

Better Preference Predictions: Tunable and Explainable Recommender Systems
source link: https://blog.insightdatascience.com/tunable-and-explainable-recommender-systems-cd52b6287bad
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


Are you looking to transition into the field of machine learning in Silicon Valley, New York, or Toronto?Start your application today (deadline is June 24th) or learn more about the Artificial Intelligence program at Insight!
Are you a company looking to hire AI practitioners? Feel free to get in touch to get involved in the Insight AI Fellows Program.
The Waste of Unwanted Recommendations
How many times has the following scenario happened to you? You return home from work. It’s been a long day and you just want to relax and watch some Netflix. Then you realize your little sister has been watching mermaid TV shows on your account and now you can’t relax because of all the mermaid movie recommendations?!
Maybe that occurrence is specific to me, but it is inevitable for media users to get locked into a negative feedback loop of unwanted/irrelevant ads or recommendations (recs). We are constantly bombarded with recs telling us what to eat, buy, and wear*, yet there is little we can do to understand our recs and even less we can do to tune our preferences efficiently. Not only are undesired or irrelevant recs wasting our time, but they are also costing media companies millions of dollars every year. Media companies want to give you useful recs to keep you happy and engaged with their platforms, but why do they have such a hard time tuning our individual recommendation preferences? What makes this process so difficult?
*Warning: Do not click on any ads for yoga pants or you will be forever locked in a negative feedback legging ad loop.
As machine learning (ML) algorithms increase in popularity and the “black boxes” of neural networks in deep learning (DL) become the industry standard, pulling out the demographic information and the user history responsible for each undesired rec becomes next to impossible to achieve. How much do we need to sacrifice in performance to gain accessibility? That is the million dollar (industry) question.
Scientists and engineers have long acknowledged a speed vs. accuracy tradeoff in tech fields, but in the recent booming world of artificial intelligence (AI), we are now entering a trade-off between sophisticated models and the interpretability of their predictions. This lack of transparency in recs is what led me to build my own recommender system (RS) called Project Orient as an Insight AI Fellow. Project Orient is a movie RS where the attributes that determine the recs are not only explainable but actually tunable to the individual consumer. With a pipeline built from ML, simple geometry and novel hacks, Orient serves as a proof of concept for a tunable and explainable RS.
Feel free to follow along with Orient via:
- Downloaded the command line user interface from my GitHub repository and/or checking out the source code.
- Streamlit’s 🎬 Movie Recommendation Engine — a guide to making Orient! Set up in 4 parts corresponding to the 4 weeks of an Insight project: Week1 | Week2 | Week3 | Week4.
The Movie RS Pipeline
Let’s start our journey into Orient by understanding a typical movie RS pipeline with a user — We will call him Tom. Tom, has a list of personal attributes and a set of criteria for his movie recs. In order to address the cold start problem, I will consider Tom a new user and will generate recommendations for him without any knowledge of his past movie ratings. The first step, in this case, is to match Tom with a set of similar users and then to make movie recs for Tom based on their movie ratings.
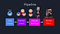
Recommender systems have two main filtering methods: content-based filtering and collaborative filtering. Content-based filtering recommends items similar to the user’s past purchases, but it does not typically incorporate modern ML methods. Collaborative filtering (CF) on the other hand can be divided into Item-Item CF (“Users who liked this item also liked …”) and User-Item CF (“Users who are similar to you also liked …”). Some RS’s use one type of filtering, while other systems use a hybrid approach, I focused on a User-Item CF model for Orient.
Dataset
Since the usefulness of CF models is dependent on how large and robust your dataset is, I will be using the MovieLens Dataset complete with 100K movie ratings, 1,682 movies, and 943 users (with the same latent attributes as Tom). If you are following along with my GitHub repo feel free to download the 1M/10M/20M datasets for a larger variety of recent movies (but use with caution as the file structure may have changed).
Tom’s Orient Scenario
Once Tom has entered some characteristics about himself (male, engineer, age 30, from CA) and some movie preferences (genres: action and adventure, minimum average movie rating: 3-star, and the number of movies to be recommended: 3 movies). Using these factors and a cosine similarity function, Orient generates the following three movies for Tom:

The concept for Orient is that after recs are generated in a given media platform, the user is then given more options to better understand what led to the recs. Ideally, this could be formatted as an information button that the user would click on to fine-tune their own contributed data. In the case of Orient, this info button leads Tom into the movie selection process. Tom is made aware that his movie recommendations are determined from the 10 (Orient’s default) most similar user profiles to his own, where the average similarity is 98%. The number of most similar users, in this case, is a tunable factor. What “tunable factor” means is that Tom can choose to only use the top 5 most similar user profiles or even use the 300 most similar user profiles to generate his movie recommendations. Increasing the number of similar user profiles can generate a more diverse set of movies, but might result in movies Tom would be less interested in.
Tom is also led into the attribute breakdowns of those 10 most similar user profiles and can draw his own conclusions as to the impact his attributes have on his recommendations. For example, all the movies recommended to Tom were rated by male users, and 6 of the 10 most similar user profiles had a technical profession. Tom may be satisfied with these numbers and will move on to enjoy his movie night, or he may choose to further customize his recommendations.

Scaling Attributes
In Orient, any user is able to scale the importance of each of their attributes from 0–100. The key importance in determining which attributes contribute the most to your movie recommendations is how the attributes are scaled in relation to each other. So, if the most important factor for Tom in determining his movie recs is occupation, he must weight that attribute relatively higher than the rest of his attributes.

After Tom scaled his engineering occupation as the highest attribute, his movie recommendations shifted to Sci-Fi! Now that we have seen a brief demo of Orient, let me run you through how Orient was built.

Finding Similar Users
Since I used User-Item CF, I needed to figure out a way to best match Tom with similar users in order to provide movie recommendations. I started with what I call a “one-hot encoded filter” to apply the scaling Tom gave to each of the four attributes (Age, Gender, Location, Occupation) above. This is done by multiplying the normalized scaled value (1 for occupation and 0 for age in Tom’s case) through each corresponding one-hot encoded column. I then use a cosine similarity function to take the most similar user profiles to Tom’s new matrix. I use a cosine similarity of at least .7 as Orient’s default, but this factor can also be changed.
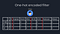
The problem with one-hot encoding is that each attribute vector is equidistant from every other attribute vector. While this is fine for continuous values like age, which fall on a continuous scale and are easy to normalize, one-hot encoding is not ideal for categorical data like occupation, because some occupations are more similar than others. For example, an engineer might have more movies in common with a technician than an entertainer. For this reason, after taking the user profiles that have a similarity score to Tom higher than .7, I used Google’s word2vec and the distance to a given word to vectorize specific attributes. I chose to do this for occupation and gender but would like to extend the idea in the future to more non-binary attributes. I again used a cosine similarity function to find the 10 most similar users to Tom.

Lastly, movies for Tom!
If you’re like me, you probably exit the movie as soon as it ends without bothering to submit a rating... As you might suspect, this leads to a very sparse user-movie matrix (only 7% of the entries are filled). We have to address the sparsity problem before we can give movie recs to Tom. And since some users consistently rate movies conservatively (1–2 stars), while other users are more generous with their movie ratings (4–5 stars), we need to first normalize all user’s movie ratings to have an average of 3 stars.
Next, we use low-dimensional representations to predict user ratings for unseen movies. This is done by decomposing a high dimensional matrix into two lower-dimensional matrices using Keras. Matrix factorization in Keras with an Adam optimizer is used because it outperforms other machine learning algorithms for predicting ratings (Mean Average Error = 0.693). Not only does this address the sparsity issue but, by using matrix factorization, we increase the likelihood of excellent, but not well-known movies being recommended.

Voilà! Now,when Tom gets his movie recommendations he has options for explainability and adjustability. Tom not only can see why these particular movies were recommended to him, but he can also tune his attributes to align with his preferences.
Another interesting result occurs after changing Tom’s gender to female and scaling it to 100 while scaling the three other attributes to 0. This changes Tom’s top Action & Adventure recommendations from Die Hard to Titanic. What we see from this is the bias present in movie recommendations. But what comes first, the click or the recommendation? While this chicken or egg scenario is still up for debate, identifying a way to reduce that bias by tuning the factor directly related to the recommendation is a step in the right direction for putting ad control back in the hands of consumers.
Takeaways
While RS’s take into account many more than 4 attributes in addition to the user history, and are in general much more complex than this method (which was a 4-week project based on a project proposed by Insight), Orient is a proof-of-concept showing that each ad recommendation we receive on media sites can be understood. Neither companies nor consumers benefit from users clearing their history due to irrelevant ads. With the right combination of models and tools, we will be able to adjust our preferences transparently across multiple platforms…and I can finally be rid of the mermaid movies.
For more content like this, follow Insight and Amber on Twitter.
Amber is an astrophysicist and machine learning engineer, after completing the Insight Data Science Fellowship in Artificial Intelligence in fall 2018 she joined Insight as an AI Program Director. She hopes to make meaningful contributions to the field of AI and make STEM fields more approachable through her Astronomer Amber science communication channels.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK