

写一个 Mustache 模板引擎
source link: https://lotabout.me/2016/Write-a-Mustache-Template-Engine/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

写一个 Mustache 模板引擎
前几天在伯乐在线上看到 介绍 mustache.js 的文章。Mustache 是一种模板语言,语法简单,功能强大,已经有各个语言下的实现。那么我们今天就用 python 来一步步实现它吧!
What I cannot create I do not understand.
Richard Feynman
要理解一个事物最有效的方式就是动手创造一个,而真正动手创造的时候,你会发现,事情并没有相像中的困难。
首先要说说什么是编译器,它就像是一个翻译,将一种语言 X 翻译成另一种语言 Y。通常语言 X 对人类更加友好,而语言 Y 则是我们不想直接使用的。以 C 语言编译器为例,它的输出是汇编语言,汇编语言太琐碎了,通常我们不想直接用它来写程序。而相对而言,C 语言就容易理解、容易编写。
但是翻译后的语言 Y 也需要实际去执行,在 C 语言的例子中,它是直接由硬件去执行的,以此得到我们需要的结果。另一些情形下,我们需要做一台“虚拟机”来执行。例如 Java 的编译器将 Java 代码转换成 Java 字节码,硬件(CPU)本身并不认识字节码,所以 Java 提供了 Java 虚拟机来实际执行它。
模板引擎 = 编译器 + 虚拟机
本质上,模板引擎的工作就是将模板转换成一个内部的结构,可以是抽象语法树(AST),也可以是 python 代码,等等。同时还需要是一个虚拟机,能够理解这种内部结构,给出我们需要的结果。
好吧,那么模板引擎够复杂啊!不仅要写个编译器,还要写个虚拟机!放弃啦,不干啦!莫慌,容我慢慢道来~
Mustache 简介
Mustache 自称为 logic-less,与一般模板不同,它不包含 if, for 这样的逻辑标签,而统一用 {{#prop}} 之类的标签解决。下面是一个 Mustache 模板:
Hello {{name}}
You have just won {{value}} dollars!
{{#in_ca}}
Well, {{taxed_value}} dollars, after taxes.
{{/in_ca}}
对于如下的数据,JSON 格式的数据:
{
"name": "Chris",
"value": 10000,
"taxed_value": 10000 - (10000 * 0.4),
"in_ca": true
}
将输出如下的文本:
Hello Chris
You have just won 10000 dollars!
Well, 6000.0 dollars, after taxes.
所以这里稍微总结一下 Mustache 的标签:
- {{ name }}: 获取数据中的 `name` 替换当前文本
-
{{# name }} ... {{/name}}: 获取数据中的 `name` 字段并依据数据的类型,执行如下操作:
- 若
name为假,跳过当前块,即相当于if操作 - 若
name为真,则将name的值加入上下文并解析块中的文本 - 若
name是数组且个数大于 0,则逐个迭代其中的数据,相当于for
- 若
逻辑简单,易于理解。下面就让我们来实现它吧!
模板引擎的结构
如前文所述,我们实现的模板引擎需要包括一个编译器,以及一个虚拟机,我们选择抽象语法树作为中间表示。下图是一个图示:
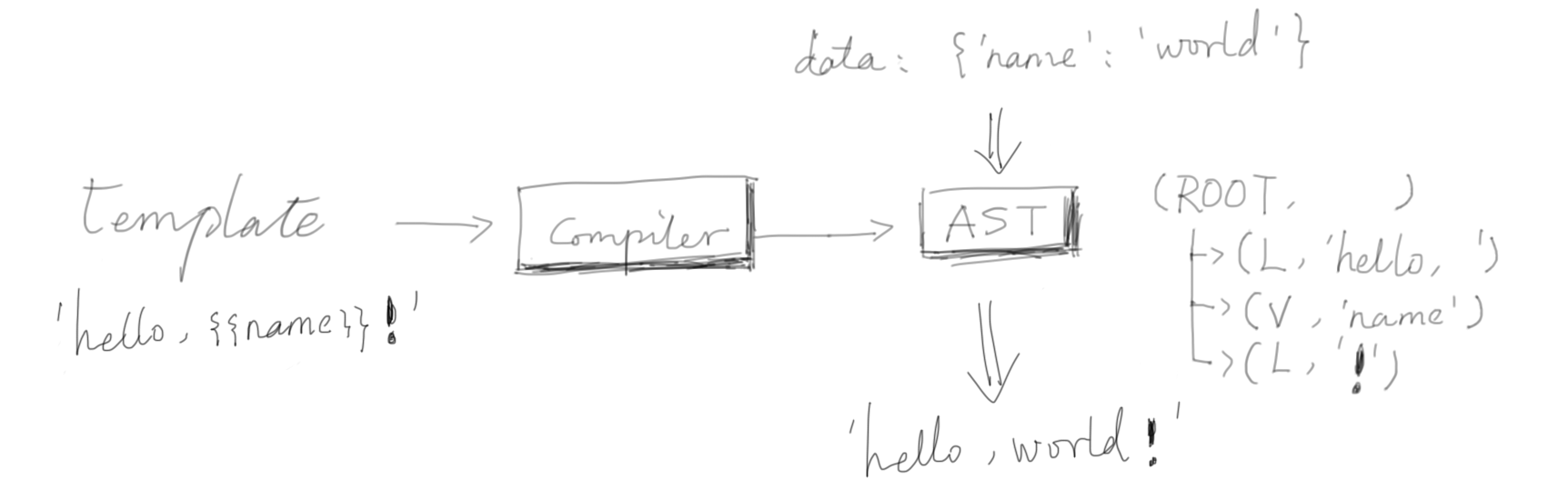
学过编译原理的话,你可能知道编译器包括了词法分析器、语法分析器及目标代码的生成。但是我们不会单独实现它们,而是一起实现原因有两个:
- 模板引擎的语法通常要简单一些,Mustache 的语法比其它引擎比起来更是如此。
- Mustache 支持动态修改分隔符,因此词法的分析和语法的分析必需同时进行。
下面开始 Coding 吧!
上下文查找
首先,Mustache 有所谓上下文栈(context stack)的概念,每进入一个
{{#name}}...{{/name}} 块,就增加一层栈,下面是一个图示: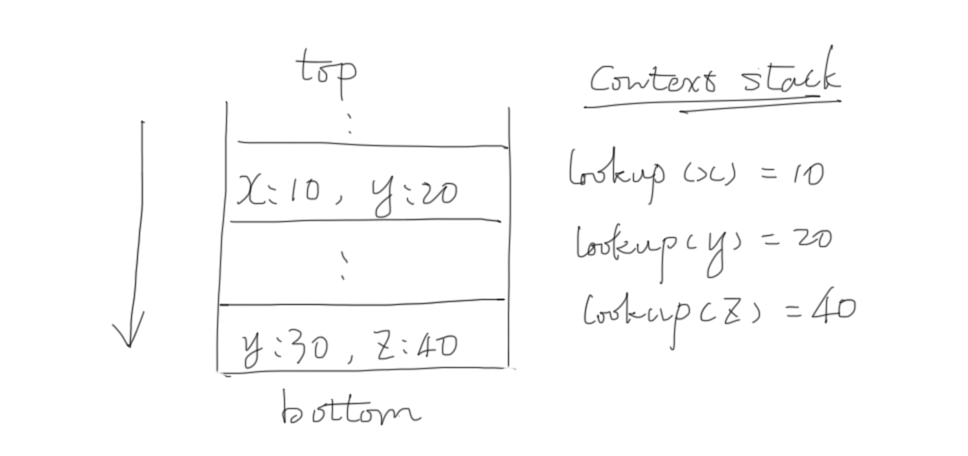
这个概念和 Javscript 中的原型链是一样的。只是 Python 中并没有相关的支持,因此我们实现自己的查找函数:
def lookup(var_name, contexts=()):
for context in reversed(contexts):
try:
if var_name in context:
return context[var_name]
except TypeError as te:
# we may put variable on the context, skip it
continue
return None
如上,每个上下文(context)可以是一个字典,也可以是数据元素(像字符串,数字等等),而上下文栈则是一个数组,contexts[0] 代表栈底,context[-1] 代表栈顶。其余的逻辑就很明直观了。
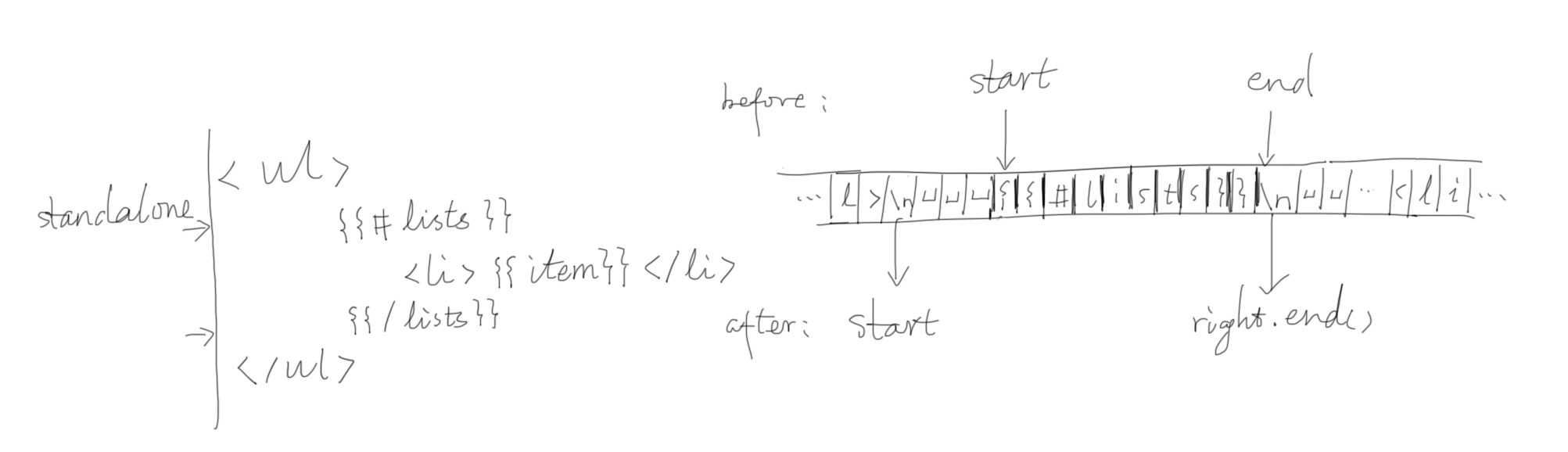
单独行判定
Mustache 中有“单独行”(standalone)的概念,即如果一个标签所在的行,除了该标签外只有空白字符,则称为单独行。判断函数如下:
spaces_not_newline = ' \t\r\b\f'
re_space = re.compile(r'[' + spaces_not_newline + r']*(\n|$)')
def is_standalone(text, start, end):
left = False
start -= 1
while start >= 0 and text[start] in spaces_not_newline:
start -= 1
if start < 0 or text[start] == '\n':
left = True
right = re_space.match(text, end)
return (start+1, right.end()) if left and right else None
其中,(start, end) 是当前标签的开始和结束位置。我们分别向前和向后匹配空白字符。向前是一个个字符地判断,向后则偷懒用了正则表达式。右是单独行则返回单独行的位置:(start+1, right.end())。
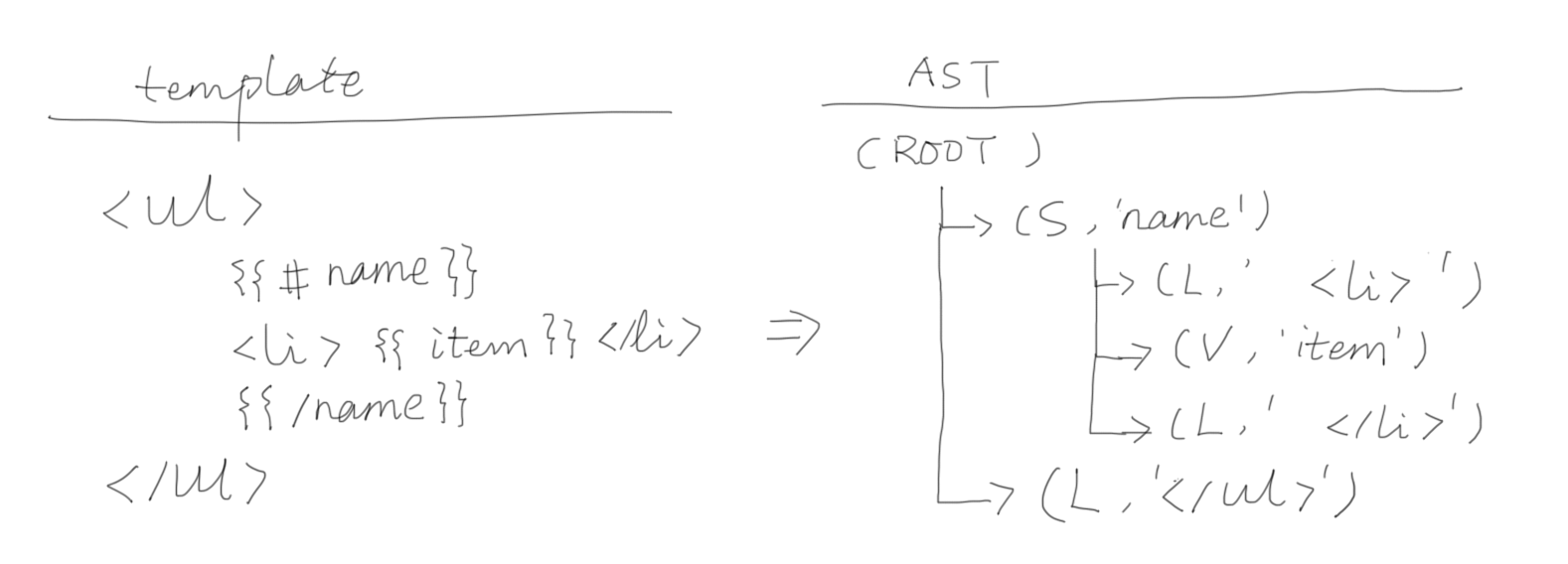
我们从语法树讲起,因为这是编译器的输出,先弄清输出的结构,我们能更好地理解编译器的工作原理。
首先介绍树的节点的类型。因为语法树和 Mustache 的语法对应,所以节点的类型和 Mustache 支持的语法类型对应:
class Token():
"""The node of a parse tree"""
LITERAL = 0
VARIABLE = 1
SECTION = 2
INVERTED = 3
COMMENT = 4
PARTIAL = 5
ROOT = 6
这 6 种类型中除了 ROOT,其余都对应了 Mustache 的一种类型,对应关系如下:
LITERAL:纯文本,即最终按原样输出的部分VARIABLE:变量字段,即 {{ name }} 类型SECTION:对应 {{#name}} ... {{/name}}INVERTED:对应 {{^name}} ... {{/name}}COMMENT:注释字段 {{! name }}PARTIAL:对应 {{> name}}
而最后的 ROOT 则代表整棵语法树的根节点。
了解了节点的类型,我们还需要知道每个节点需要保存什么样的信息,例如对于
Section 类型的节点,我们需要保存它对应的子节点,另外为了支持 lambda 类型的数据,我们还需要保存 section 段包含的文本。最终需要的字段如下:
def __init__(self, name, type=LITERAL, value=None, text='', children=None):
self.name = name
self.type = type
self.value = value
self.text = text
self.children = children
self.escape = False
self.delimiter = None # used for section
self.indent = 0 # used for partial
name:保存该节点的名字,例如 {{ header }} 是变量类型,name字段保存的就是header这个名字。type:保存前文介绍的节点的类型value:保存该节点的值,不同类型的节点保存的内容也不同,例如LITERAL类型保存的是字符串本身,而VARIABLE保存的是变量的名称,和name雷同。text:只对SECTION和INVERTED有用,即保存包含的文本children:SECTION、INVERTED及ROOT类型使用,保存子节点escape:输出是否要转义,例如 {{name}} 是默认转义的,而{{{name}}}默认不转义delimiter:与lambda的支持有关。Mustache 要求,若SECTION的变量是一个函数,则先调用该函数,返回时的文本用当前的分隔符解释,但在编译期间这些文本是不可获取的,因此需要事先存储。indent是PARTIAL类型使用,后面会提到。
可以看到,语法树的类型、结构和 Mustache 的语法息息相关,因此,要理解它的最好方式就是看 Mustache 的标准。 一开始写这个引擎时并不知道需要这么多的字段,在阅读标准时,随着对 Mustache 语法的理解而慢慢添加的。
所谓的虚拟机就是对编译器输出(我们的例子中是语法树)的解析,即给定语法树和数据,我们能正确地输出文本。首先我们为 Token 类定义一个调度函数:
class Token():
...
def render(self, contexts, partials={}):
if not isinstance(contexts, (list, tuple)): # ①
contexts = [contexts]
# ②
if self.type == self.LITERAL:
return self._render_literal(contexts, partials)
elif self.type == self.VARIABLE:
return self._render_variable(contexts, partials)
elif self.type == self.SECTION:
return self._render_section(contexts, partials)
elif self.type == self.INVERTED:
return self._render_inverted(contexts, partials)
elif self.type == self.COMMENT:
return self._render_comments(contexts, partials)
elif self.type == self.PARTIAL:
return self._render_partials(contexts, partials)
elif self.type == self.ROOT:
return self._render_children(contexts, partials)
else:
raise TypeError('Invalid Token Type')
①:我们要求上下文栈(context stack)是一个列表(或称数组),为了方便用户,我们允许它是其它类型的。
②的逻辑很简单,就是根据当前节点的类型执行不同的函数用来渲染(render)文本。
另外每个“渲染函数”都有两个参数,即上下文栈contexts 和 partials。
partials是一个字典类型。它的作用是当我们在模板中遇见如 {{> part}} 的标签中,就从 partials 中查找 part,并用得到的文本替换当前的标签。具体的使用方法可以参考 Mustache 文档
辅助渲染函数
它们是其它“子渲染函数”会用到的一些函数,首先是转义函数:
from html import escape as html_escape
EMPTYSTRING = ""
class Token():
...
def _escape(self, text):
ret = EMPTYSTRING if not text else str(text)
if self.escape:
return html_escape(ret)
else:
return ret
作用是如果当前节点需要转义,则调用 html_escape 进行转义,例如将文本 <b>
转义成 <b>。
另一个函数是查找(lookup),在给定的上下文栈中查找对应的变量。
class Token():
...
def _lookup(self, dot_name, contexts):
if dot_name == '.':
value = contexts[-1]
else:
names = dot_name.split('.')
value = lookup(names[0], contexts)
# support {{a.b.c.d.e}} like lookup
for name in names[1:]:
try:
value = value[name]
except:
# not found
break;
return value
这里有两点特殊的地方:
- 若变量名为
.,则返回当前上下文栈中栈顶的变量。这是 Mustache 的特殊语法。 - 支持诸如以
.号为分隔符的层级访问,如 {{a.b.c}} 代表首先查找变量a,在a的值中查找变量b,以此类推。
即 LITERAL 类型的节点,在渲染时直接输出节点保存的字符串即可:
def _render_literal(self, contexts, partials):
return self.value
子节点的渲染其实很简单,因为语法树是树状的结构,所以只要递归调用子节点的渲染函数就可以了,代码如下:
def _render_children(self, contexts, partials):
ret = []
for child in self.children:
ret.append(child.render(contexts, partials))
return EMPTYSTRING.join(ret)
即遇到诸如 {{name}}、{{{name}}} 或 {{&name}} 等的标签时,从上下文栈中查找相应的值即可:
def _render_variable(self, contexts, partials):
value = self._lookup(self.value, contexts)
# lambda
if callable(value):
value = render(str(value()), contexts, partials)
return self._escape(value)
这里的唯一不同是对 lambda 的支持,如果变量的值是一个可执行的函数,则需要先执行它,将返回的结果作为新的文本,重新渲染。这里的 render 函数后面会介绍。
contexts = [{ 'lambda': lambda : '{{value}}', 'value': 'world' }]
'hello {{lambda}}' => 'hello {{value}}' => 'hello world'
Section
Section 的渲染是最为复杂的一个,因为我们需要根据查找后的数据的类型做不同的处理。
def _render_section(self, contexts, partials):
val = self._lookup(self.value, contexts)
if not val:
# false value
return EMPTYSTRING
if isinstance(val, (list, tuple)):
if len(val) <= 0:
# empty lists
return EMPTYSTRING
# non-empty lists
ret = []
for item in val: #①
contexts.append(item)
ret.append(self._render_children(contexts, partials))
contexts.pop()
return self._escape(''.join(ret))
elif callable(val): #②
# lambdas
new_template = val(self.text)
value = render(new_template, contexts, partials, self.delimiter)
else:
# context ③
contexts.append(val)
value = self._render_children(contexts, partials)
contexts.pop()
return self._escape(value)
①:当数据的类型是列表时,我们逐个迭代,将元素入栈并渲染它的子节点。
②:当数据的类型是函数时,与处理变量时不同,Mustache 要求我们将 Section 中包含的文本作为参数,调用该函数,再对该函数返回的结果作为新的模板进行渲染。且要求使用当前的分隔符。
③:正常情况下,我们需要渲染 Section 包含的子节点。注意 self.text 与
self.children 的区别,前者是文本字符串,后者是编译后的语法树节点。
Inverted
Inverted Section 起到的作用是 if not,即只有当数据为假时才渲染它的子节点。
def _render_inverted(self, contexts, partials):
val = self._lookup(self.value, contexts)
if val:
return EMPTYSTRING
return self._render_children(contexts, partials)
直接跳过该子节点即可:
def _render_comments(self, contexts, partials):
return EMPTYSTRING
Partial
Partial 的作用相当于预先存储的模板。与其它模板语言的 include 类似,但还可以递归调用。例如:
partials: {'strong': '<strong>{{name}}</strong>'}
'hello {{> strong}}' => 'hello <strong>{{name}}</strong>'
代码如下:
re_insert_indent = re.compile(r'(^|\n)(?=.|\n)', re.DOTALL) #①
class Token():
...
def _render_partials(self, contexts, partials):
try:
partial = partials[self.value]
except KeyError as e:
return self._escape(EMPTYSTRING)
partial = re_insert_indent.sub(r'\1' + ' '*self.indent, partial) #②
return render(partial, contexts, partials, self.delimiter)
这里唯一值得一提的就是缩进问题②。Mustache 规定,如果一个 partial 标签是一个“单独行”,则需要将该标签的缩进添加到数据的所有行,然后再进行渲染。例如:
partials: {'content': '<li>\n {{name}}\n</li>\n'}
| |<ul>
|<ul> | <li>
| {{> content}} => | {{name}}
|</ul> | </li>
| |</ul>
因此我们用正则表达式对 partial 的数据进行处理。①中的正则表达式,(^|\n) 用于匹配文本的开始,或换行符之后。而由于我们不匹配最后一个换行符,所以我们用了
(?=.|\n)。它要求,以任意字符结尾,而由于 . 并不匹配换行符 \n,因此用了或操作(|)。
虚拟机小结
综上,我们就完成了执行语法树的虚拟机。是不是还挺简单的。的确,一旦决定好了数据结构,其它的实现似乎也只是按部就班。
最后额外指出一个问题,那就是编译器与解释器的问题。传统上,解释器是指一句一句读取源代码并执行;而编译器是读取全部源码并编译,生成目标代码后一次性去执行。
在我们的模板引擎中,语法树是属于编译得到的结果,因为模板是固定的,因此能得到一个固定的语法树,语法树可以重复执行,这也有利于提高效率。但由于 Mustache 支持
partial 及 lambda,这些机制使得用户能动态地为模板添加新的内容,所以固定的语法树是不够的,因此我们在渲染时用到了全局 render 函数。它的作用就相当于解释器,让我们能动态地渲染模板(本质上依旧是编译成语法树再执行)。
有了这个虚拟机(带执行功能的语法树),我们就能正常渲染模板了,那么接下来就是如何把模板编译成语法树了。
Mustache 的词法较为简单,并且要求能动态改变分隔符,所以我们用正则表达式来一个个匹配。
Mustache 标签由左右分隔符包围,默认的左右分隔符分别是 { {(忽略中间的空格) 和 }}:
DEFAULT_DELIMITERS = ('{{', '}}')
而标签的模式是:左分隔符 + 类型字符 + 标签名 + (可选字符)+ 右分隔符,例如:
{{# name}} 和 {{{name}}}。其中 `#` 就代表类型,{{{name}}} 中的`}` 就是可选的字符。re_tag = re.compile(open_tag + r'([#^>&{/!=]?)\s*(.*?)\s*([}=]?)' + close_tag, re.DOTALL)
In [6]: re_tag = re.compile(r'{{([#^>&{/!=]?)\s*(.*?)\s*([}=]?)}}', re.DOTALL)
In [7]: re_tag.search('before {{# name }} after').groups()
Out[7]: ('#', 'name', '')
这样通过这个正则表达式就能得到我们需要的类型和标签名信息了。
只是,由于 Mustache 支持修改分隔符,而正则表达式的 compile 过程也是挺花时间的,因此我们要做一些缓存的操作来提高效率。
re_delimiters = {}
def delimiters_to_re(delimiters):
# caching
delimiters = tuple(delimiters)
if delimiters in re_delimiters:
re_tag = re_delimiters[delimiters]
else:
open_tag, close_tag = delimiters
# escape ①
open_tag = ''.join([c if c.isalnum() else '\\' + c for c in open_tag])
close_tag = ''.join([c if c.isalnum() else '\\' + c for c in close_tag])
re_tag = re.compile(open_tag + r'([#^>&{/!=]?)\s*(.*?)\s*([}=]?)' + close_tag, re.DOTALL)
re_delimiters[delimiters] = re_tag
return re_tag
①:这是比较神奇的一步,主要是有一些字符的组合在正则表达式里是有特殊含义的,为了避免它们影响了正则表达式,我们将除了字母和数字的字符进行转义,如 '[' => '\['。
现在的任务是把模板转换成语法树,首先来看看整个转换的框架:
def compiled(template, delimiters=DEFAULT_DELIMITERS):
re_tag = delimiters_to_re(delimiters)
# variable to save states ①
tokens = []
index = 0
sections = []
tokens_stack = []
m = re_tag.search(template, index)
while m is not None:
token = None
last_literal = None
strip_space = False
if m.start() > index: #②
last_literal = Token('str', Token.LITERAL, template[index:m.start()])
tokens.append(last_literal)
prefix, name, suffix = m.groups()
# >>> TODO: convert information to AST
if token is not None: #③
tokens.append(token)
index = m.end()
if strip_space: #④
pos = is_standalone(template, m.start(), m.end())
if pos:
index = pos[1]
if last_literal: last_literal.value = last_literal.value.rstrip(spaces_not_newline)
m = re_tag.search(template, index)
tokens.append(Token('str', Token.LITERAL, template[index:]))
return Token('root', Token.ROOT, children=tokens)
可以看到,整个步骤是由一个 while 循环构成,循环不断寻找下一个 Mustache 标签。这意味着我的解析是线性的,但我们的目标是生成树状结构,这怎么办呢?答案是①中,我们维护了两个栈,一个是 sections,另一个是 tokens_stack。至于怎么使用,下文会提到。
②:由于每次 while 循环时,我们跳过了中间那些不是标签的字面最,所以我们要将它们进行添加。这里将该节点保存在 last_literal 中是为了处理“单独行的情形”,详情见下文。
③:正常情况下,在循环末我们会将生成的节点(token)添加到 tokens 中,而有些情况下我们希望跳过这个逻辑,此时将 token 设置成 None。
④:strip_space 代表该标签需要考虑“单独行”的情形,此时做出相应的处理,一方面将上一个字面量节点的末尾空格消除,另一方面将 index 后移至换行符。
分隔符的修改
唯一要注意的是 Mustache 规定分隔符的修改是需要考虑“单独行”的情形的。
if prefix == '=' and suffix == '=':
# {{=| |=}} to change delimiters
delimiters = re.split(r'\s+', name)
if len(delimiters) != 2:
raise SyntaxError('Invalid new delimiter definition: ' + m.group())
re_tag = delimiters_to_re(delimiters)
strip_space = True
在解析变量时要考虑该变量是否需要转义,并做对应的设置。另外,末尾的可选字符
(suffix) 只能是 } 或 =,分别都判断过了,所以此外的情形都是语法错误。
elif prefix == '{' and suffix == '}':
# {{{ variable }}}
token = Token(name, Token.VARIABLE, name)
elif prefix == '' and suffix == '':
# {{ name }}
token = Token(name, Token.VARIABLE, name)
token.escape = True
elif suffix != '' and suffix != None:
raise SyntaxError('Invalid token: ' + m.group())
elif prefix == '&':
# {{& escaped variable }}
token = Token(name, Token.VARIABLE, name)
注释是需要考虑“单独行”的。
elif prefix == '!':
# {{! comment }}
token = Token(name, Token.COMMENT)
if len(sections) <= 0:
# considered as standalone only outside sections
strip_space = True
Partial
一如既往,需要考虑“单独行”,不同的是还需要保存单独行的缩进。
elif prefix == '>':
# {{> partial}}
token = Token(name, Token.PARTIAL, name)
strip_space = True
pos = is_standalone(template, m.start(), m.end())
if pos:
token.indent = len(template[pos[0]:m.start()])
Section & Inverted
这是唯一需要使用到栈的两个标签,原理是选通过入栈记录这是 Section 或 Inverted 的开始标签,遇到结束标签时再出栈即可。
由于事先将 tokens 保存起来,因此遇到结束标签时,tokens 中保存的就是当前标签的所有子节点。
elif prefix == '#' or prefix == '^':
# {{# section }} or # {{^ inverted }}
token = Token(name, Token.SECTION if prefix == '#' else Token.INVERTED, name)
token.delimiter = delimiters
tokens.append(token)
# save the tokens onto stack
token = None
tokens_stack.append(tokens)
tokens = []
sections.append((name, prefix, m.end()))
strip_space = True
当遇到结束标签时,我们需要进行对应的出栈操作。无它。
elif prefix == '/':
tag_name, sec_type, text_end = sections.pop()
if tag_name != name:
raise SyntaxError("unclosed tag: '" + name + "' Got:" + m.group())
children = tokens
tokens = tokens_stack.pop()
tokens[-1].text = template[text_end:m.start()]
tokens[-1].children = children
strip_space = True
else:
raise SyntaxError('Unknown tag: ' + m.group())
语法分析小结
同样,语法分析的内容也是按部就班,也许最难的地方就在于构思这个 while 循环。所以要传下教:思考问题的时候要先把握整体的内容,即要自上而下地思考,实际编码的时候可以从两边同时进行。
最后我们再实现 render 函数,用来实际执行模板的渲染。
class SyntaxError(Exception):
pass
def render(template, contexts, partials={}, delimiters=None):
if not isinstance(contexts, (list, tuple)):
contexts = [contexts]
if not isinstance(partials, dict):
raise TypeError('partials should be dict, but got ' + type(partials))
delimiters = DEFAULT_DELIMITERS if delimiters is None else delimiters
parent_token = compiled(template, delimiters)
return parent_token.render(contexts, partials)
这是一个使用我们模板引擎的例子:
>>> render('Hellow {{name}}!', {'name': 'World'})
'Hellow World!'
综上,我们完成了一个完整的 mustache 模板引擎,完整的代码可以在 Github: pymustache 上下载。
实际测试了一下,我们的实现比 pystache 还更快,代码也更简单,去掉注释估计也就 300 行左右。
无论如何吧,我就想打个鸡血:如果真正去做了,有些事情并没有看起来那么难。如果本文能对你有所启发,那就是对我最大的鼓励。
Recommend
-
54
README.md Emacs Major Mode for Handlebars Based on mustache-mode https://github.com/mustache/emacs...
-
49
README.md Mustache.php A Mustache implementation in PHP.
-
6
Meet Barber💈: the best way to manage your Mustache Cash App clients and services render thousands of English Mustache templates to send millions of personalized notifications, emails, text messages, and in-app UI daily to our cust...
-
6
No more pink mustache As I write this, I'm in the final couple of days of what seems like the longest year in my career to date. While it was just a hair over 365 days, it seems like it went on forever. Living though this thing...
-
10
How can I force Jade to wear a mustache? advertisements This is my jade figurine: section#entry-...
-
12
mustache and handlebars mode for vim A vim plugin for working with mustache and handlebars templates. It has: syntax highlighting ma...
-
5
Vue 源码之 mustache 模板引擎(一)个人练习结果仓库(持续更新):Vue 源码解析 抽空把之前学的东西写成笔记。 学习视频链接:
-
5
Vue源码之mustache模板引擎(二) 手写实现mustache mustache.js 个人练习结果仓库(持续更新):
-
7
Stubble Trimmed down {{mustache}} t...
-
6
Cljstache {{ mustache }} templates for Clojure[Script]. Compliant with the Mustache spec, including lambdas (jvm only) Forked from...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK