

瞭解神秘的 ZK-STARKs
source link: https://medium.com/taipei-ethereum-meetup/%E7%9E%AD%E8%A7%A3%E7%A5%9E%E7%A7%98%E7%9A%84-zk-starks-ee56a697af76
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
瞭解神秘的 ZK-STARKs
上一篇關於 zkSNARK扯到太多數學式,導致很難入手,這次介紹 STARK 會盡量減少數學式,以原理的方式跟大家介紹。
STARK 被視為新一代的 SNARK,除了速度較快之外,最重要的是有以下好處1. 不需要可信任的設置(trusted setup),以及
2. 抗量子攻擊
但 STARK 也沒這麼完美,STARK 的證明量(proof size)約 40–50KB,太佔空間,相較於 SNARK 只有288 bytes,明顯大上幾個級距。此外,這篇論文發佈約兩年的時間,就密碼學的領域來說,還需要時間的驗證。
STARK 的 S 代表了擴展性(Scalable),而T代表了透明性(Transparency),擴展性很好理解,透明性指的是利用了公開透明的算法,可以不需要有可信任的設置來存放秘密參數。
SNARK 跟 STARK 都是基於多項式驗證的零知識技術。差別在於,如何隱藏資訊、如何簡潔地驗證跟如何達到非互動性。
快轉一下 SNARK 是如何運作的。
Alice 有多項式 P(x)、Bob有秘密 s,Alice 不知道 s、Bob 不知道 P(x)的狀況下,Bob 可以驗證P(s)。藉由同態隱藏(Homomorphic Hindings)隱藏Bob的 s → H(s),藉由 QAP/Pinocchio 達到了簡潔地驗證,然後把 H(s) 放到CRS(Common Reference String),解決了非互動性。細節可以參考之前的文章 。
問題轉換
零知識的第一步,需要先把「問題」轉成可以運算的多項式去做運算。這一小節,只會說明怎麼把問題轉成多項式,至於如何轉換的細節,不會多琢磨。
問題 → 限制條件 → 多項式
在 SNRAK 跟 STARK 都是藉由高維度的多項式來作驗證。也就是若多項式為: x³ + 3x² + 3 = 0,多項式解容易被破解猜出,若多項式為 x^2000000 + x^1999999 + … 則難度會高非常多。
第一步,先把想驗證的問題,轉換成多項式。
這邊以Collatz Conjecture為例子,什麼是Collatz Conjecture呢?(每次都用Fibonacci做為例子有點無聊 XD)
1. 若數字為偶數,則除以2
2. 若數字為奇數,則乘以3再加1 (3n+1)
任何正整數,經由上述兩個規則,最終結果會為 1 。(目前尚未被證明這個猜想一定成立,但也還未找出不成立的數字)
52 -> 26 -> 13 -> 40 -> 20 -> 10 -> 5 -> 16 -> 8 -> 4 -> 2 -> 1.
把每個運算過程的結果紀錄起來,這個叫做執行軌跡(Execution Trace),如上述52 -> 26 -> … -> 1。接著我們把執行軌跡轉換成多項式(由執行軌跡轉成多項式不是這裡的重點,這裡不會贅述,細節可以參考 StarkWare的文章 )如下

合成多項式
接著就把這四個限制條件的多項式合成為一個,這個最終的多項式就叫做合成多項式(composition polynomial),而這個合成多項式就是後面要拿來驗證的多項式。
就像一開始提的,SNARK跟STARK都是使用高維度多項式,接著,來介紹STARK是藉由哪些方式,達到零知識的交換、透明性(Transparency)跟可擴展性(Scalability)。
修改多項式維度
這一步是為了後面驗證做準備的。在驗證過程使用了一個技巧,將多項式以2的次方一直遞減為常數項(D, D/2, D/4 … 1),大幅減低了驗證的複雜度。因此,需要先將多項式修改為2^n維度
假設上述的每個限制多項式(不是合成多項式喔)為Cj(x),維度為 Dj,D >= Dj 且 D 等於2^n,為了達到 D 維度,乘上一個維度(D -Dj)的多項式,

所以最終的合成多項式,如下

其中的αj、βj是由驗證者(verifier)所提供,所以最終的多項式是由證明方(prover)跟驗證方所共同組成。
*這小節的重點是將多項式修改成D維度,覺得多項式太煩可忽略
FRI 的全名是”Fast RS IOPP”(RS = “Reed-Solomon”, IOPP = “Interactive Oracle Proofs of Proximity”)。藉由FRI可以達到簡潔地驗證多項式。在介紹FRI 之前,先來討論要怎麼證明你知道多項式 f(x) 為何?
RS 糾刪碼:
糾刪碼的概念是把原本的資料作延伸,使得部分資料即可以做驗證與可容錯。其方式是將資料組成多項式,藉由驗證多項式來驗證資料是否正確。舉例來說,有d個點可以組成 d-1 維的多項式 y = f(x),藉由驗證 f(z1) ?= y,來確定 z1是否是正確資料。
回到上面的問題,怎麼證明知道多項式?最直接的方式就是直接帶入點求解。藉由糾刪碼的方式,假設有d+1個點,根據Lagrange插值法,可以得到一個 d 維的多項式 h(x),如果如果兩個多項式在(某個範圍內)任意 d 點上都相同( f(z) = h(z), z = z1, z2…zd),即可證明我知道 f(x)。但是我們面對的是高維度的多項式,d 是1、2百萬,這樣的測試太沒效率,且不可行。FRI 解決了這個問題,驗證次數由百萬次變成數十次。
降低複雜度
假設最終的合成多項式為 f(x),藉由將原本的1元多項式改成2元多項式,以減少多項式的維度。假設 f(x) = 1744 * x^{185423},加入第二變數 y,使 y = x^{1000},所以多項式可改寫為 g(x, y) = 1744*x^{423}*y^{185}。藉由這樣的方式,從本來10萬的維度變成1千,藉由這種技巧大幅降低多項式的維度。在 FRI 目前的實做,是將維度對半降低 y = x²(f(x) = g(x, x²))。
此外,還有另一個技巧,將一個多項式拆成兩個較小的多項式,把偶數次方跟奇數次方拆開,如下:
f(x)= g(x²) + xh(x²)
f(x) = a0 + a1x + a2x² + a3x³ + a4x⁴ + a5x⁵
g(x²) = a0 + a2x² + a4x⁴, (g(x) = a0 + a2x + a4x²)
h(x²) = a1x + a3x² + a5x⁴, (h(x) = a1 + a3x + a5x² )
藉由這兩個方法,可以將高維度的多項式拆解,重複地將維度對半再對半,以此類推到常數項。而 FRI 協議在流程上包含兩階段 — 「提交」跟「查詢」。
提交階段:
提交階段就如同上述過程,將多項式拆解後,由驗證者提供一亂數,組成新的多項式,再繼續對多項式拆解,一直重複。
f(x) = f0(x) = g0(x²) + x*h0(x²)
==> f1(x) = g0(x) + α0*h0(x), ← α0(驗證者提供)
==> f2(x) = g1(x) + α1*h1(x), ← α1(驗證者提供)
==> . . .
查詢階段:
這個階段要驗證證明者所提交的多項式 f0(x), f1(x), f2(x), … 是否正確,這邊運用一個技巧,帶入任意數 z 及 -z(這代表在選域的時候,需滿足 L²= {x²:x ∊ L},這邊不多提)。所以可以得
f0(z) = g0(z²) + z*h0(z²)
f0(-z) = g0(z²) -z*h0(z²)
藉由兩者相加、相減,及可得g0(z²)、h0(z²),則可以計算出f1(z²),再推導出f1(x),以此類推驗證證明者傳來的多項式。

藉由FRI(RS糾刪碼、IOPs),將驗證次數由數百萬降至20–30次(log2(d)),達到了簡潔地驗證。不過,我們解決了複雜度,但還有互動性!
* 與SNARK比較 :SNARK在驗證方面利用了QAP跟Pinocchio協定。
藉由 Micali 建構(Micali construction)這個概念來解釋如何達到非互動的驗證。Micali 建構包括兩部分,PCPs(Probabilistically checkable proof)跟雜湊函數。PCPs 這是一個隨機抽樣檢查的證明系統。簡單來說,證明者產出一個大資料量的證明(long proof),經由隨機抽樣來驗證這個大資料量的證明。過程大約是這樣,證明者產出證明𝚿,而驗證者隨機確認 n 個點是否正確。
在STARK,我們希望達到:1.小的證明量,2.非互動。隨機抽樣可以讓達到小的證明量,那互動性呢? 想法很簡單,就是預先抽樣,把原本 PCPs 要做的事先做完,然後產出只有原本證明 𝚿 抽樣出的幾個區塊當作證明。但想也知道,一定不會是由證明者抽樣,因為這樣就可以作假。這裡是使用 Fiat-Shamir Heuristic 來作預先取樣。
首先,先把證明 𝚿組成 merkle tree,接著把 merkle root 做雜湊可得到一亂數 𝛒,而 𝛒 就是取樣的索引值。將利用𝛒取出來的區塊證明、區塊證明的 merkle tree 路徑跟 merkle root, 組一起,即為STARK 證明 𝛑。
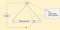
到目前,只使用雜湊函數這個密碼學的輕量演算法。而雜湊函數的選擇是這個證明系統唯一的全域參數(大家都需要知道的),不像是 SNARK 有 KCA 使用的(α, β, 𝛾)等全域的秘密參數,再藉由 HH(同態隱藏)隱藏這些資訊來產生 CRS。因為證明的驗證是靠公開的雜湊函數,並不需要預先產生的秘密,因此 STARK 可以達到透明性,也不用可信任的設置。
接著,將FRI中需要互動的部分(驗證者提供 α 變數),使用上述的 PCP + Fiat-Shamir Heuristic, 即可達到非互動性。

* 與SNARK比較: SANRK 的非互動性是將所需的全域參數放到CRS中,因為全域參數是公開的,所以CRS裡的值使用了 HH 做隱藏。
大部分證明系統,會使用算數電路來實作,此時,電路的複雜程度就關係到證明產生的速度。 STARK 的雜湊函數選用了電路複雜度較簡單的 MIMC,計算過程如下:

這樣的計算有另一個特性,就是無法平行運算,但卻又很好驗證,因此也很適合 VDF 的運算。Vitalik有一個使用 MIMC 作為 VDF 的提案。
ps. 反向運算比正向慢百倍,所以會是反向計算,正向驗證
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK