

在C语言程序中,为什么二维数组赋值的顺序会影响效率?
source link: https://blog.popkx.com/%E5%9C%A8c%E8%AF%AD%E8%A8%80%E7%A8%8B%E5%BA%8F%E4%B8%AD-%E4%B8%BA%E4%BB%80%E4%B9%88%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E8%B5%8B%E5%80%BC%E7%9A%84%E9%A1%BA%E5%BA%8F%E4%BC%9A%E5%BD%B1%E5%93%8D/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在C语言程序中,为什么二维数组赋值的顺序会影响效率?
学习C语言最有效的方法就是多做实验,很多初学者深知这一点。小明在学到二维数组时,尝试写了一段给二维数组赋值的代码,他发现一个奇怪的现象:交换赋值顺序,效率是不同的。请看下面这两段C语言代码:
int test1 ()
{
int i,j;
static int x[4000][4000];
for (i = 0; i < 4000; i++) {
for (j = 0; j < 4000; j++) {
x[j][i] = i + j;
}
}
return 0;
}
int test2 ()
{
int i,j;
static int x[4000][4000];
for (j = 0; j < 4000; j++) {
for (i = 0; i < 4000; i++) {
x[j][i] = i + j;
}
}
return 0;
}

这两个版本的C语言代码几乎完全相同,唯一的不同点在于交换了 i 和 j 变量,但是编译成C语言程序执行后,消耗的时间却是不同的,这是怎么回事呢?
可能有读者认为这两段C语言代码产生效率上的差异,是因为编译器处理这两段代码时,产生的指令不同。其实不是的,这两段“对称”的C语言代码产生的指令是一致的,请看:
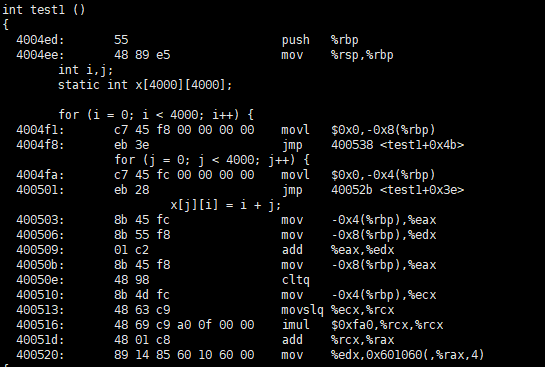
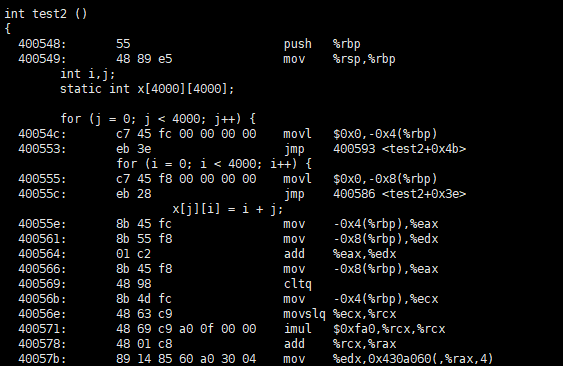
仔细对比 test1() 和 test2() 对应的指令,我们很难发现二者有什么不同。事实上,二者运行的效率差异主要来自于“缓存命中率”。简单来说,就是连续操作C语言中的多维数组的最后一个维度最快,因此 test1() 中的赋值操作几乎每次都会错过缓存,而 test2() 中的赋值操作缓存命中率更高一些,因此 test2() 执行所消耗的时间更少。
在很多C语言初学者的脑海里,二维数组各个元素在内存中的分布可能是下面这样的:
但是计算机中的内存地址始终是一维的,因此在计算机眼中,二维数组仍然是按照一维排列的:
test2() 中的赋值操作先遍历第二维,这一过程是下图这样的:

此时C语言程序每次访问数组元素,在内存中都是顺序进行的,这对于缓存命中率的提升很有帮助。再来看 test1() 中的赋值操作,它优先遍历第一维,因此访问数组元素的过程是下图这样的:

显然,此时C语言程序访问数组元素在内存中是“跳跃式”的,但是,计算机访问内存各个地址的效率不是都一样的吗?那为什么 test1() 和 test2() 的效率不同呢?
答案就是 test1() 和 test2() 的缓存命中率不同。计算机 CPU 一般都有更加高速的缓存(称为“缓存线(cache line)”,常是 64 字节),访问这一缓存的速度比访问内存的速度要高的多(读者可以对比想象计算机访问内存的速度比访问硬盘数据的速度快得多)。
小明的C语言代码中赋值的元素是 int 型的(常常是 4 字节),因此 64 字节的缓存线可以容纳 16 个连续的整数,CPU 访问这 16 个数据要比访问内存里的 16 个数据快得多,并且 CPU 在加载缓存线数据的时间内,处理相当多的工作。
CPU 在处理 test2() 中的赋值时,可以获取 16 个连续的整数块,然后赋值给数组,重复 4000*4000/16 次,这样的操作在缓存线的支持下相当快,因为 CPU 没有被闲置,总是在处理事务。
再考虑 test1() 中的赋值,缓存线加载了 16 个整数块,但是接着值修改了其中一个整数,因此它需要重复 4000*4000 次,相比于 test2() 中的赋值,需要 16 倍的内存“回迁”次数。而 CPU 实际上需要花时间坐着干等内存操作完成,因此 test1() 的效率要低一些。
本节主要讨论了一个看似“灵异”的C语言二维数组赋值问题,这无关指令差异,更多的是缓存命中差异带来的效率差异。但是读者应该明白,并不是所有的计算机程序都如此,例如 Fortran 语言中,test1() 中的赋值效率要高于 test2() 中的赋值效率,因为它将二维数组在内存中展开时,是按照“列”优先排列的(C语言是按“行”优先排列的)。
阅读更多: C语言
Recommend
-
36
点击关注上方“ 图解面试算法 ”, 设为“置顶或星标”,一起刷 LeetCode。
-
16
C语言程序如果不关闭打开的文件,会发生什么?为什么要调用fclose() 函数? 发表于...
-
18
网络上似乎一直有种说法:C语言程序运行时要比其他语言编写的程序快得多,因为它“离底层机器很近”,这个说法正确吗?如果正确,那究竟是什么阻止了其他语言编写的程序和C语言程序一样快呢?C语言程序快是因为它简单编程语言其实就是程序员与机...
-
8
vue3使用reactive包裹数组如何正确赋值 2021-01-17 Vue 暂无评...
-
6
什么是前缀和? 前缀和是一种重要的预处理,能大大降低查询的时间复杂度。我们可以简单理解为“数列的前 n 项的和”。这个概念其实很容易理解,即一个数组中,第 n 位存储的是数组前 n 个数字的和。 通过一个例...
-
19
Armin's BlogPOJ1195 Mobile phones(二维树状数组)February 15, 2016题目链接 题意:给定矩阵,对点更新,询问给两个点,求这两个点构成矩形内元素...
-
9
V2EX › JavaScript 一个 async function 数组, 怎样一个一个顺序执行? self...
-
6
js 嵌套数组赋值问题 const arr = Array(2).fill(Array(2).fill(0)); // arr = [[0, 0], [0, 0]] arr[1][1] = 1; // expected: [[0, 0], [0, 1]] // current: [[0, 1], [0, 1]] 为啥给数组第二个元素里的最后一项...
-
6
Python中避免在给多维数组赋值之前判断key是否存在的方法 Python在使用二维及多维数组(dict)时,每次赋值之前都需要判断一维及较小维度上的key是否存在。本文将介绍对于...
-
9
数组类型别名,类型不同却可以赋值是什么情况 aaaa · 大约6小时之前...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK