

为什么逐字节拷贝没有memcpy()函数快,它使用了哪些技巧提升效率?
source link: https://blog.popkx.com/%E4%B8%BA%E4%BB%80%E4%B9%88%E9%80%90%E5%AD%97%E8%8A%82%E6%8B%B7%E8%B4%9D%E6%B2%A1%E6%9C%89memcpy%E5%87%BD%E6%95%B0%E5%BF%AB-%E5%AE%83%E4%BD%BF%E7%94%A8%E4%BA%86%E5%93%AA%E4%BA%9B%E6%8A%80/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
为什么逐字节拷贝没有memcpy()函数快,它使用了哪些技巧提升效率?
在C语言程序开发中,常常需要将 N 个字节从源内存段 pSrc 拷贝到目的内存段 pDest。稍稍有些经验的程序员一般都会调用C语言标准库函数 memcpy() 或者 memmove(),事实上,大多数程序员都会调用这两个库函数实现需求。
为什么逐项赋值没有memcpy() 快?
C语言程序员都是乐于思考的,在调用 memcpy() 函数实现内存拷贝时,往往会思考 memcpy() 函数的实现方式。在一些程序员看来,memcpy() 无非就是下面这样的逐项拷贝:
int i;
for(i=0; i<N; i++)
*pDest++ = *pSrc++;
考虑到 memcpy() 函数可以接收任意类型的源内存段指针和目标内存段指针,用C语言来描述就是 memcpy() 函数接收的源内存段指针和目标内存段指针都是 void * 指针,因此可能还要多一步指针类型转换:
void my_memcpy(void* dst, void* src, unsigned int bytes)
{
unsigned char* b_dst = (unsigned char*)dst;
unsigned char* b_src = (unsigned char*)src;
for (int i = 0; i < bytes; ++i)
*b_dst++ = *b_src++;
}
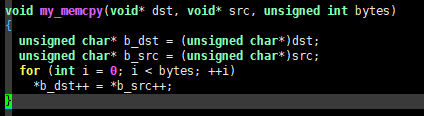
这里转换为 char* 指针只仅作为示例,读者当然可以将其转换为其他类型指针。
乐于动手的C语言程序员一定自己尝试实现过自己的 memcpy() 函数,如果读者尝试过自己的实现,在性能测试中一定能够发现,上述实现的效率并没有 memcpy() 库函数的效率高,这是为什么呢?
memcpy() 函数使用的技巧
既然逐字节赋值拷贝的 my_memcpy() 效率比不上 memcpy() 函数,那么 memcpy() 函数一定使用了某些技巧,到底是什么技巧呢?
前文介绍的 my_memcpy() 实现是将接收到的指针转换成 char * 指针,逐字节拷贝的。但是 memcpy() 函数一般不使用字节指针,而是使用字指针。
看过我之前文章的读者应该明白,CPU 在处理数据时,如果数据严格按照数据总线宽度对齐,那么CPU才能最大效率处理数据。
事实上,memcpy() 函数的实现通常使用 SIMD 指令编写,这使得它能够一次操作 128 位数据。关于 SIMD 指令,以后有机会再讨论。现在读者只需知道,memcpy() 函数一次可以拷贝 16 字节的数据就可以了,这比一次只拷贝 1 字节的数据效率高多了。
改进 my_memcpy() 函数,提升效率的方向
C语言程序员在实际拷贝数据时,要拷贝的数据长度不一定是 16 字节的整数倍,所以 memcpy() 的实现要比 my_memcpy() 的实现复杂得多。
my_memcpy() 的第一个改进是在内存时按照本机字宽度( 32位机器一般是4字节,64位机器一般是8字节)对齐要拷贝的数据,并且使用字指针而不是字节指针拷贝数据,相关的C语言代码如下:
void aligned_memory_copy(void* dst, void* src, unsigned int bytes)
{
unsigned char* b_dst = (unsigned char*)dst;
unsigned char* b_src = (unsigned char*)src;
// Copy bytes to align source pointer
while ((b_src & 0x3) != 0)
{
*b_dst++ = *b_src++;
bytes--;
}
unsigned int* w_dst = (unsigned int*)b_dst;
unsigned int* w_src = (unsigned int*)b_src;
while (bytes >= 4)
{
*w_dst++ = *w_src++;
bytes -= 4;
}
// Copy trailing bytes
if (bytes > 0)
{
b_dst = (unsigned char*)w_dst;
b_src = (unsigned char*)w_src;
while (bytes > 0)
{
*b_dst++ = *b_src++;
bytes--;
}
}
}
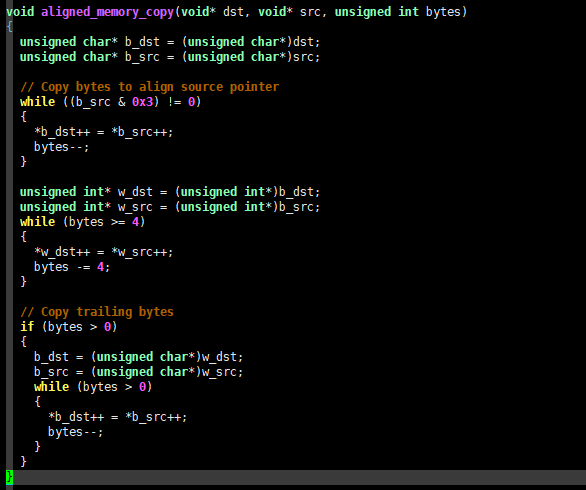
源内存段指针或者目标内存段指针是否正确对齐,在不同架构的机器上将执行不同的操作。例如,在 XScale 处理器上,通过对齐目标内存段指针,在实际性能测试中,我获得了更高的内存拷贝效率。
若想进一步提升内存拷贝的效率,可以将一些C语言代码中的循环展开,便于提高 CPU 缓存的命中率。不过这种方式带来的效率提升会因体系架构的不同而不同,因为 CPU 加载和存储数据的方式可能是不同的。
还有一种提升效率的方式,即手动编写 CPU 加载和存储指令,以控制数据吞吐量。不过这种方式需要借助汇编指令实现,C语言暂时还没有能力实现这样的精细操作。
容易看出,在C语言程序开发中,简单的内存拷贝也并不简单,我们有着相当多的优化空间。C语言程序的灵魂之一就是高效率,而C语言本身提供的都是最基础的操作,因此它是一种相当重视设计的程序语言,作为C语言程序员,我们在设计某个方法时,应该总是想清楚如何才能写出更高效的程序。
阅读更多: C语言
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK