连接的一方,会进入到TIME_WAIT状态,关等待2msl的超时。被动关闭的一方,收到fin后会进入到 CLOSE_WAIT状态。
之前遇到过一个大量CLOSE_WAIT的场景是同事写的爬虫去网上探测可用的http代理。极短时间内累积了大量关闭的短连接。
网上有看到的有服务器大量连接数据库后,没有释放资源,导致超时之后,被数据库那边关闭连接。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK