

基于FPGA:车牌识别应用的图像后处理
source link: https://blog.csdn.net/weixin_46423500/article/details/111403297
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
基于FPGA的图像处理应用,虽然已经在绝大多数的高分辨率、高帧率的机器视觉产品中普及,但仍然很少有资料可以学习参考。而在图像处理领域,其实也有已经非常成熟的理论和应用,市面上的图书也比比皆是,但是我们依然很难找到能和FPGA碰撞出“火花”的好作品。——特权同学。
一、硬件选择
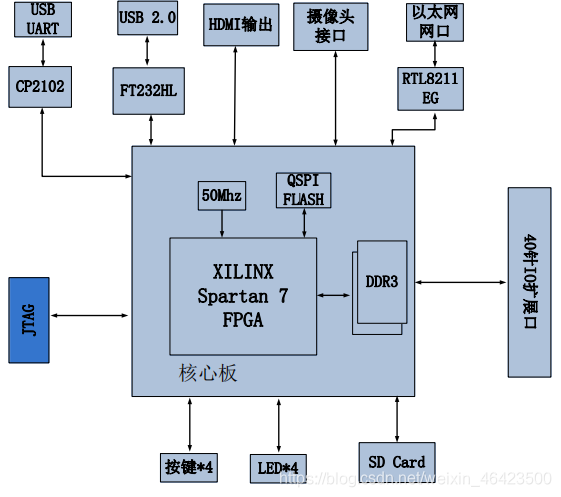
1.开发板

AC7050(核心板型号,下同)核心板,是基于 XILINX 公司的 Spartan 7 系列的XC7S50FGGA484 这款芯片开发的高性能核心板,具有高速,高带宽,高容量等特点,适合高速数据通信,视频图像处理,高速数据采集等方面使用。同时这块板有接近5万逻辑门,适合做纯FPGA项目。
2.摄像头选择

3.显示屏

二、图像处理步骤
我们以目前技术非常成熟且应用非常广泛的车牌识别应用为例,通过雷达等手段定位探测到有效距离范围中有汽车通过时,图像传感器将触发采集图像用于后端的牌照识别。
进行车牌识别即图像后处理的过程,如下图所示,通常需要以下几个步骤:
1、牌照定位,定位图片中的每个字符分割出来;
2、牌照字符分割,把牌照中的每个字符分割出来;
3、牌照字符识别,对分割好的单个字符进行识别,最终组成牌照1号码。
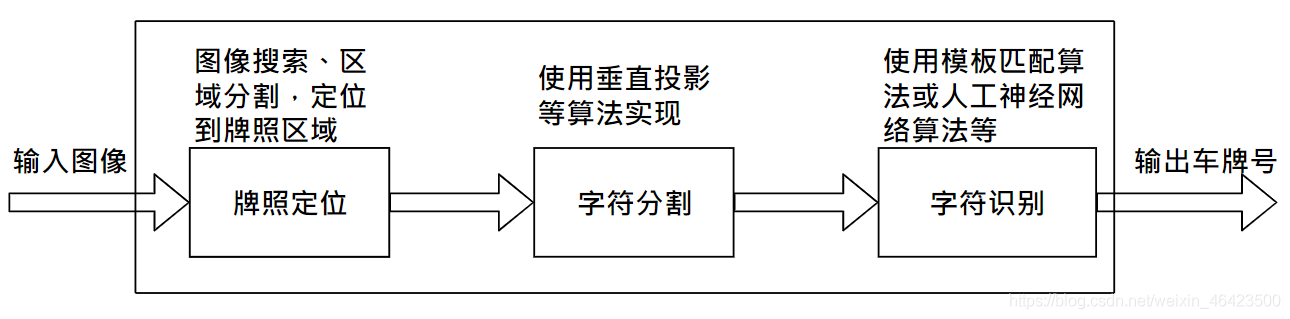
1.牌照定位
自然环境下,汽车图像背景复杂、光照不均匀。如何在自然背景中准确地确定牌照区域是整个识别过程的关犍。首先对采集到的视频图像进行大范围的相关搜索,找到符合汽车牌照特征的若干区域作为候选区,然后对这些候选区域做进一步分析、评判,最后选定一个最佳的区域作为牌照区域,并将其从图像中分离出来。
2.牌照字符分割
完成牌照区域的定位后,再将牌照区域分割成单个字符,然后进行识别。最常见的方法就是根据车牌投影、像素统计特征对车牌图像进行字符分割。它的基本原理是对车牌图像进行逐列扫描,统计车牌字符的每列像素点个数,并得到投影图,根据车牌字符像素统计特点(投影图中的波峰或者波谷),把车牌分割成单个独立的字符。
3.牌照字符识别
牌照字符识别方法主要有基于模板匹配的算法和基于人工神经网络的算法。基于模板匹配的算法首先将分割后的字符二值化并将其大小缩放为字符数据库中模板的大小,然后与所有的模板进行匹配,选择最佳的匹配作为结果。基于人工神经网络的算法有两种:一种是先对字符进行特征提取.然后用所获得特征来训练神经网络分配器;另一种是直接把图像输入网络,由网络自动实现特征提取直至识别出结果。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK